






2023 oneAPI&OpenVINO联合黑客松

 本次oneAPI&OpenVINO联合黑客松,我选择了赛道一基于英特尔®oneAPI的开放创新。实现一个X光违禁物成像分析的案例
本次oneAPI&OpenVINO联合黑客松,我选择了赛道一基于英特尔®oneAPI的开放创新。实现一个X光违禁物成像分析的案例
痛点分析
X光安检机是目前我国使用最广泛的安检技术手段,广泛应用于城市轨交、铁路、机场、重点场馆、物流寄递等场景。使用人工智能技术,辅助一线安检员进行X光安检判图,可以有效降低因为人员疲劳或注意力不集中带来的漏报等问题。但在实际场景中,因物品的多样性、成像角度、遮挡等问题,为算法的开发带来了一定的挑战。
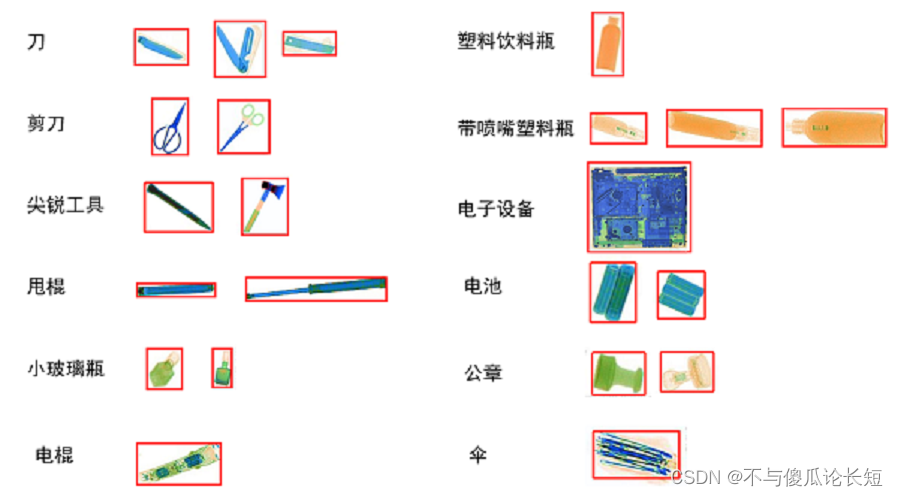
目前高准确率的图像识别多用卷积神经网络实现,但是当前基于卷积神经网络训练的模型有一定局限性,违禁品多种多样,场景也复杂多变,这就需要设计的卷积神经网络模型的层数要足够多,训练集样本数要足够大,才能保证准确率。
为了解决上述问题,提出了一种基于intel Ai-analytics-toolkit 对于违禁品实现通用识别及分析。
设计思路
整体思路,依旧是联合识别,但是对于数据的处理,和步骤过程的细节做了优化
- 准备数据集:准备包含违禁物品和正常物品图像的数据集,并标记每张图像中违禁物品的位置和类别。同时对于数据集做预处理及数据填充。
- 构建形状模型:使用intel_extension_for_pytorch 搭建一个形状模型,如卷积神经网络(CNN),用于对违禁物品进行分类。我们可以使用预训练的模型,如ResNet等,并进行微调以适应我们的数据集。
- 构建颜色模型:使用intel_extension_for_pytorch 搭建一个颜色模型,如全连接神经网络,用于对图像颜色信息进行分类。我们可以使用预训练的模型,如VGG等,并进行微调以适应我们的数据集。
- 数据处理与输入:对形状模型输出的数据进行处理,提取出违禁物品的位置和类别信息,并将其输入到颜色模型中进行分类。
- 联合识别:将形状模型输出的数据和颜色模型输出的数据进行计算,通过融合两个模型的结果,得出哪些区域是何种违禁品的概率。
- 训练和测试:使用准备好的数据集对模型进行训练和测试,评估模型的性能指标,如准确率、召回率等。
方案实现
intel ai-analytics-toolkit 环境搭建
本次我们使用conda*-based作为基本环境
source <conda PATH>/bin/activate
conda update -n base conda
conda config --set solver libmamba
conda config --show
Intel® Extension for Pytorch
Intel® Extension for PyTorch”是基于PyTorch的扩展项目,由英特尔发起并开发,旨在通过提供额外的软件优化来充分发挥英特尔硬件的性能。
这个扩展项目主要针对命令式(imperative)和图模式(graph-based)的PyTorch使用场景进行优化,并针对PyTorch的三个关键模块进行优化:运算符、图和运行时。优化的运算符和内核通过PyTorch调度机制完成调用。使用这个扩展,用户可以在英特尔平台上更有效地进行深度学习推理和训练。
数据集准备:

准备一个包含多种违禁物品和正常物品的图像数据集。数据集中的每张图像都标记了违禁物品的位置和类别。
图像文件采用jpg格式,标注文件采用xml格式,各字段含义对应表为:
├── filename 文件名
├── size 图像尺寸
├── width 图像宽度
├── height 图像高度
└── depth 图像深度,一般为3表示是彩色图像
└── object 图像中的目标,可能有多个
├── name 该目标的标签名称
└── bndbox 该目标的标注框
├── xmin 该目标的左上角宽度方向坐标
├── ymin 该目标的左上角高度方向坐标
├── xmax 该目标的右下角宽度方向坐标
└── ymax 该目标的右下角高度方向坐标
对于数据集进行预处理,并且划分一部分用于测试。
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
dataset = datasets.ImageFolder(root='data/train', transform=transform)
# 划分数据集,80%用于训练,20%用于测试
train_size = int(0.8 * len(dataset))
test_size = len(dataset ) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
# 重新创建数据加载器以使用新的训练集和测试集
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
检测数据分析
该数据集总共包含 9 个标签,各类标签的数量分别为:
这里我们也可以主要选取两到三个作为测试
- pressure: 240
- glassbottle: 3069
- laptop: 366
- umbrella: 1265
- lighter: 429
- knife: 722
- tongs: 361
- scissor: 441
- metalcup: 251
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
dict = {} # 新建字典,用于存放各类标签名及其对应的数目
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
# 遍历文件的所有标签
for obj in root.iter('object'):
