






一、统计量
样本均值:即在总体中的样本数据的均值,反映样本数据的集中趋势。
样本方差:每个样本值与全体样本值平均数之差的平方值的平均数;方差是用来衡量随机变量和其数学期望(均值)之间的偏离程度。
样本变异系数:变异系数又称为离散系数,定义为标准差与平均值之比,样本变异系数即样本数据的标准差与其均值之比。
样本k阶中心矩:在概率论中,矩是用来描述随机变量的某些特征的数字,即求平均值;随机变量X的K阶中心矩定义:对于正整数k,如果E(X)存在,E[(X-E(X))^K] <无穷大,则E[(X-E(X))^K] 为x的k阶中心矩。
样本偏度:常用作总体偏度的估计量和检验总体分布正态性的统计量,样本三阶中心距除以二阶中心距的3/2次幂的商记为SK;而总体偏度是一个描述总体分布不对称性的数字特征,正态分布的偏度为0。
样本峰度:常用以作为总体峰度的估计量,样本的四阶中心距除以样本二阶中心距平方的商再减去3,记为ku;正态分布的峰度为0。
二、抽样分布
中心极限定理:即不论总体服从什么分布,只要从总体中抽取的样本容量足够大,这些样本组成的样本均值的抽样分布都近似于正态分布。
样本方差的分布:作为随机变量的函数,样本方差本身就是一个随机变量,S^2服从卡方分布,
卡方分布:
卡方统计量是一个随机变量,能够表明样本方差和总体方差之间对的比值关系,卡方统计量决定的抽样分布就是卡方分布;
卡方统计量:
定义:若样本量为n的所有可能样本均取自方差为
作用:卡方分布能够用于从样本方差到总体方差的推断性分析;还能用于非参数检验(卡方检验)。
T分布:
若已知待分析的总体服从正态分布,从总体中抽取容量为n 的所有可能样本,计算出每个样本的T统计量,则所有的T统计量的值将组成一个连续型概率分布,此分布为T分布。T分布能在部分已知条件下,用于总体均值的推断分析。
对于T分布来说,如果总体服从正态分布,总体标准差未知,当样本容量小于30时,那么样本均值的抽样分布服从T~t(n-1)的T分布;
若总体服从正态分布,总体标准差未知,样本容量大于等于30时,那么样本均值的抽样分布不仅服从T~t(n-1)的T分布,而且还可以用Z分布来近似表达。
F分布:
F分布能通过两个样本之间的关系推导出两个总体之间的关系,能用于推断两个总体方差之间的比值关系。
F统计量:两个正态分布总体,总体方差为
F分布有两个自由度,分子自由度为v1=(n1-1),分母自由度为v2=(n2-1),因此,由F统计量组成的F分布可以表示为:(F统计量可看成是由两个卡方统计量相除得到的,F分布也被称为方差比分布,假设两个正态分布总体的卡方统计量为
三、用pyhton分析数据集的抽样分布
数据集:数据有四列 ID、年龄、价格、港口,
操作环境:jupyter notebook
分析一:按照港口分类,求出各类港口数据年龄和价格的统计量(包括均值、方差、标准差、变异系数等)
1.导入数据
import numpy as np
import pandas as pd
df=pd.read_excel("C:/../data.xlsx",index_col=0,header=0,encoding="utf-8-sig")
print(df)2.求统计量
df.groupby("Embarked").describe( )
df.groupby("Embarked").mean( ) #求均值
df.groupby("Embarked").var( ) #求方差
df.groupby("Embarked").std( ) #求标准差
#求变异系数
df1=df.groupby("Embarked").std( )
df2=df.groupby("Embarked").mean( )
df3=df1/df2
print(df3)分析二:画出价格的分布图像,验证数据服从何种分布?正态/卡方/T分布?
