







本篇内容摘自《谁说菜鸟不会数据分析(入门篇)》。本书重点讲使用EXCEL进行数据分析,在笔记中,我加入了SQL和python的使用方法,来对比记忆
本篇介绍前四章内容
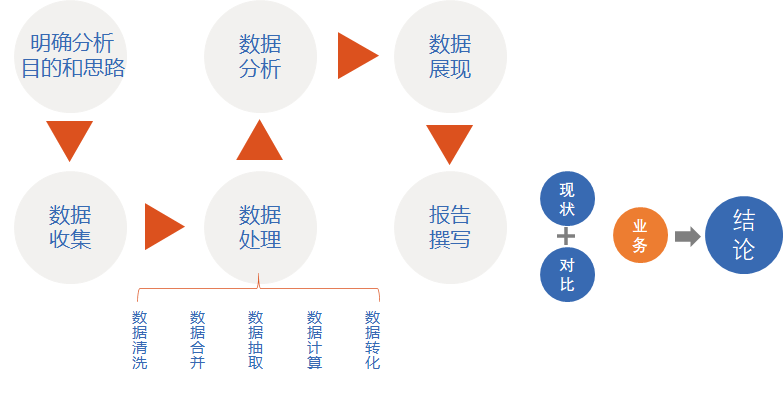
- 数据分析流程
- 结构为王,确定分析思路
- 无米难为巧妇,数据准备
- 简单快捷,数据处理(数据清洗、数据合并、数据抽取、数据计算、数据转换)
- 工欲其事比先利其器,数据分析(现状分析、原因分析、预测分析)
- 给数据量体裁衣,数据展现
- 专业的报告,体现价值
其余部分参考↓↓↓
【菜鸟入门第2篇】分析方法
【菜鸟入门第3篇】数据图表(重点讲解旋风图制作)
【菜鸟入门第4篇】如何写数据报告
下面开始正文。数据分析入门之始,菜鸟和老鸟存在不少差距
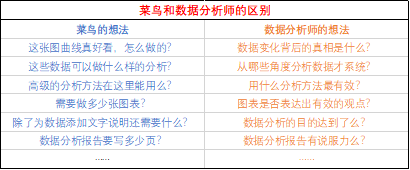
前言:数据分析定义
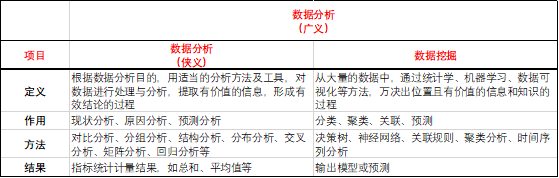
一、数据分析流程
二、结构为王,确定分析思路
常用的数据分析方法
PEST分析法:政治环境(political)、经济环境(economic)、社会环境(social)、技术环境(technology)

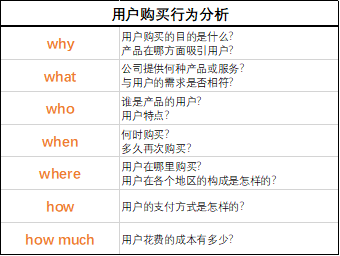
5W2H分析法:何因(why)、何事(what)、何人(who)、何时(when)、何地(where)、如何做(how)、何价(how much)
逻辑树分析法:把一个已知问题当做树干,然后开始考虑这个问题和那些问题有关。没想到一点,就给这个问题所在的树干加上一个树枝
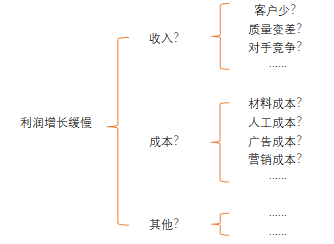
4P营销理论:产品(product)、价格(price)、渠道(palce)、促销(promotion)
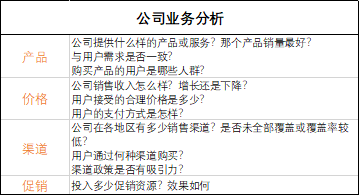
三、无米难为巧妇,数据准备
- 数据来源 —— 米从哪里来
- 理解数据 —— 米的构造(字段和记录)、种类(数值型、文本型)和要求(数据表要是一维表!)
