







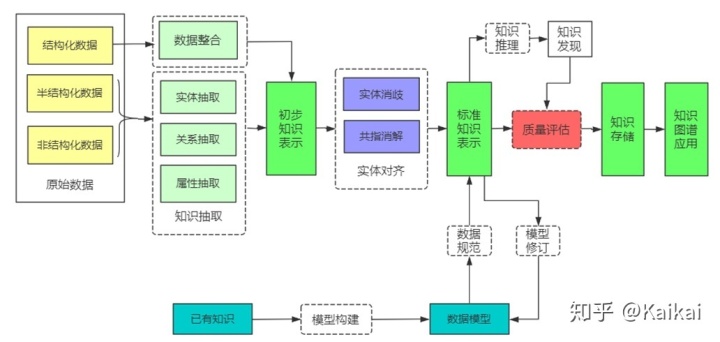
导读:
1.知识提取
Kaikai:知识图谱—知识提取zhuanlan.zhihu.com
2.知识表示(一)
Kaikai:知识图谱—知识表示(一)zhuanlan.zhihu.com
上篇文章,介绍了知识表示学习的常见的代表模型:距离模型、单层神经网络模型、能量模型、双线性模型、张量神经网络模型、矩阵分解模型。在本篇文章中,我们介绍翻译模型(Trans模型)。
1.TransH模型
在处理1-N,N-1,N-N复杂关系时的局限性,TransH模型提出让一个实体在不同的关系下拥有不同的表示。
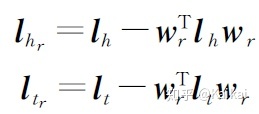
损失函数:
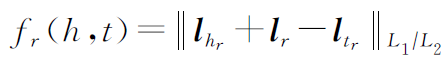
2.TransR/CTransR模型
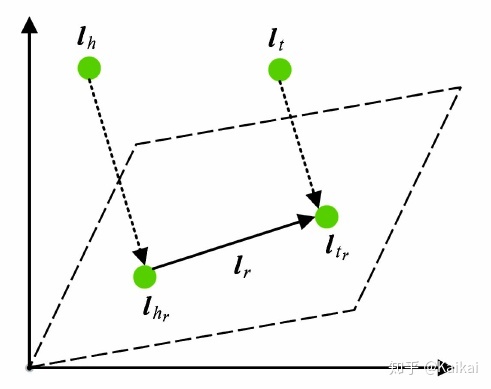
虽然TransH模型使每个实体在不同关系下拥有不同的表示,它仍然假设实体和关系处于相同的语义空间R中,在一定程度上限制了TransH的表达能力。TransR模型认为,一个实体是多种属性的综合体,不同关系关注实体的不同属性。TransR认为不同的关系拥有不同的语义空间,对每个三元组,首先应将实体投影到对应的关系空间中,然后再建立从头实体到尾实体的翻译关系。
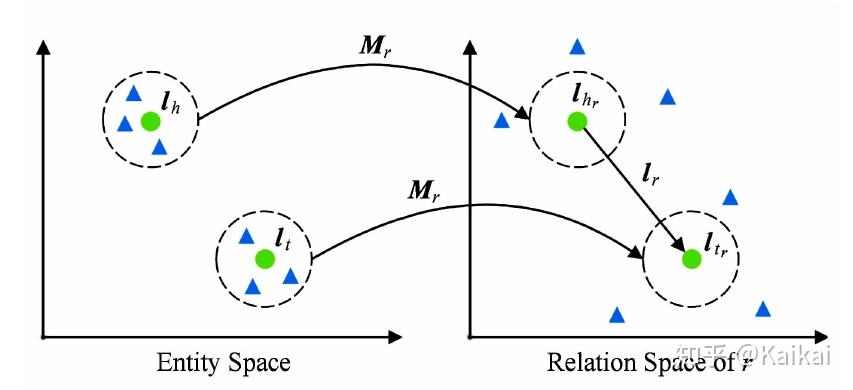
上图是TransR模型的简单示例,对于每个三元组(h,r,t),我们首先将实体向量向关系r空间投影,原来在实体空间中与头(圆圈表示)、尾实体相似的实体(三角形表示),在关系r空间内被区分开了。具体而言,对于每一个关系r,TransR定义投影矩阵
然后
相关研究表明,某些关系还可以进行更细致的划分。于是,Lin等人进一步提出了CTransR模型,通过把关系r对应的实体对的向量差值
TransR模型的缺点:
(1)在同一个关系r下,头、尾实体共享相同的投影矩阵。然而,一个关系的头、尾实体的类型或属性可能差异巨大。例如(美国,总统,奥巴马),美国和奥巴马的类型不同,一个是国家,一个是人物。
(2)从实体空间到关系空间的投影是实体和关系的交互过程。因此TransR让投影矩阵仅与关系有关是不合理的。
(3)与TransE和TransH相比,TransR引入了空间投影,使得TransR模型参数急剧增加,计算复杂率大大提高。
3.TransD模型
为了解决TransR模型的缺点,Ji等人提出了TransD模型,如下图所示,给定三元组
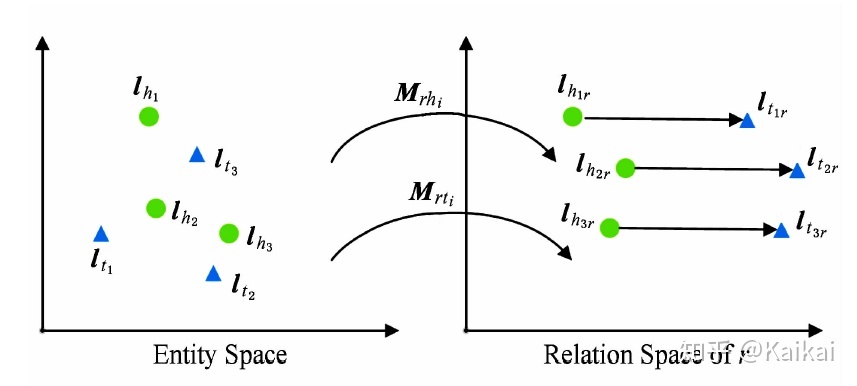
