







用户行为序列 = lastN(用户最近交互过的 N 个物品)
用户特征中的 last N特征很有效,加入召回和排序中所有指标都会大涨。
用户 lastn行为序列可以反应出用户对什么物品感兴趣
行为序列01-用户历史行为序列建模
用户最近 n 次点击、点赞、收藏、转发等行为都是推荐系统中重要的特征,可以帮助召回和排序变得更精准。这节课介绍最简单的方法——对用户行为取简单的平均,作为特征输入召回、排序模型。
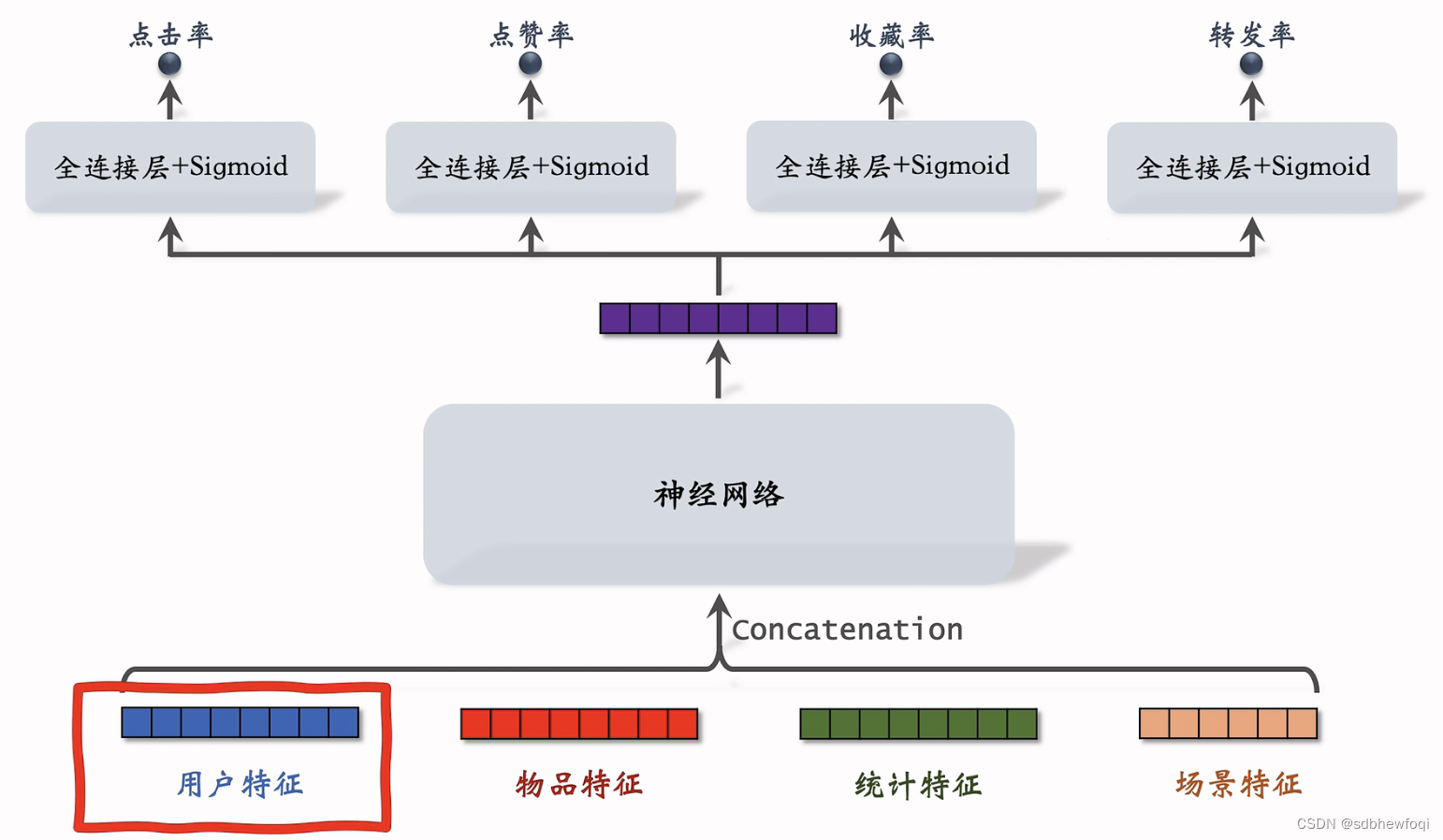
召回的双塔模型,粗排三塔,精排模型都可以用 lastn 特征。
这是前面课程介绍的多目标排序模型,模型任务是预估点击率,点赞率等指标。根据指标对物品进行排序,选择出用户最感兴趣的物品。
