






在前几篇中我们主要介绍了ArrayList、LinkedList、Vector、Stack等集合的底层实现及相关特性,并且我们知道在上述集合类中无论底层是采用数组实现的还是采用双链表实现的,它们都有各自的缺点。例如底层用数组实现的集合它的特性是检索速度非常快,但如果要删除中间的元素时,性能会比较低。而底层用双链表实现的集合的特性是删除元素的速度非常快,但检索元素的速度较慢。那么这时就会有人想,在Java中有没有一种集合,即检索元素的速度快,删除元素的速度也快呢?
答案一定是有的,因为你能想到,那么创造Java的大师们早就想到了,于是HashMap集合诞生了,既然HashMap集合的出现是为了解决底层数组和双链表的缺点,那么可想而知HashMap集合底层一定不是采用数组或双链表实现的,实际上HashMap集合是采用了一种全新的数据结构来实现的叫做散列表。下面我们来了解一下什么是散列表,并重点分析一下底层是怎么解决数组和双链表的缺点的。
散列表为每个对象的实例都计算了一个整数值,称之为散列码,也就是我们常常所说的hash code。Java中的散列表主要是用数组和链表实现的,每个列表都被称为桶。为了提高元素的检索速度,在散列表中要想查找元素在散列表中的位置,必须要先计算出当前对象的散列码才可以。那么在散列表的底层到底是怎么通过散列码计算出元素的位置的呢?
答案是:散列码余桶的个数。也就是说在散列表的底层是通过当前对象的散列码除以当前散列表的樋数,然后剩余的余数,就是当前对象在散列表中桶的位置。例如。有一个对象的散列码为76268,并且假如当前散列表中一共有128个桶,那么如果用散列表来存储过象的话,当前对象就会被保存到第108号的桶中,因为76268除以128余108。但这只是在理想的的情况下,但在实际的存储过程中可以会遇到当前散列表中的桶中已经保存了其他元素了(当对象的散列码相同时,就会遇到上述情况)。 这时就会造成冲突。
在Java中这种冲突就叫做散列冲突。如果发生这种现象时,散列表就会用当前对象与桶中的对象进行比较(调用对象的equals方法比较),来检查当前对象是否已经在桶中存在了。如果当前对象没有在桶中存在,则会把当前对象直接存储在桶的起始位置。如果发生了散列冲突,也就是当前桶中已经存储了元素,则底层会循环遍历这个链表找到链表中的最后一个元素,然后创建一个新节点保存数据并将最后一个元素的后继节点设置为刚刚新创建的节点。这样新创建的节点就成为了这个链表中的最后一个节点了(链表中的特性)。所以在HashMap底层存储的数据方式可能是下面这样的。如下图所示:
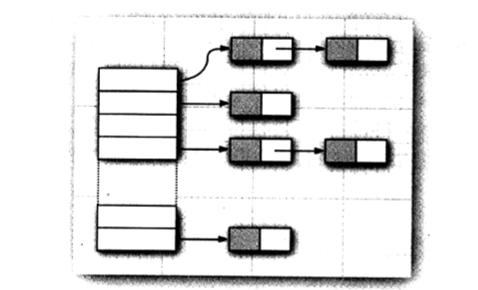
所以我们在日常开发时,为了提高HashMap的运行效率,要尽量的必免发生散列冲突的现象。解决的办法就是增加HashMap中桶的数量,在Java中HashMap的默认桶的数量为16,也就是底层数组的大小为16。如果我们设置的桶的数量不够存储元素时,散列表就会执行再散列。再散列的意思是说创建一个更多桶的新的散列表,然后将原散列表中的数据插入到这个新的散列表中。
在HashMap中实际上并不是在散列表中已经满了的情况下才进行再散列的,而是有一个加载因子来决定什么时候进行再散列的。在HashMap中默认的加载因子的值为0.75。它的意思是说,如果散列表中有75%的桶中都存储了元素,那么散列表就会进行再散列,并且散列后的桶数为原来桶数的两倍。
下面我们通过HashMap的源码来分析HashMap底层散列表的具体的实现。我们还是和其它集合一样,先来看一下HashMap的实例化。

上面代码为无参的HashMap构造方法,构造方法中设置了当前HashMap的加载因子为默认值也就是0.75。也可以自行修改此默认值,在HashMap中提供了修改此参数的构造方法。并且我们发现此时底层的数组或者链表并没有执行初始化。下面我们看HashMap的put方法的底层实现,put方法是HashMap中最重要的方法,几乎涉及到HashMap中的所有的知识点。如底层的初始化、再散列、散列冲突等。





- 总结
- 通过上面的介绍及底层源码的分析,使我们知道在最新版的JDK1.8中HashMap底层采用的是数组+链表+二叉树(红黑树)来实现的。
- 我们使用HashMap时,是可以将null作为key使用的。
- 如果我们保存元素时,元素的key相同,则底层会直接把后调用put方法的value覆盖前一次put的value。
- 我们发现在HashMap源码中并没有发现同步关键字synchronized,这就说明,HashMap并不是线程安全的集合类,所以在使用时,要特别注意
下面我们回到文章开头所说的问题,在HashMap是怎么解决数组和双链表的性能问题的呢?
我们知道如果要在HashMap中查找一个元素,那么首先就会计算这个key的hash code。然后我们就会得知,这个元素在数组中的一个桶的位置。因为我们在之前的文章中已经介绍过了,数组的检索速度是非常快的,所以执行上述操作时,性能是很高的。我们假设要检索的元素在这个桶的第5个链表的位置,这时,我们只要直接遍历这个桶的链表就可以了,而不是向LinkedList集合那样需要遍历整个链表,所以在HashMap中查找元素和删除的元素的性能要比ArrayList和LinkedList集合的性能要高。那么在HashMap集合中就一点缺点都没有吗?
这也不是绝对的。因为我们知道每一个元素都会计算hash code。存储的时候是通过hash code的值来决定存储到数组中的哪个位置的,所以在存储时,并一定按照我们添加元素的顺序存储的,也就是put元素的顺序。所以在HashMap集合中,是不保证元素的存储顺序的。所以在日常的开发中,我们要根据不同的业务采用不同的集合来实现具体的业务。















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