1.价格数据的分布图像
import matplotlib.pyplot as plt
#让图表直接在jupyter notebook中展示出来
%matplotlib inline
#解决中文乱码问题
plt.rcParams["font.sans-serif"]='SimHei'
#解决负号无法正常显示的问题
plt.rcParams['axes.unicode_minus']=False
#绘制价格数据的密度直方图
df["Fare"].hist(bins=10,alpha=0.7)
df["Fare"].plot(kind='kde',secondary_y=True)
plt.xlabel("价格")
plt.ylabel("密度")
plt.title('密度直方图')
plt.legend()
plt.show()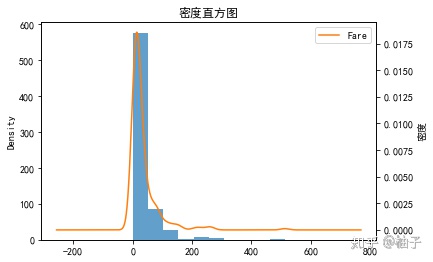
2.检验价格数据是否服从正态分布
先用kstest方法检验数据是否服从正态分布
from scipy import stats
u = df["Fare"].mean()
std = df["Fare"].std()
stats.kstest(df["Fare"].values,'norm',args=(u,std))
结果: KstestResult(statistic=0.28363501066241253, pvalue=0.0)
因为p<0.05,故价格不服从正态分布2.检验价格是否服从卡方分布
可用ks_2samp检验两个样本是否服从同一分布来检验价格数据是否服从卡方分布或者T分布
fare=df["Fare"].copy().values
df,loc,scale=stats.chi2.fit(fare)
x2=stats.chi2.rvs(df=df,loc=loc,scale=scale,size=len(fare))
ks, p=stats.ks_2samp(fare,x2)
print("ks=%.4f,p=%.4f" % (ks,p))
结果:ks=0.1756,p=0.0000
因为p<0.05,所以拒绝两个样本服从同一分布的假设,故价格不服从卡方分布3.检验价格是否服从T分布
df,loc,scale=stats.t.fit(fare)
x1=stats.t.rvs(df=df,loc=loc,scale=scale,size=len(fare))
ks, p=stats.ks_2samp(fare,x1)
print("ks=%.4f,p=%.4f" % (ks,p))
结果:ks=0.2823,p=0.0000
因为p<0.05,所以拒绝两个样本服从同一分布的假设,故价格不服从T分布分析三:按照港口分类,验证S和Q两个港口间的价格之差是否服从某种分布
先看数据中的港口类别及个数
df["Embarked"].value_counts()
结果:S 554
C 130
Q 28获取各个类别港口的价格数据:
s_fare=df[df["Embarked"]=="S"]["Fare"].copy().values
q_fare=df[df["Embarked"]=="Q"]["Fare"].copy().values
c_fare=df[df["Embarked"]=="C"]["Fare"].copy().values虽然价格总体数据不服从正态分布,但是当样本容量n比较大时(一般n>=30),两个样本均值之差的抽样分布近似为正态分布。
但是从以上港口类别数据来看,Q港口的样本容量小于30,因此S和Q港口两个样本数据均值之差的抽样分布不能近似服从正态分布,而S和C港口两个样本数据均值之差的抽样分布近似服从正态分布。
mu=np.mean(s_fare)-np.mean(c_fare)
sigma=np.sqrt(np.var(s_fare,ddof=1)/len(s_fare) + np.var(c_fare,ddof=1)/len(c_fare))
print(mu)
print(sigma)
#结果:-40.820482446542634
8.0927962600833
# 绘制密度曲线
x=np.arange(-80,0)
y=stats.norm.pdf(x,mu,sigma)
plt.plot(x,y)
plt.xlabel("s c港口价格之差")
plt.ylabel("密度")
plt.title("s和c港口价格之差的密度曲线")
plt.show()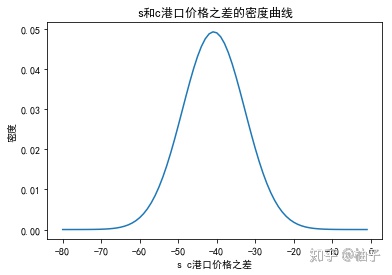
可看出,S和C 港口之间的价格之差服从正态分布。
部分参考: https://github.com/Emerald-Stejneger/data_tea_break/blob/master/com/study_team/6th_week/Titanic_analysis.py














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