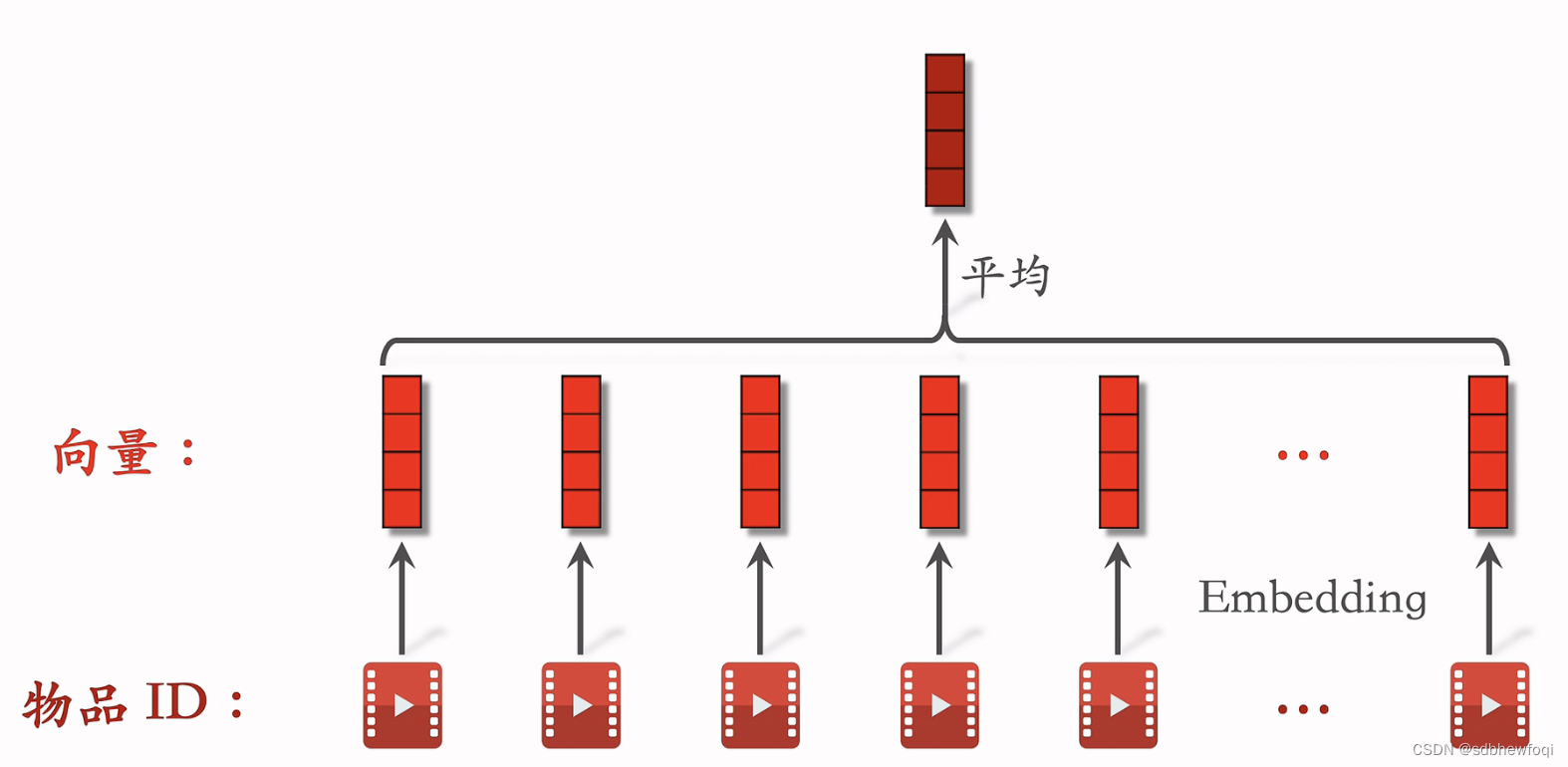
用户 last N记录用户最近交互过的n个物品 id。做 emb,将 n 个物品 id map 为n 个向量。对向量取平均得到1个向量,表示用户曾经对什么样的物品感兴趣。

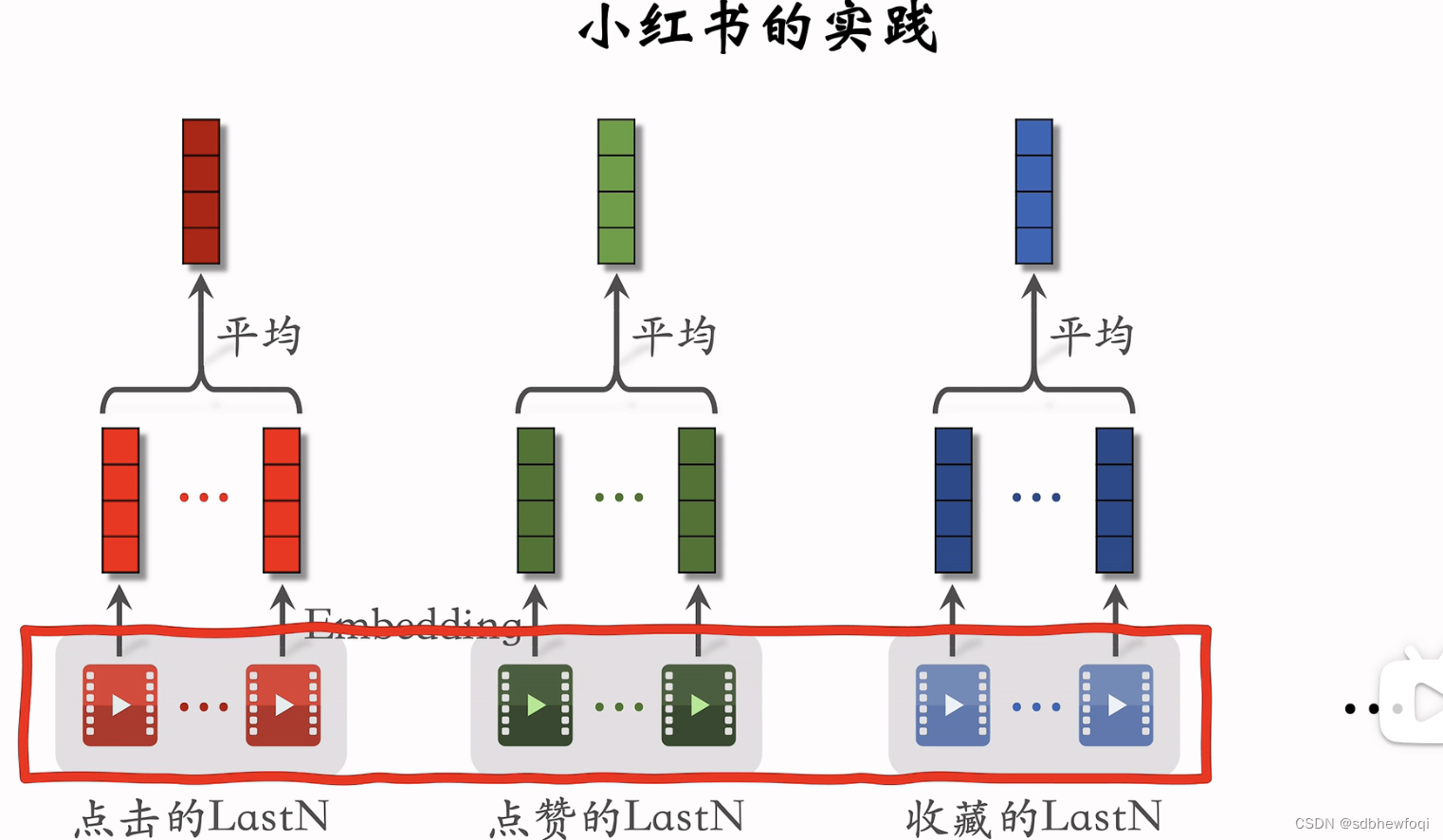
小红书的召回,粗排,精排都用了 lastn。
用户最近点击的 n 个物品,求emb的平均( 效果更好的是att,但是计算量更大)。类似的行为同样记录lastn物品 id。把不同行为的 last n emb concat。还可以使用物品其他特征,比如物品类目。把 id emb和其他特征的 emb 拼在一起,比只用id emb效果更好。
