






 信度是评估测量工具可靠性的指标,关注测量结果的一致性。内在信度考察问题间的一致性,外在信度关注不同时间测量的一致性。Cronbach α系数和折半信度是衡量内在信度的常见方法,信度系数高于0.7被认为是可接受的。在数据分析中,信度分析用于确保调查问卷结果的可靠性和准确性。
信度是评估测量工具可靠性的指标,关注测量结果的一致性。内在信度考察问题间的一致性,外在信度关注不同时间测量的一致性。Cronbach α系数和折半信度是衡量内在信度的常见方法,信度系数高于0.7被认为是可接受的。在数据分析中,信度分析用于确保调查问卷结果的可靠性和准确性。
收集数据时,常出现三种测量误差。
一、系统误差。如秤本身的误差,使测量结果与真实情况产生误差,这次误差在多次测量中通常比较稳定。
二、随机误差,即在相同条件下,多次测量同一量时出现单个无规律性的、不可预知的误差,随着测量次数增加,误差逐渐降低,即具有抵偿性的误差。
三、粗差,即粗心带来的错误。如歪曲测量结果的误差。称为坏值或异常值,在分析中可作误差分析剔除。异常值要注意某些异常值会含有重要信息。如:研究的新发现。
测量中的误差使得测量结果不完全一致,会产生两类问题:
- 测量结果一致性程度问题
如:不同条件下所得数据的关系如何?测量数据与真实数据的接近程度如何?
2. 造成测量数据变异的原因问题
如:是什么因素造成了数据的不一致性?各种因素产生效应的相对比例如何?
问题1中估计结果的精确度,反映随机误差大小的程度的问题。即是用“信度”概念来描述的。
信度是用来测量工具可靠性的指标,它用来对测量一致性程度进行估计。如果说某测量工具是可靠的,则表示这一工具在测量多次时,其测量结果是一致而稳定的。
信度用公式表示就是:

公式含义为:在一组测试分数中:真实值的方差和实得数据方差的比。

指测试的信度;

指真实值的样本方差;