利用2个投影向量构建投影矩阵,解决了原来TransR模型参数过多的问题。最后,TransD模型定义了损失函数:
4.TransSpare模型
知识库中实体和关系的异质性和不平衡性是制约知识表示学习的难题:
(1)异质性:知识库中某些关系可能会与大量的实体有连接,而某些关系则可能仅仅与少量实体有连接。
(2)不均衡性:在某些关系中,头实体和尾实体的种类和数量可能差别巨大。
为了解决实体和关系的异质性。TransSparse提出使用稀疏矩阵
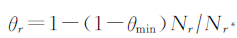
为了解决关系的不平衡性问题,TranSparse对于头实体和尾实体分别使用2个不同的投影矩阵
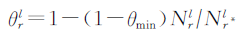
其中,
TranSparse对于以上2种形式,均定义如下损失函数:
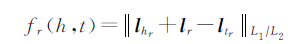
5.TransA模型
Xiao等人提出TransA模型,将损失函数中的距离度量改为马氏距离,并为每一维学习不同的权重,对于每个三元组
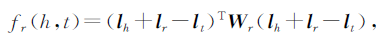
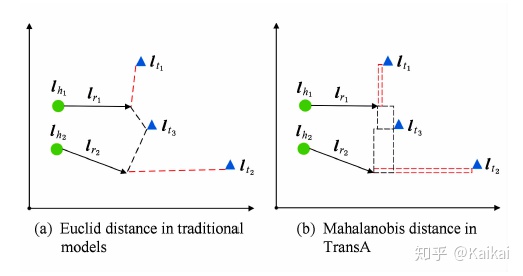
如下图所示:
6.TransG模型
TransG模型提出使用高斯混合模型描述头、尾实体之间的关系。该模型认为,一个关系会对应多种语义,每种语义用一个高斯分布来刻画,其中I表示单位矩阵。
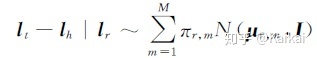
TransG模型与传统模型的对比如下图所示。其中三角形表示正确的尾实体,圆形表示错误的尾实体。
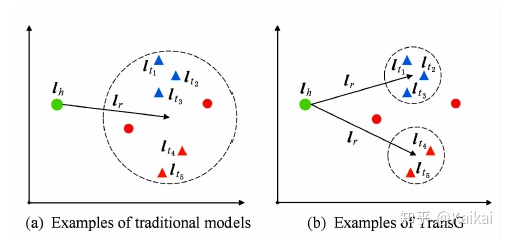
图(a)中为传统模型示例,由于将关系r的所有语义混为一谈,导致错误的实体无法被区分开,而图(b)所示,TransG模型通过考虑关系r的不同语义,形成多个高斯分布,就能区分出正确和错误实体。
7.KG2E模型
知识库中的关系和实体的语义 本身具有不确定性,这在过去模型中被忽略了。因此He等人提出KG2E,使得高斯分布来表示实体和关系。其中高斯分布的均值表示的是实体或关系在语义空间中的中心位置,而高斯分布的协方差则表示该实体或关系的不确定度。下图为KG2E的模型示例,每个圆圈代表不同实体与关系的表示,其中圈圈大小表示的是不同实体或关系的不确定度。















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









