







关联分析
选择函数包
关联分析属于数据挖掘的一大类。我发现的python语言实现的包有两个:
pymining:根据Apriori算法进行关联规则挖掘
Orange3的关联规则库:根据FP-growth算法进行关联规则挖掘
经过分析,我决定使用Oranges进行关联规则的实现,原因如下:
FP-growth算法比Apriori算法时间复杂度低
Orange3是一整套数据挖掘工具包,学习后可以熟悉相关操作,进行其他的数据挖掘算法的研究
pymining不再维护,Orange3仍然是一个非常活跃的包,更新频繁
Orange3实现的结果比较多,除了规则外,还能够计算出评价结果的相关数据
注意:Orange3的关联分析模块安装时需要在Anaconda的命令行窗口中输入以下命令pip install orange3-associate
数据输入
对于使用函数包来说,我们不用管函数实现的方法,只有研究数据输入的格式即可。
Orange3的关联规则输入支持两种形式:
布尔类型
字符串类型
对于布尔类型
每一个行向量代表一个属性是否存在的数据结构
>>> X
array([[False, True, ..., True, False],
[False, True, ..., True, False],
[ True, False, ..., False, False],
...,
[False, True, ..., True, False],
[ True, False, ..., False, False],
[ True, False, ..., False, False]], dtype=bool)
比如上面的数据X,注意这个array(属于numpy里面的多维数组)。类型一定是bool才行。
这个二维数组每一个行的维度都是一样的,这样得到的规则结果就是纯粹数组直接的关联
规则,我们要自己讲对于规则的数字和属性名称对于起来。
比如结果可能是这样:
>>> rules
[(frozenset({17, 2, 19, 20, 7}), frozenset({41}), 41, 1.0),
(frozenset({17, 2, 19, 7}), frozenset({41}), 41, 1.0),
...
(frozenset({20, 7}), frozenset({41}), 41, 1.0),
(frozenset({7}), frozenset({41}), 41, 1.0)]
对于字符串类型
这里我们输入就不要求每个数据的维度相同了,我们仅仅把出现的属性字符给输入进去即可。
比如下面的例子,我把上次爬虫得到的数据
进行关联规则分析。
输入数据的excel表格为NS_new.xls,表格内容截图如下:
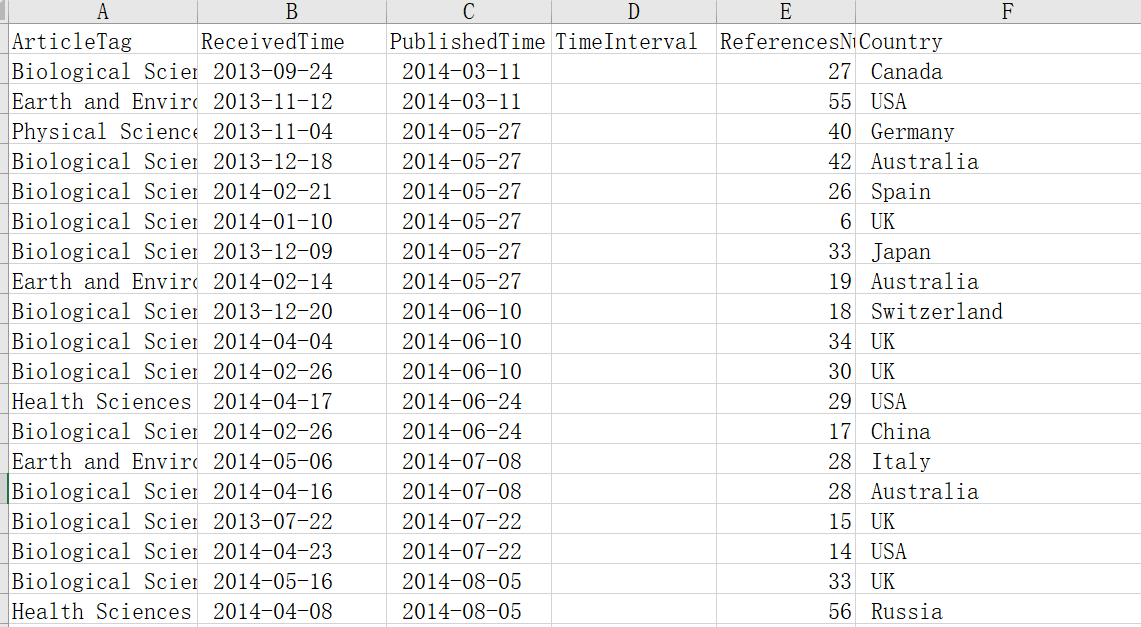
我们可以看到,我们一共有ArticleTag、ReceivedTime、PublishedTime、TimeInterval、ReferencesNum、Country这
6个属性。其中TimeInterval属性为空,用来填写PublishedTime和ReceivedTime属性之间的时间差的数据。因为我们想要分析
时间差和其他属性之间的关联关系,而不是“接收时间”与“发表时间”与其他属性之间的关联关系。
时间差需要操作两个列属性,而且两个列属性之间的减法是时间日期相关的操作,涉及到每个月份不一样&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