将文本数据导入EXCEL

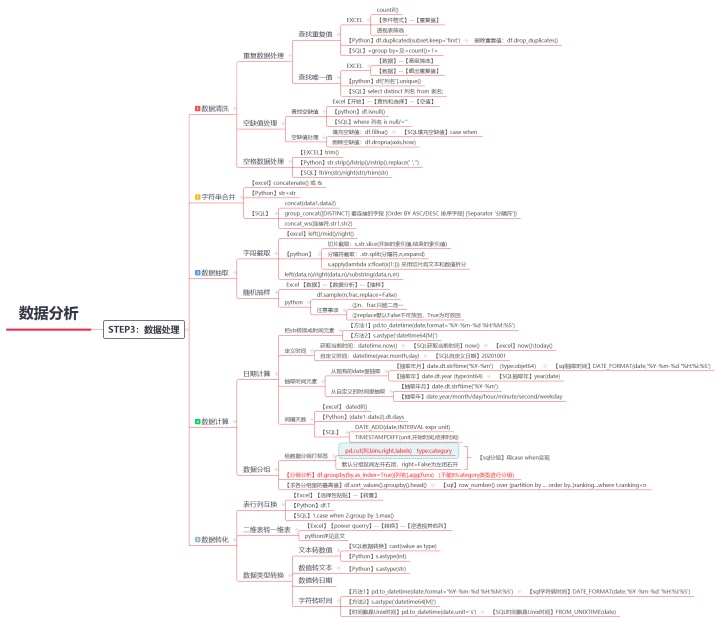
四、简单快捷,数据处理
- 数据清洗(重复值处理、缺失值处理、空格值处理)
- 数据合并
- 数据抽取(字段截取、随机抽样)
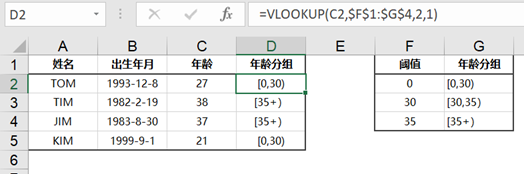
- 数据计算(日期计算、数据分组)
- 数据转换(表行列互换、二维表转一维表数据透视表不能处理二维数据呀、数据类型转换:文本转数值/数值转文本/数值转日期)
1.数据重复
-- EXCEL篇
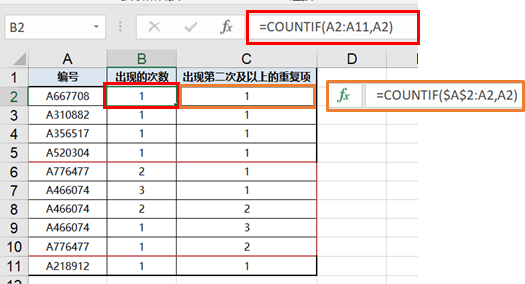
- 查找重复值
a.【函数法】出现的次数>1的为重复值
b.【条件格式】--【重复值】
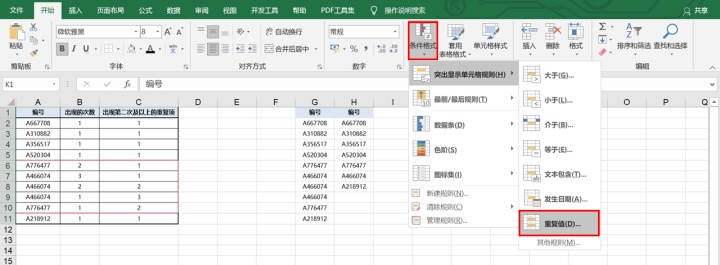
c.透视表筛选
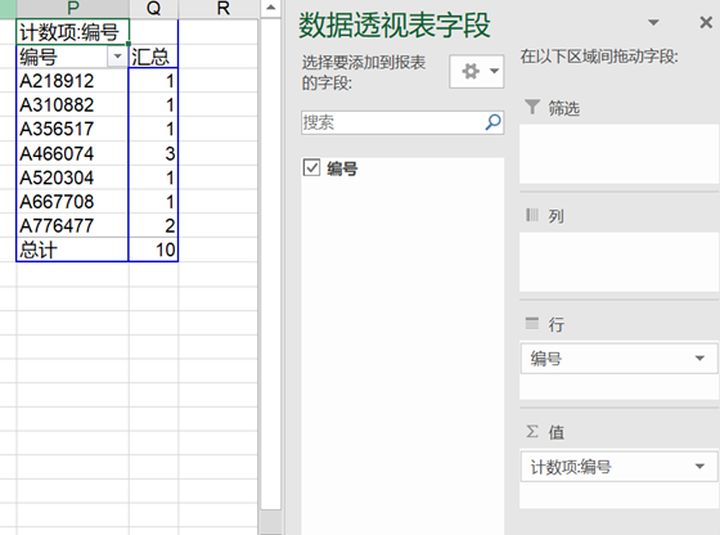
- 复制唯一值
a.【数据】--【高级筛选】
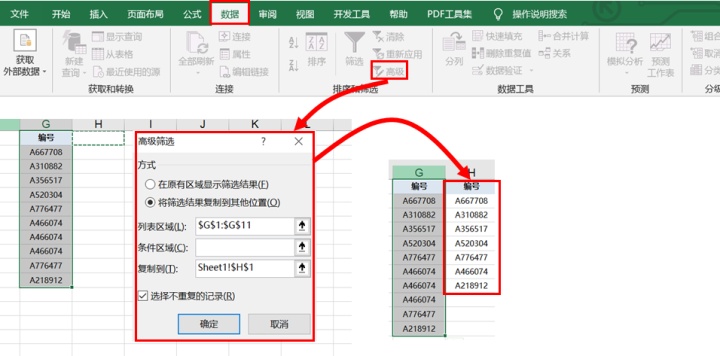
b.【数据】--【删除重复值】

2.缺失值处理
--用EXCEL批量填充缺失值

保持A2:A13单元格数据区域中所有空值的选中状态,按键盘上的"="键,再按"↑"键,再按“Ctrl+Enter”快捷键,完成填充
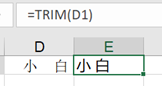
3.空格数据处理
trim(text) 删除文本前后的空格,保留文本自己的空格
4.字段合并
concatenate(text1,text2,…)
