







在本练习中,我们将从一些简单的2D数据集开始使用SVM来查看它们的工作原理。
1.线性核函数(Linear Kernel)SVM
顾名思义,基于线性核函数的SVM主要是用来实现线性决策边界的分类问题的。
1.1 原始数据展示
# 读取数据
mat_data = sio.loadmat('./data/ex6data1.mat')
data = pd.DataFrame(mat_data['X'], columns=['x1', 'x2'])
data['y'] = mat_data['y']
数据展示函数:
def show_data(data):
# 展示数据
# 布尔值索引data['Admitted'].isin([1]):False,True,False...
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
# 子画布
fig, ax = plt.subplots(figsize=(8,6))
ax.scatter(positive['x1'], positive['x2'], s=50, c='g', marker='o', label='T')
ax.scatter(negative['x1'], negative['x2'], s=50, c='r', marker='x', label='F')
ax.legend() # 标签
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('Source Data')
plt.show()
数据展示:
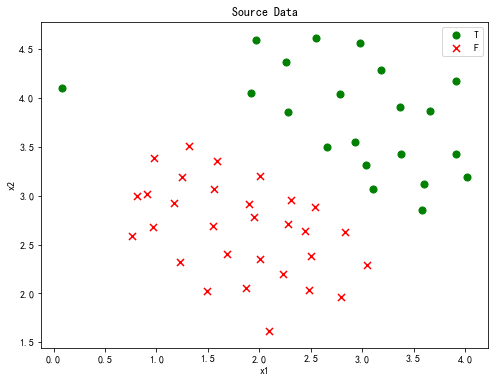
可以看到这是一个线性决策边界的简单数据集,并且在(0.2,4.2)位置有一个异常点,下面我们将探索SVM中的超参数C(可以理解为正则化超参数λ的倒数)的值和这个异常点对决策边界造成的影响。
1.2 观察参数C改变时对模型带来的影响
C =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