00:11-00:20 (3,8)
行为序列02-DIN模型(注意力机制)
上节课介绍了用户的 LastN 序列特征。这节课介绍 DIN 模型,它是对 LastN 序列建模的一种方法,效果优于简单的平均。DIN 的本质是注意力机制(attention)。
DIN 是阿里在 2018 年提出的,有兴趣的话可以阅读下面的参考文献。 参考文献: Zhou et al. Deep interest network for click-through rate prediction. In KDD, 2018.,
只能用与精排模型。
用户最近交互过的 n 个物品,取平均作为对用户行为的表征。

哪个 lastn 物品有候选物品更相似,它的权重越高。
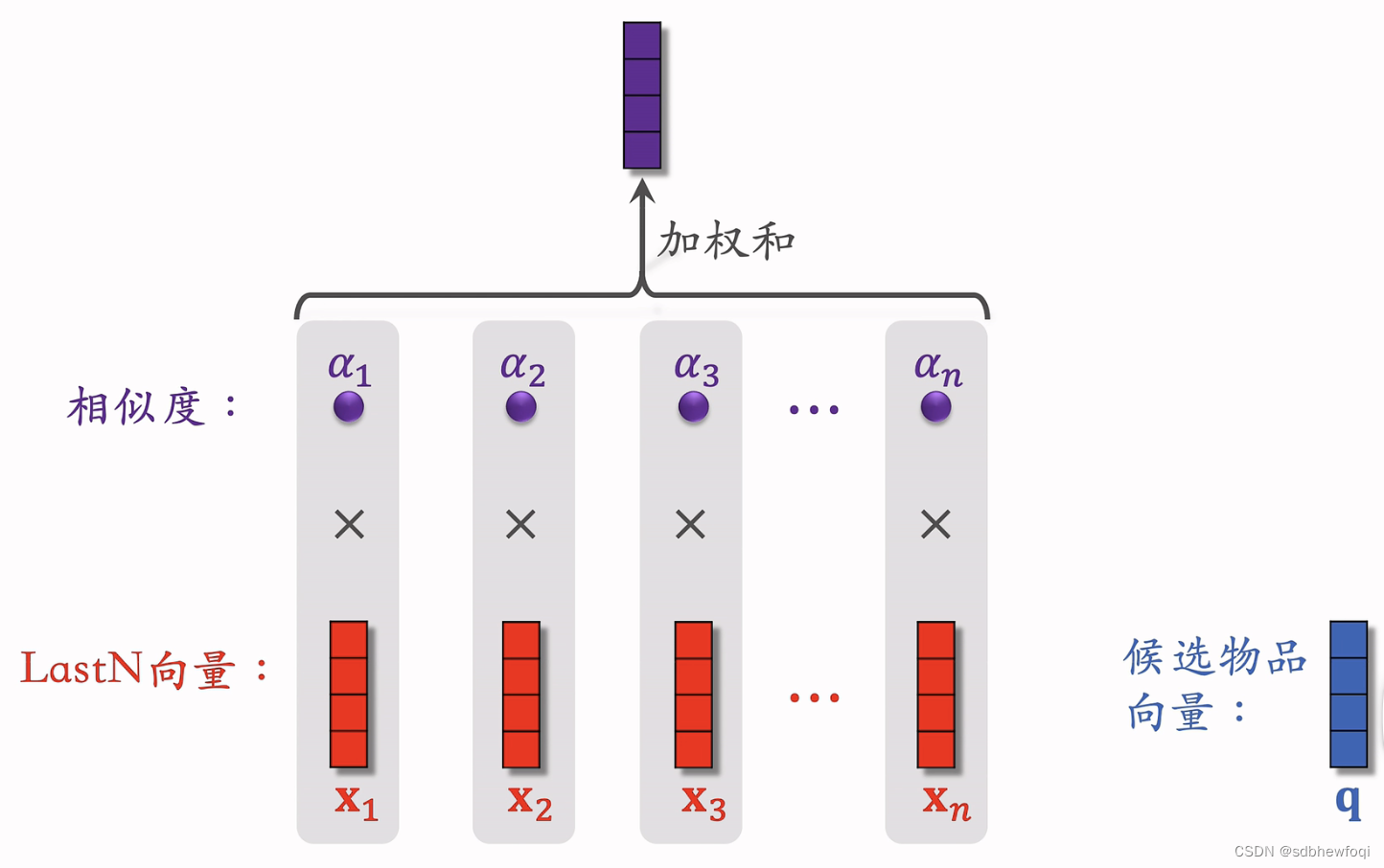
a1是实数,计算相似度可以用内积,也可以用cos。
候选物品和lastn 逐个计算相似度。每个 a对应一个 x 向量。a 与对应的向量进行相乘,然后结果相加,紫色向量就是 lastn 向量的加权和,权重是相似度 a。


query只有一个向量,所以注意力机制的输出也是一个向量。

在双塔召回的时候,一共有上亿个候选物品,用户塔只能看到用户特征。但 din需要知道候选物品的特征。
00:20-00:32 (4,12)
行为序列02:DIN模型(注意力机制)_哔哩哔哩_bilibili
行为序列01-SIM(长序列建模)