或
使用"&"

5.字段截取
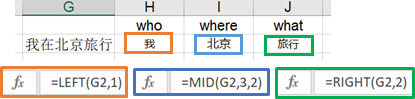
6.随机抽样
- 先用rand()函数求出随机数,再用RANK()函数求出随机数排序,再用VLOOKUP来匹配。不过实际操作中,vlookup得到的结果经常是#Na,查了很多资料也没有找到有效解决方法。所以建议用index()+match()函数替代
- 使用【数据】-【数据分析】-【抽样】来随机抽取,但有可能出现重复值,还有需注意,抽样只能是数值型。
- =rand() 返回[0,1]的均匀分布随机数
- =randbetween() 返回一个结余指定的数字之间的随机数
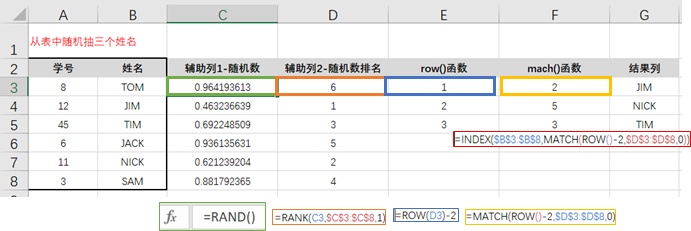
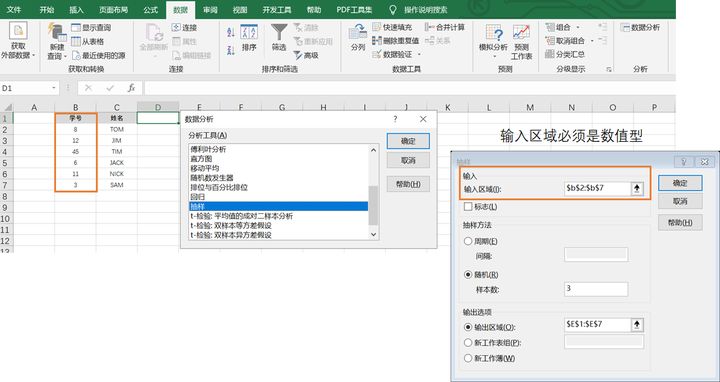
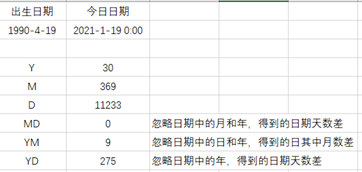
7.日期计算
datedif(start_date,end_date,unit)
- Y 时间段中的整数年
- M 时间段中的整数月
- D 整数天
- MD 忽略日期中的月和年,得到的日期天数差
- YM 忽略日期中的日和年,得到的日其中月数差
- YD 忽略日期中的年,得到的日期天数差
8.数据分组
if()或vlookup()。不过还是觉得用python和SQL分组更简单
- pd.cut(列,bins,right,labels)
- 默认左开右闭,right=False,左闭右开
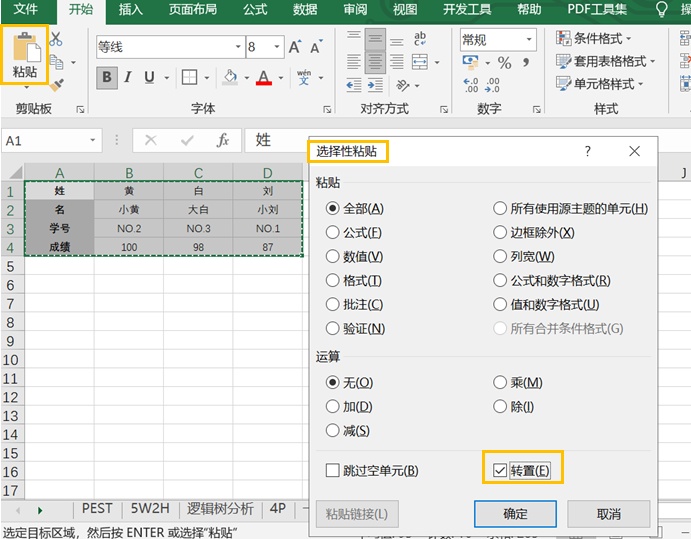
9.数据表行列转换
