






本发明涉及人脸识别技术领域。
背景技术:
在人脸识别应用领域中,一个重要的应用过程就是从众多人脸图像中,找出同一个人的所有图像。在现有的社会场景中(例如:学校、媒体、公安等),都会有大量的图片存在数据库中,如何从大量的数据图像中,快速找到一个人的所有图片是一个难题。如果使用1:1精确比对的方法计算,则速度慢,检索时间长,同时所有的人脸图像特征向量放在内存中,会占用大量的内存空间。因此,需要设计一种高效、快速的人脸检索方法,来提高检索速度,同时降低内存的消耗。
技术实现要素:
本发明的目的在于提供一种基于k均值聚类算法的人脸识别检索方法,具有较快的检索速度,同时解决大量人脸特征向量存放在内存中,消耗硬件资源的问题。
实现上述目的的技术方案是:
一种基于k均值聚类的人脸识别检索方法,包括:
使用卷积神经网络从图像库中提取人脸图像的特征向量,建立人物库,每个人物都通过k均值聚类方法计算出该人物对应的中心向量;
使用卷积神经网络从待查询图像中提取特征向量,并与人物库中的各中心向量作浮点数精确比对,通过比较结果,确定返回的检索结果。
优选的,从图像库中,使用mtcnn(Multi-task convolutional neural networks,多任务卷积神经网络)对普通图像检测人脸位置,并对检测出来的人脸做对齐和裁剪操作,得到人脸图像;
利用insightface(Additive Angular Margin Loss for Deep Face Recognition,基于角度的人脸识别模型)学习模型提取人脸图像的特征向量;
将人脸图像的特征向量与人物库中的中心向量作浮点数精确比对,判断该人脸属于人物库中的哪个人物,将人脸图像的特征向量存入该人物中,并更新中心向量。
优选的,若人脸图像的特征向量与中心向量浮点数精确比对的结果小于预设的阈值,是同一人,反之,则不是同一人;
如果人脸图像的特征向量不属于任何一个人物,则创建新的人物。
优选的,利用insightface学习模型提取待查询图像的特征向量;
若待查询图像的特征向量与中心向量浮点数精确比对的结果小于预设的阈值,返回与该人物对应的所有人脸;若相反,返回结果查无此人。
优选的,所述的人物库中,当人物中只有一个人脸图像的特征向量时,通过k均值聚类方法计算出来中心向量等于这个人脸图像的特征向量。
优选的,每个人脸图像的特征向量或待查询图像的特征向量都有512维。
优选的,人物库中一个人物的所有人脸图像的特征向量对应维数相加,除以人脸图像的特征向量的个数,即为中心向量。
优选的,人脸图像的特征向量或待查询图像的特征向量中,每一维中的数据都是浮点数。
优选的,所述的浮点数精确比对,指:求两个向量的余弦距离;
所述的预设的阈值,指:同一个人的人脸特征向量的最大夹角距离。
本发明的有益效果是:本发明通过构建人物库的方法,可以大大减少人脸识别时的比对次数,从而减少计算量,加快检索速度。同时,因为在数据量很庞大的情况下,把所有人脸的特征向量加载到内存中,会消耗大量的内存资源,构建人物库,只用把人物库的中心向量加载到内存中即可,可以节约内存。
附图说明
图1是本发明的人脸识别检索方法的流程步骤图;
图2是本发明的人脸识别检索方法的流程示意图;
图3是本发明中人物库的构建示意图;
图4是本发明中中心向量的计算示意图;
图5是本发明中精确比对的示意图。
具体实施方式
下面将结合附图对本发明作进一步说明。
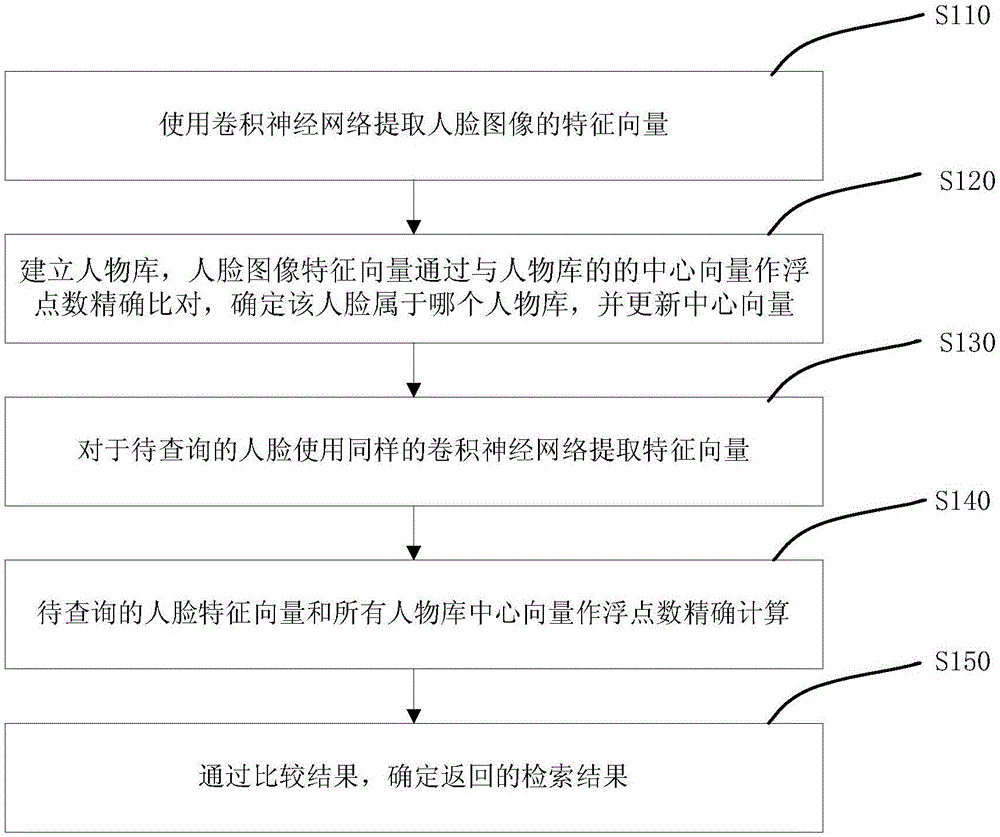
请参阅图1和图2,本发明的基于k均值聚类的人脸识别检索方法,包括下列步骤:
步骤S110,使用卷积神经网络从图像库中提取人脸图像的特征向量,使用insightface学习模型,作为特征向量提取的方法,提取出的特征向量有512维,是一个高维的浮点数。在提取之前,从图像库中使用mtcnn对普通图像检测人脸位置,并对检测出来的人脸做对齐和裁剪操作,得到人脸图像。
步骤S120,建立人物库,每个人物都通过k均值聚类方法计算出该人物对应的中心向量。中心向量的数量和人物个数相等。将人脸图像的特征向量与人物库中的中心向量作浮点数精确比对,判断该人脸属于人物库中的哪个人物,将人脸图像的特征向量存入该人物中,并更新中心向量。若人脸图像的特征向量与中心向量浮点数精确比对的结果小于预设的阈值,是同一人,反之,则不是同一人;如果人脸图像的特征向量不属于任何一个人物,则创建新的人物。
具体地,如图3所示,人物库的具体构建过程包括:
对于第一个从图像库中提取出来的人脸图像,在人物库中创建人物1。使用卷积神经网络提取人脸特征向量,并将该特征向量放入人物1中。使用k均值(k=1)聚类方法,计算人物1的中心向量,保存在人物1中。当人物中只有一个人脸图像的特征向量时,通过k均值(k=1)聚类方法计算出来的人物中心向量等于这个人脸图像的特征向量。
对于第二个从图像库中提取出来的人脸图像,同样提取其特征向量,该特征向量需要先和人物1的中心向量精确比较,确定人脸和人物1是不是同一个人。如果对比结果大于设定的阈值,创建人物2,把第二个人脸特征向量放入人物2,计算人物2的中心向量。如果比对结果小于设定好的阈值,那证明这两个人脸是同一个人,将第二个人脸的特征向量放入人物库1,重新计算人物1的中心向量。
对于后续的人脸,需要先和已经存在于人物库中的人物中心向量作比较,如果该人脸是其中的某个人物,则将该人脸的特征向量加入该人物中,如果不存在于人物库中,则创建新的人物。每一个人脸只会属于一个人物,每一个人物可以包含多个人脸。
如图4所示,计算人物的中心向量,在做后续的计算和比对过程中,用中心向量来代替人物做计算。在人物库中,包含多个人物,每个人物下,包含多个人脸图像的特征向量,每个人脸图像的特征向量,对应一个人脸图像。在计算中心向量时,多个特征向量通过k均值(k=1)聚类方法,计算人物中心向量。具体的计算过程包括:每一个特征向量都有512维,所有特征向量对应维数相加,除以特征向量的个数,即为中心向量。
步骤S130,查询检索过程,同样使用卷积神经网络从待查询图像中提取特征向量。同样采用insightface学习模型。
步骤S140,将待查询图像的特征向量与人物库中的各中心向量作如步骤S120一样的浮点数精确比对。人脸图像的特征向量或待查询图像的特征向量中,每一维中的数据都是浮点数。如图5所示,浮点数精确比对的过程是求两个向量的余弦距离。人脸图像的特征向量提取模型insightface,在训练过程中使用的是余弦距离。比对的结果是两个向量的夹角距离。和提前设定好的阈值作对比来确定是不是同一个人。
预设的阈值表示同一个人的人脸特征向量的最大夹角距离。数值大于设定的阈值表示不是同一个人,反之,是同一个人。
步骤S150,通过比较结果,确定返回的检索结果。如果查到了人脸和某个人物相似,则对应该人物中的所有人脸和待查询的人脸相似,返回该人物对应的所有人脸。如果查不到结果,证明数据库中没有该人物,返回结果查无此人。
以上实施例仅供说明本发明之用,而非对本发明的限制,有关技术领域的技术人员,在不脱离本发明的精神和范围的情况下,还可以作出各种变换或变型,因此所有等同的技术方案也应该属于本发明的范畴,应由各权利要求所限定。















 5945
5945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