这节课继续讲解推荐系统中的用户行为序列建模。这节课介绍 SIM 模型,它的主要目的是保留用户的长期兴趣。SIM 的原理是对用户行为序列做快速筛选,缩短序列长度,使得DIN可以用于长序列。
参考文献: Qi et al. Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. In CIKM, 2020.
SIM目的保留用户的长期兴趣,是有效的。
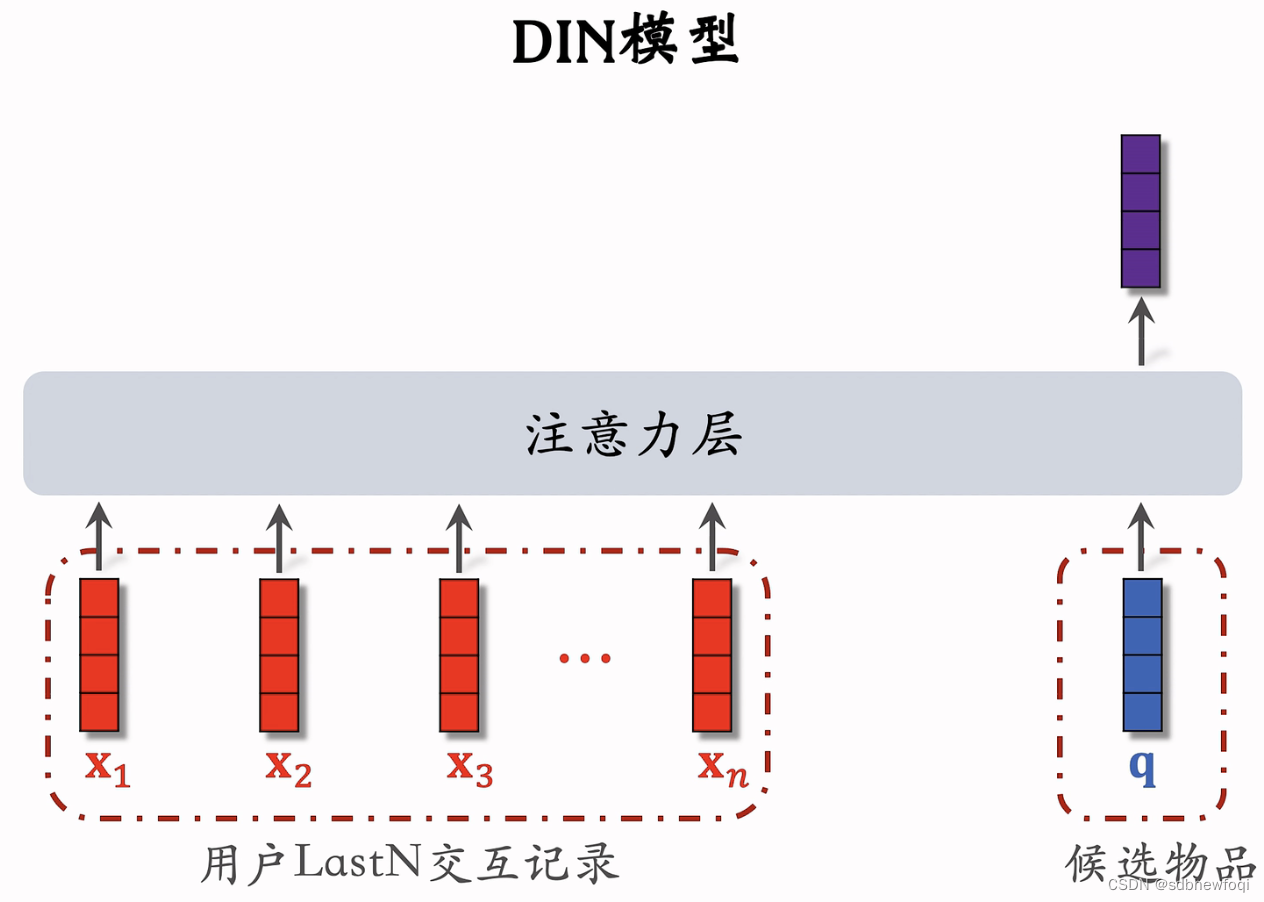
紫色向量可以看作是用户 lastn历史记录的表征,反应出用户兴趣。

n 越大,din的计算量就越大,记录的用户行为序列太短。记录的行为序列变长可以显著的提升推荐系统的所有指标。但暴力增加序列长度是不划算的,增加的计算量太大,但是带来的收益却不多,性价比不高。