指实得数据的样本方差。
信度类型
在数据分析中,信度分析常用于调查问卷。即在对问卷结果进行统计分析之前先对问卷的信度(reliability)、效度(validity)进行分析,确保分析结果是可靠和准确的。
信度分为内在信度和外在信度。
- 内在信度:指调查问卷中的一组问题(或整个调查表)是否测量的是同一个主题,即问题间的内在一致性如何。
- 内在信度系数0.8以上,可以认为调查表有较高的内在一致性。常用的内在信度系数为Cronbach α系数和折半信度。
- Cronbach α系数判断量表的内部一致性,可被看作相关系数,即该量表与所有含有其他可能项目数的量表之间的相关系数。其大小可以反映量表受随机误差影响的程度,反映测试的可靠程度。系数值越大,则量表受随机误差的影响较小,测试可靠。
- 折半信度是将调查题目分为两半,然后计算两部分各自的信度以及它们之间的相关性,以此为标准来衡量整个量表的信度,相关性高则表示信度好,相应的信度指标即为折半信度。
2. 外在信度:指在不同时间进行测量时调查问卷结果的一致性程度。最常用的外在信度指标是重测信度,即用同一问卷在不同时间对同一对象进行重复测量,然后计算一致程度。
信度结果
没有标准规定信度系数应当达到多少就表示调查问卷具备可信度,一般认为:
- 信度系数大于0.9,信度佳;
- 信度系数0.8~0.9之间,可接受;
- 信度系数0.7~0.8之间,该调查问卷应进行修订,但仍有价值;
- 信度系数低于0.7,调查问卷要重新设计
信度分析主要应用在用多个指标反映对象的研究中,通过对多维变量进行降维,达到既不影响研究对象,又降低研究难度的作用。
要注意的是,在复杂调查问卷中,往往包含多个调查主题,每一主题由一组问题来集中测量并获取信息。此时的信度分析应按问题组进行,即测量同一主题的一组问题之间的信度如何,而不是直接测量整个问卷信度。
关于系统误差大小程度的评估,使用的是效度概念。
效度是对一个测量工具所要测量的东西能测量到什么程度的估计,即测量值和真实值的接近程度。是描述工具有效性的指标,说明该测量工具的正确性程度。
效度分为表面效度、内容效度、结构效度,结构效度通过主成分分析来求得。效度高,信度一定高;但信度高,效度不一定高。
案例
某职业考评中44名工作人员的成绩见下表,其中:
- A-填空题(18分)
- B-选择题(12分)
- C-简答题(30分)
- D-计算题(10分)
- E1-综合题一(15分)
- E2-综合题二(15分)。
对考试试卷进行信度分析。
考试成绩
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| A | 12 | 12 | 14 | 14 | 15 | 15 | 14 | 13 | 15 | 14 | 15 | 14 | 14 | 15 | 16 |
| B | 10 | 8 | 9 | 8 | 9 | 9 | 10 | 9 | 11 | 10 | 10 | 9 | 10 | 10 | 10 |
| C | 18 | 15 | 15 | 16 | 14 | 15 | 14 | 13 | 17 | 16 | 19 | 18 | 18 | 20 | 22 |
| D | 5 | 7 | 6 | 6 | 5 | 5 | 6 | 10 | 5 | 4 | 7 | 10 | 10 | 7 | 8 |
| E1 | 0 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 7 | 9 | 5 | 7 | 7 | 10 | 5 |
| E2 | 0 | 0 | 0 | 0 | 5 | 5 | 6 | 10 | 9 | 13 | 13 | 13 | 13 | 11 | 12 |
| 编号 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| A | 16 | 16 | 16 | 15 | 17 | 16 | 15 | 17 | 15 | 15 | 16 | 16 | 17 | 16 | 17 |
| B | 10 | 11 | 11 | 10 | 12 | 12 | 11 | 11 | 11 | 12 | 11 | 11 | 11 | 10 | 11 |
| C | 23 | 19 | 22 | 21 | 23 | 23 | 26 | 22 | 24 | 23 | 24 | 25 | 26 | 22 | 21 |
| D | 4 | 7 | 10 | 10 | 4 | 9 | 7 | 8 | 9 | 10 | 8 | 8 | 10 | 9 | 9 |
| E1 | 7 | 10 | 5 | 9 | 8 | 9 | 9 | 10 | 10 | 10 | 12 | 13 | 8 | 15 | 15 |
| E2 | 14 | 12 | 12 | 11 | 13 | 10 | 11 | 12 | 13 | 12 | 12 | 11 | 12 | 13 | 12 |
| 编号 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | |
| A | 17 | 17 | 16 | 16 | 16 | 17 | 16 | 17 | 17 | 17 | 16 | 17 | 18 | 17 | |