【开始】--【粘贴】--【选择性粘贴】--【转置】
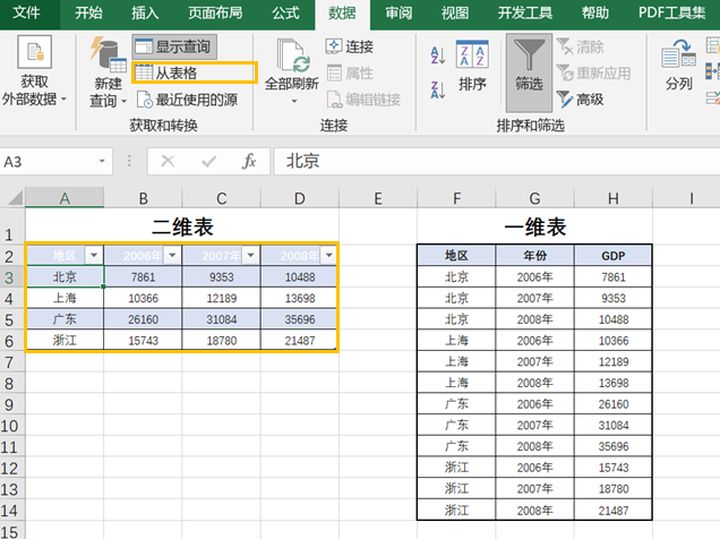
10.二维表转一维表
参考:采悟:二维表转一维表,看这篇文章就够了
--透视表法(参考步骤)
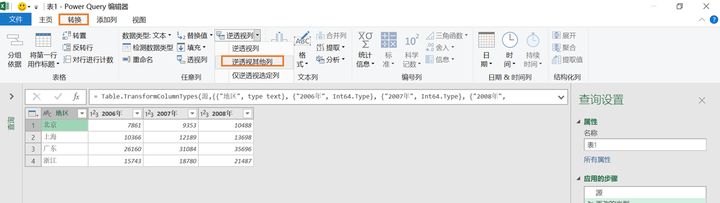
--power querry法
选中二维表,【数据】--【新建查询】--【从表格】,选中地区任意一单元格,【转换】--【逆透视其他列】,最后关闭并上载
【Python】
df=pd.read_csv('path')
new_df= df.set_index('地区') # 将df中的地区一列设置为索引列
df1 =new_df.stack() # stack的返回对象df1是一个二级索引Series对象
df2 =df1.reset_index() # 通过reset_index函数将Series对象的二级索引均转化为DataFrame对象的列值
df2.columns = ['地区','年份','金额']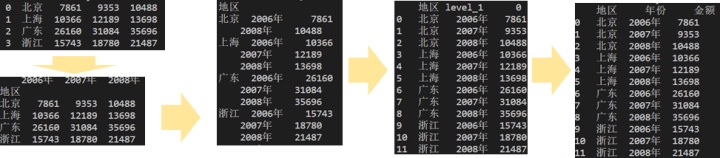
11.数据类型转换
-- 文本转数值
- 【数据】--【分列】-【常规】,一直点下一步就好
- 或者用value()函数
-- 数值转文本
- 【数据】--【分列】-【文本】,一直点下一步就好
- 或者用text()函数
-- 数值转日期
【数据】--【分列】-【日期】,一直点下一步就好
。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