目标:n 尽量大,推荐更精准。

比如候选物品是关于美食的笔记,lastn 是美妆的,两者显然不相似,权重接近为0。如果把不相关的笔记从 lastn中排除掉,几乎不会影响 din加权平均的结果。
只把相关物品输入注意力层,可以大幅降低注意力层的计算量。

如果不用 sim,n 的大小一般100-200。
k是比较小的数,比如 k=100。记录用户最近交互过的1000个物品 id,n=1000, 根据候选物品的类目快速排除大部分lastn物品,只保留最相关的100个。把1000个变成100个。
k 较小,注意力层的计算量也较小。
sim分为2步,第一步是查找,第二步是注意力机制。

hard search 根据规则做筛选。用规则做筛选的速度非常快。
soft search,向量最近邻查找。需要把 lastn物品和候选物品 query都做 emb。效果更好,用于预估点击率等业务指标的话,auc 更高。
需要根据公司基建,除非基建牛逼,否则 hard search 就可以了
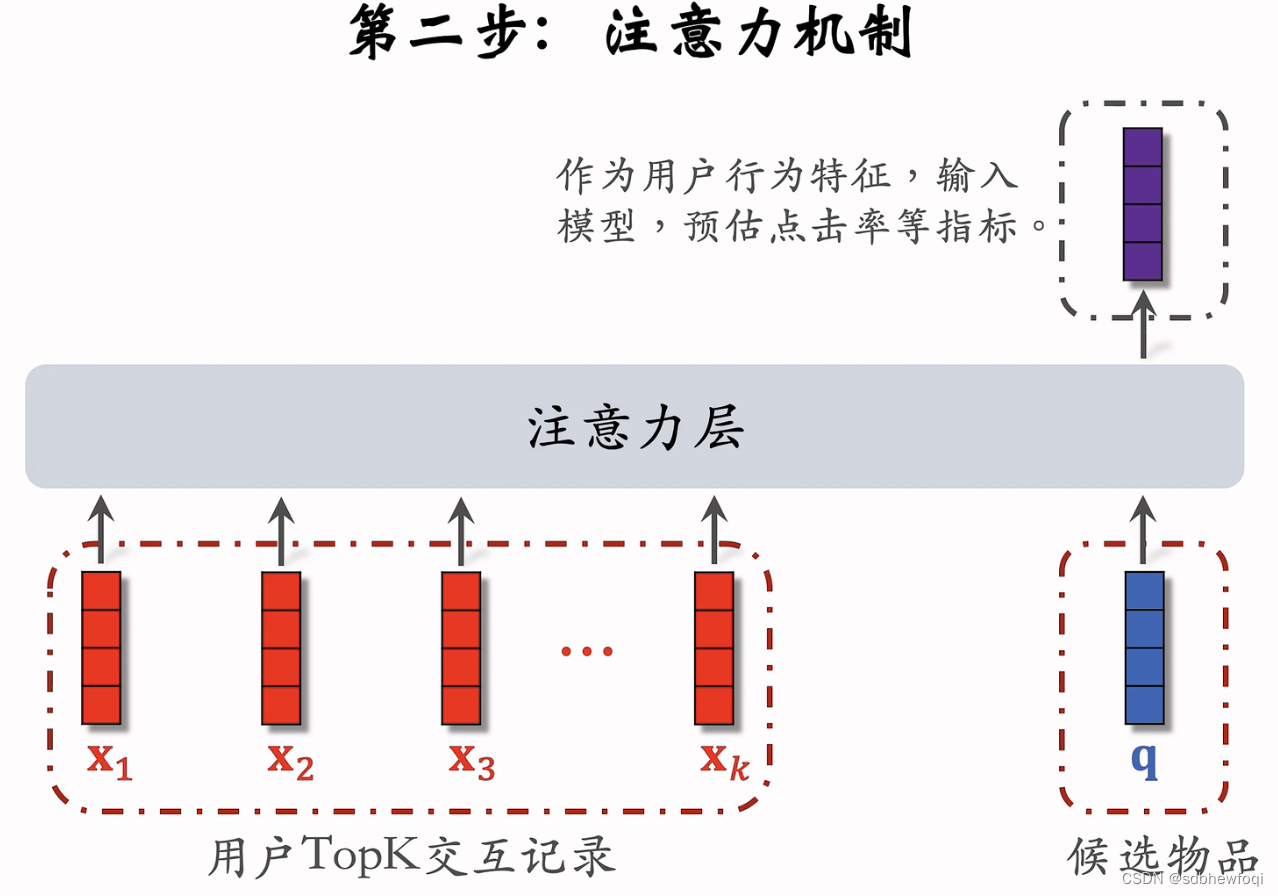
lastn为 topk,几乎不会影响加权平均的结果,紫色向量几乎不变。被排除物品的权重本身就接近与0。

小trick:记录用户与物品交互发生的时刻。 比如发生在1000h 之前,delta=1000。delta是连续值,需要对它做离散化,划分成很多区间,比如发生在最近1天,7天,30天,1年,1年以上。