name = obj.find('name').text
if(name in dict.keys()): dict[name] += 1 # 如果标签不是第一次出现,则+1
else: dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1
# 打印结果
print("各类标签的数量分别为:")
for key in dict.keys():
print(key + ': ' + str(dict[key]))
图像尺寸分析
通过图像尺寸分析,我们可以看到该数据集图片的尺寸不一。
可以进行预处理或者后续对于识别加入相关优化。
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import glob
def Image_size(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
width_heights = []
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text)
if [width, height] not in width_heights: width_heights.append([width, height])
print("数据集中,有{}种不同的尺寸,分别是:".format(len(width_heights)))
for item in width_heights:
print(item)
构建形状模型:
使用Intel® Extension for Pytorch 搭建一个简单的卷积神经网络(CNN),用于对违禁物品进行分类。我们使用ResNet18进行微调以适应我们的数据集。
# 构建卷积神经网络结构
def build_resnet18():
model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 1024, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(1024 * 8 * 8, 512),
nn.ReLU(inplace=True),
nn.Linear(512, 3)
)
return model
这个网络结构包括了多个卷积层、批归一化层、激活层、池化层和全连接层。我们使用了PyTorch内置的ResNet模块来构建这个网络结构,通过调用nn.Sequential将各个层顺序连接起来。
构建颜色模型:
使用Intel® Extension for Pytorch 搭建一个全连接神经网络,用于对图像颜色信息进行分类。我们可以使用VGG16等进行微调
归一化处理
# 读取数据并进行Z-score归一化处理
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
BatchNorm替换
# 使用Intel Extension for PyTorch的BatchNorm替换普通BatchNorm
# model = nn.Sequential(
# nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
# BatchNorm(32), # 使用Intel Extension for PyTorch的BatchNorm层
# nn.ReLU(),
# nn.MaxPool2d(kernel_size=2, stride=2),
# nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
# BatchNorm(64), # 使用Intel Extension for PyTorch的BatchNorm层
# nn.ReLU(),
# nn.MaxPool2d(kernel_size=2, stride=2),
# nn.Flatten(),
# nn.Linear(64 * 8 * 8, 128),
# nn.ReLU(),
# nn.Linear(128, 2) # 假设有2个类别的违禁物品
# )
在模型微调过程中,我们读取数据并进行Z-score归一化处理:从数据集中读取图像数据,并使用Z-score归一化方法将每个通道的数据缩放到均值为0,标准差为1的范围内。
使用训练集对模型进行训练,并使用验证集进行调优。在每个epoch结束时,计算验证集的准确率和损失,以便调整模型参数。最后在验证集上使用不同的K值进行测试,选择具有最高准确率的K值。
联合识别:
将形状模型输出的数据和颜色模型输出的数据进行计算,通过融合两个模型的结果,得出哪些区域是何种违禁品的概率。
def demo(image, shape_output, color_output):
# 对形状模型输出的数据进行处理,提取违禁物品的位置和类别信息
_, shape_predictions = torch.max(shape_output, dim=1)
shape_probabilities = torch.softmax(shape_output, dim=1)[0, shape_predictions]
shape_label = train_dataset.classes[shape_predictions]
shape_bbox = None # 可以根据需求提取违禁物品的边界框信息
if shape_predictions == 0: # 假设第一个类别为违禁物品类别
shape_bbox = get_bbox(image, shape_output) # 假设有一个函数可以提取违禁物品的边界框信息
return shape_label, shape_bbox, shape_probabilities, color_output
......
