









数据预处理
创建一个人工数据集,并存储在csv文件中
import os
os.makedirs(os.path.join('..','data'),exist_ok=True)
data_file = os.path.join('..','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,10600\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
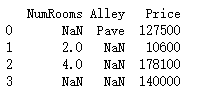
从创建的csv文件中加载数据集
import pandas as pd
data = pd.read_csv(data_file)
print(data)
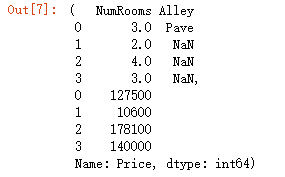
缺失值处理:插值和删除
inputs,outputs = data.iloc[:,0:2],data.iloc[:,2]
#将值为空的元素用平均值填充
inputs = inputs.fillna(inputs.mean())
inputs,outputs
对于inputs中的类别值或离散值,将‘NaN’视为一个类别
inputs = pd.get_dummies(inputs,dummy_na=True)
print(inputs)
















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