现在每个 lastn 物品有两个向量。两个向量 concat,拼成一个向量,作为一个 lastn物品的表征。
候选物品 q 不需要对它的时间做 emb。
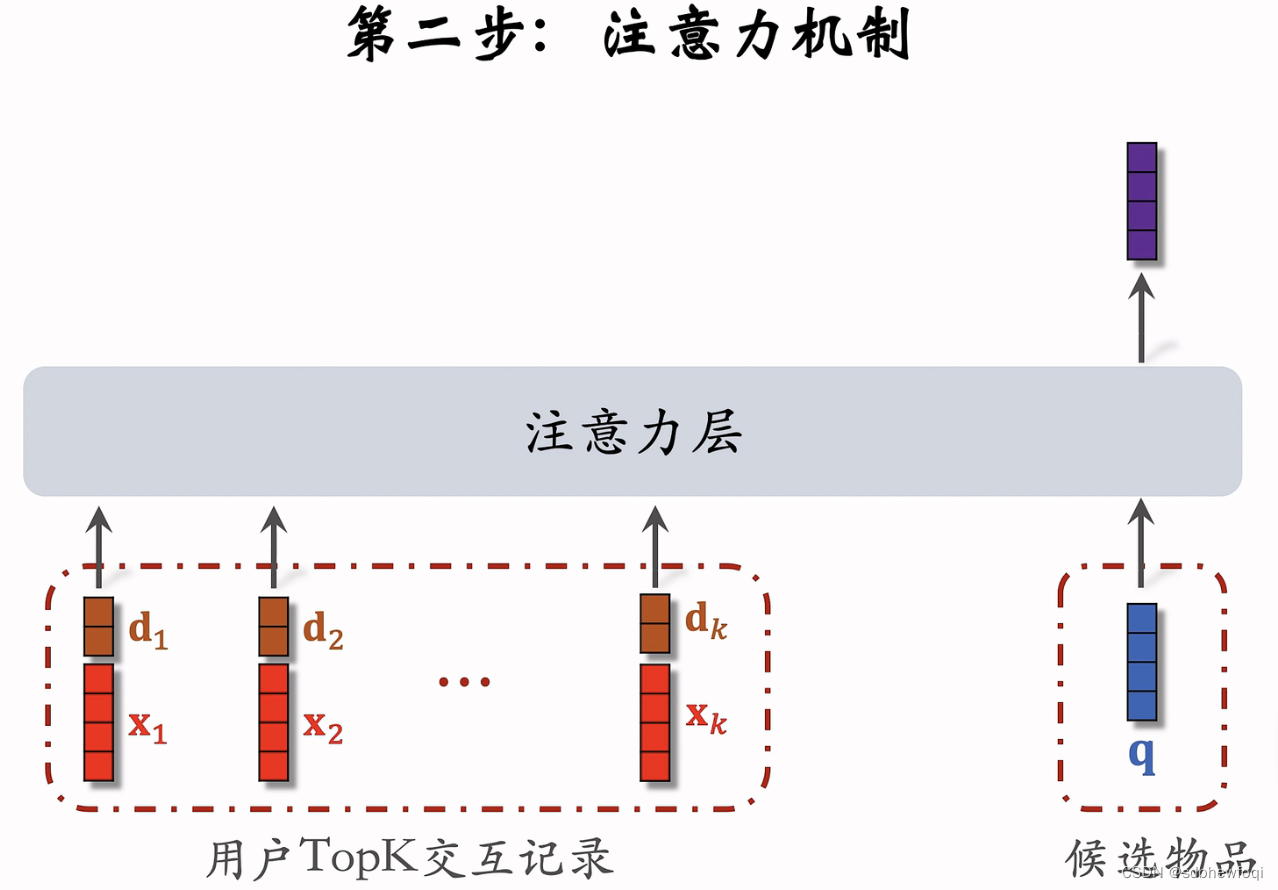
一个紫色向量为对用户兴趣的表征。

din无需考虑时间,只记录用户近期交互100-200的物品。
sim的 lastn中可能有用户1年前的交互,也可能是10分钟前的交互,重要性不一样。

行为序列03:SIM模型(长序列建模)_哔哩哔哩_bilibili
00:32-00:58(9,26)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









