









Tensor
-
Tensor是Pytorch中重要的数据结构,它可以是一个数、一维数组、二维数组或更高维的数组。Tensor和Numpy的narrays类似,但是Tensor可以使用GPU加速。
-
Tensor基本示例
包的导入:import torch as t定义一个矩阵(不初始化):
#创建5*3的矩阵(未初始化) x = t.Tensor(5,3) x
创建均匀分布初始化的数组:x = t.rand(5,3) x
查看Tensor的形状:print(x.size())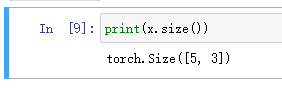
Tensor的加法(方法一):y = t.rand(5,3) t.add(x,y)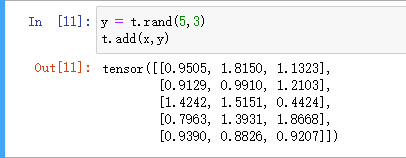
Tensor的加法(方法二):x+y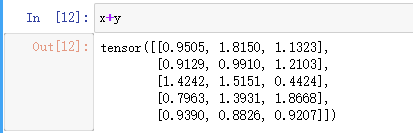
Tensor的加法(方法三):result = t.Tensor(5,3) t.add(x,y,out=result) result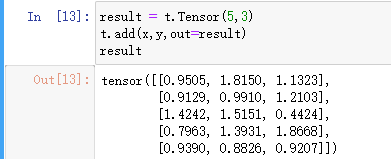
函数名后面带下划线_的函数会修改Tensor本身。例如:x.add_(y)和x.t_()会改变x,但x.add(y)和x.t()会返回一个新的Tensor,而x不变。 -
Tensor和Numpy的数组间的操作非常容易且快速,Tensor不支持的操作,可以先转为numpy数组处理,之后再转回Tensor。
a = t.ones(5) a b = a.numpy() b
-
Tensor与Numpy的互相转化
import numpy as np a = np.ones(5) b = t.from_numpy(a) print(a) print(b)
-
Tensor和Numpy对象共享内存,所以它们之间的转换很快,而且几乎不会消耗资源。因此,一个改变了,另一个也会改变。
b.add_(1) print(a) print(b)``` 
Autograd:自动微分
-
深度学习算法的本质是通过反向传播求导数,pytorch的Autogard模块实现了此功能。Autogard.Variable是Autogard中的核心类,它简单封装了Tensor,并支持几乎所有Tensor的操作,可以调用它的.backward实现反向传播,自动计算所有梯度。
-
Variable主要包含三个属性:
data:保存Variable所包含的Tensor
grad:保存data对应的梯度,其本身也是一个Tensor
grad_fn:指向一个function,这个函数用来反向传播计算输入的梯度 -
Variable的简单使用
导入:from torch.autograd import Variable创建:
x = Variable(t.ones(2,2),requires_grad=True) x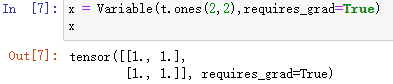
求和:y = x.sum() y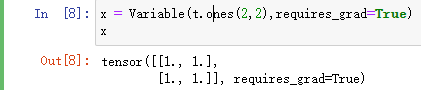
梯度计算:y.grad_fn y.backward()
卷积神经网络
- 网络结构:数据输入层/ Input layer、卷积计算层/ CONV layer、ReLU激励层 / ReLU layer、池化层 / Pooling layer、全连接层 / FC layer
- 数据输入层:主要是对原始图像数据进行预处理
- 卷积层:当给定一张新图时,CNN并不能准确地知道这些特征到底要匹配原图的哪些部分,所以它会在原图中把每一个可能的位置都进行尝试,相当于把这个feature(特征)变成了一个过滤器。这个用来匹配的过程就被称为卷积操作。
卷积的操作如图所示:

要计算一个feature(特征)和其在原图上对应的某一小块的结果,只需将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可。



根据卷积的计算方式,第一块特征匹配后的卷积计算如下,结果为1

对于其它位置的匹配,也是类似(例如中间部分的匹配)

计算之后的卷积如下:

以此类推,对三个特征图像不断地重复着上述过程,通过每一个feature(特征)的卷积操作,会得到一个新的二维数组,称之为feature map。其中的值,越接近1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。如下图所示:

可以看出,当图像尺寸增大时,其内部的加法、乘法和除法操作的次数会增加得很快,每一个filter的大小和filter的数目呈线性增长。由于有这么多因素的影响,很容易使得计算量变得相当庞大。 - 池化层
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是22大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
下图显示了左上角22池化区域的max-pooling结果,取该区域的最大值max(0.77,-0.11,-0.11,1.00),作为池化后的结果,如下图:

池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图:

其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下:

对所有的feature map执行同样的操作,结果如下:

最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。 - 激励层
常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。

在卷积神经网络中,激活函数一般使用ReLU(The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,max(0,T),即对于输入的负值,输出全为0,对于正值,则原样输出。
ReLU激活函数操作过程:
第一个值,取max(0,0.77),结果为0.77,如下图:

第二个值,取max(0,-0.11),结果为0,如下图

以此类推,经过ReLU激活函数后,结果如下:

对所有的feature map执行ReLU激活函数操作,结果如下:

- 深度神经网络
通过将上面所提到的卷积、激活函数、池化组合在一起,就变成下图:

通过加大网络的深度,增加更多的层,就得到了深度神经网络,如下图:

- 全连接层
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:

由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)

在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)

上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:

- 卷积神经网络
将以上所有结果串起来后,就形成了一个“卷积神经网络”(CNN)结构,如下图所示:
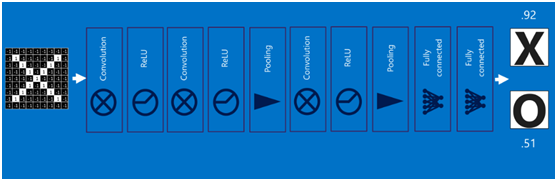
定义网络
#定义网络
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
#nn.Module.__init__(self)
super(Net,self).__init__()
#卷积层
#输入图片为单通道,输出为6通道,卷积核为5*5
self.conv1 = nn.Conv2d(1,6,5)
#输入图片为6通道,输出为16通道,卷积核为5*5
self.conv2 = nn.Conv2d(6,16,5)
#全连接层y=Wx+b
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
#卷积-激活-池化
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(x.size()[0],-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)

只要在nnModule的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)
参数查看
params = list(net.parameters())
print(len(params))
for name,parameters in net.named_parameters():
print(name,":",parameters.size())

损失函数
nn实现了神经网络中大多数的损失函数,例如nn.MSELoss用来计算均方误差,nn.CrossEntropyLoss用来计算交叉熵损失。
import torch as t
from torch.autograd import Variable
input = Variable(t.randn(1,1,32,32))
output = net(input)
target = Variable(t.arange(0,10))
criterion = nn.MSELoss()
loss = criterion(output,target)
loss
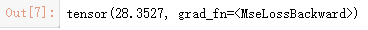














 1326
1326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