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
# 前向传播
outputs_shape = model_shape(inputs)
outputs_color = model_color(inputs)
# 联合识别
shape_label, shape_bbox, shape_probabilities, color_output =demo(inputs, outputs_shape, outputs_color)
# 计算损失
loss = criterion(shape_probabilities, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1} loss: {running_loss/len(train_loader)}")
训练和测试:
使用准备好的数据集对模型进行训练和测试,评估模型的性能指标,评测方式采用计算box 加权AP的方式,对IoU = 0.5计算各类AP后加权。
首先计算每个类的AP:
(1)根据预测框和标注框的IoU是否达到阈值0.5判断该预测框是真阳性还是假阳性;
(2)根据每个预测框的置信度进行从高到低排序;
(3)在不同置信度阈值下计算精确率和召回率,得到若干组PR值;
(4)绘制PR曲线并计算AP值。
然后计算加权AP:把所有类的AP值按照权重加权得到wAP。
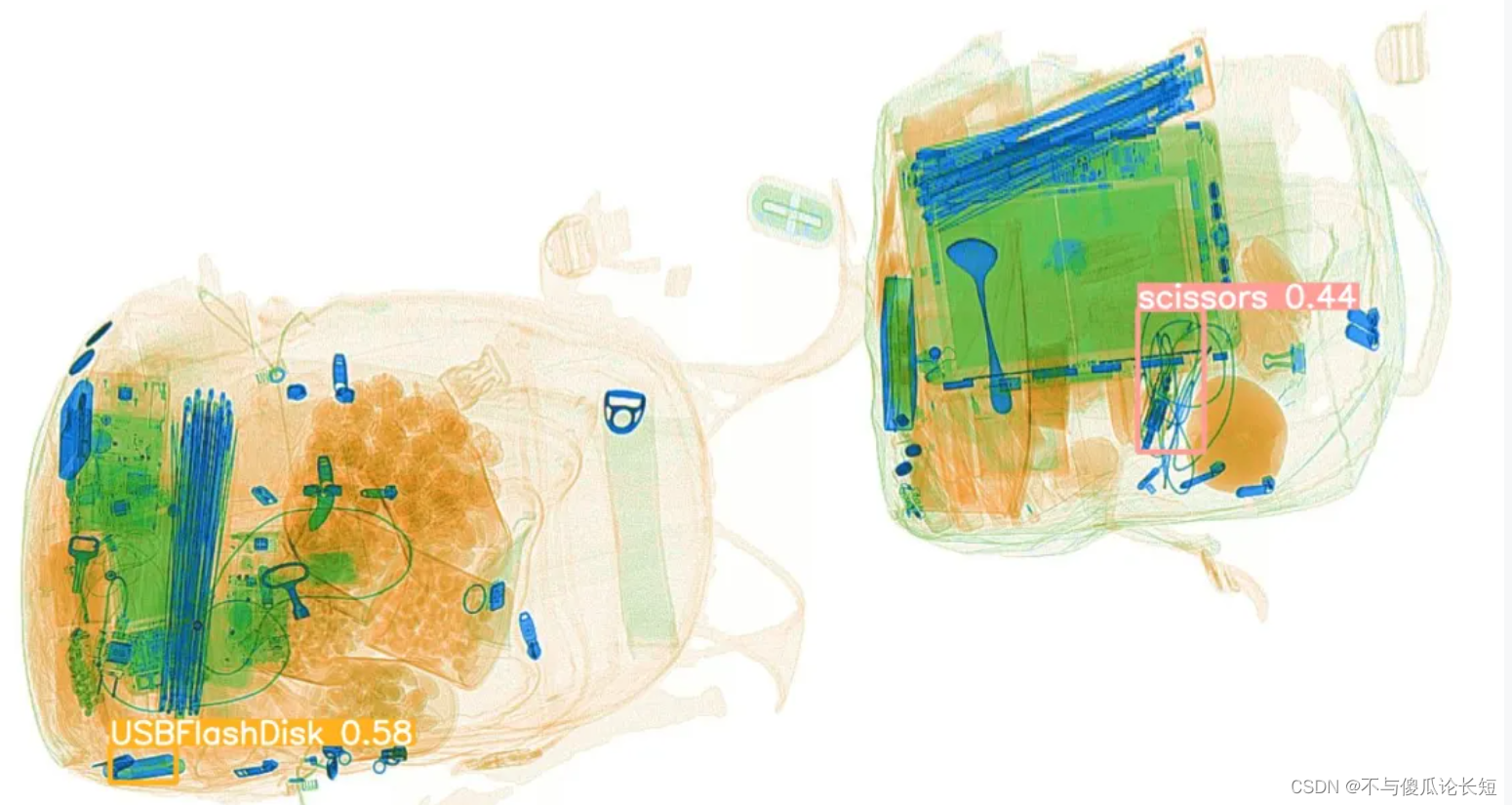
总结
最终我们实现了一个demo案例,根据输出的违禁品概率,按照概率高低依次告警级别为必须核查、一般性核查、建议人工核查、正常,输出可能的违禁品种类和告警级别,提示安检员做针对性的处理。
在训练阶段,我们使用 Intel® Extension for Pytorch 等加速库提高模型的响应速度。对原始数据集进行数据清洗和默认值的填充。














 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