| B | 11 | 10 | 11 | 11 | 11 | 10 | 11 | 10 | 11 | 12 | 11 | 10 | 11 | 10 | |
| C | 30 | 26 | 24 | 25 | 27 | 25 | 25 | 30 | 25 | 29 | 30 | 28 | 30 | 30 | |
| D | 10 | 8 | 8 | 7 | 7 | 9 | 10 | 8 | 10 | 10 | 10 | 10 | 8 | 10 | |
| E1 | 7 | 13 | 12 | 15 | 12 | 15 | 15 | 12 | 13 | 10 | 13 | 15 | 15 | 15 | |
| E2 | 10 | 13 | 15 | 13 | 14 | 12 | 12 | 13 | 14 | 13 | 12 | 15 | 13 | 13 |
分析过程:
- 以A、B、C、D、E1、E2为变量,整理上表中数据为行44 列6的数据文件。
- 使用SPSS进行信度分析。
a. 选择菜单Analyze→Scale→Reliability Analysis,Reliability Analysis主对话框(图15-1)将变量A、B、C、D、E1、E2加入Items框中。
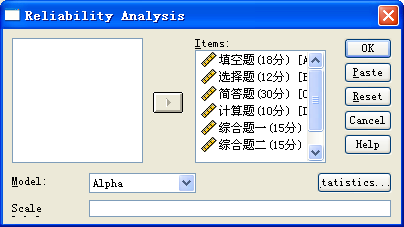
Model下拉列表中有5个信度模型,即不同的信度系数:
- Alpha:即最常用的Cronbach α系数。
- Solit-half:折半信度。
- Guttman:该模型计算真实信度的Guttman’s下界,输出结果中的Lambda3就是Cronbach α系数。
- Parallel:平行模型,该模型采用最大似然估计方法计算信度系数,它要求所有变量的方差齐,并且所有重测间的变异相等。
- Strict parallel:严格平行模型,该模型也是采用最大似然估计方法计算信度系数,在平行模型的基础上还要求各变量的均数相等。
b. 打开Statistics对话框(15-2)。
选中Statistics对话框中Item、Scale和Scale if item deleted三项,单击Continue并确认完成设置。
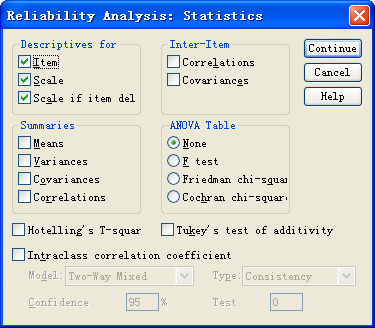
- Descriptives for:描述统计量。
Item:描述项目,给出各项目的均数、标准差和样本量。
Scale:描述总分;给出各项目总分的均数、方差、标准差和项目数。
Scale if item deleted:删除当前项目后问卷相应指标的改变情况,即敏感性分析。这一选项很重要,可以用来对问卷中的各项进行逐一分析,以达到改良问卷的目的。
- Inter-item:项目间的相关矩阵和协方差阵。
Correlations:项目之间的相关矩阵;
Covariances:项目之间的协方差阵。
- Summaries:对所有参与分析变量的二次指标再进行描述分析,可选择的二次指标有所有项目的Means(均数)、Variances(方差)、Covariances(协方差)和Correlations(相关系数)。以均数为例,在输出时会给出所有项目均数的均数、最大值、最小值、标准差、全矩、最大值与最小值之比和方差。
- ANOAV Table:分析不同评分者对问卷评分的影响。
None:不进行分析。
F test:对各变量进行重复测量的方差分析,该方法适用于项目分值均呈正态分布时,等价于调用GLM中的重复测量方差分析过程。
Friedman chi-square:对各变量进行配伍设计的非参数分析,该方法适用于项目分值不呈正态或为有序分类时,等价于调用非参数分析中的K Related Samples过程。
Cochran chi-square:对各变量进行Cochran’s卡方检验,该方法适用于项目分值为二分类或无序分类时。
- Hotelling’s T-square:Hotelling’s T2检验,是t检验向多元情况的推广,此处的目的是检验各项目的总体均数是否相等。
- Tukey’s test of additivity:检验各项目得分之间是否存在相加作用的交互作用。
- Intraclass correlation coefficient:组内相关系数(ICC)。采用随机效应模型分析各变量间的相关性。
C. 查看输出结果(15-3、15-4、15-5)。
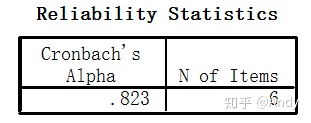
15-3给出Cronbach α 信度系数:0.823,表示该考卷的内部信度比较好。
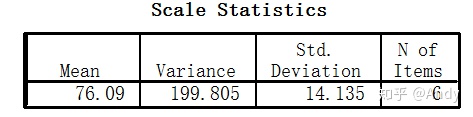
15-4给出6个项目总分的均数、方差和标准差。
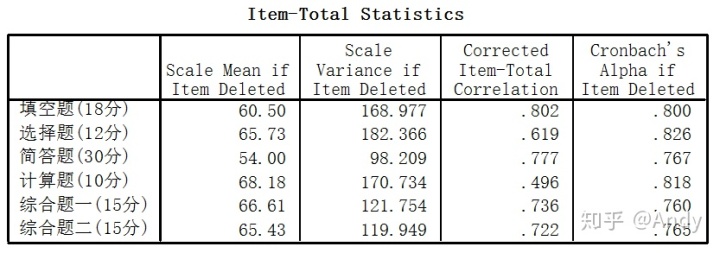
15-5给出的是如果将相应的项目(题目)删除,则试卷总的信度会如何改变,包括:总分的均数改变、方差改变、该题与总分的相关系数和Cronbach α系数的改变情况。
最重要是后两项,如果相关系数太低,可考虑将该题删除。
观察结果不难看出:计算题(D)的相关系数非常低,即该题得分高低和总分高低相关性不大,该题在难度设计上不当,无法区分出学生水平。如果删除该题Cronbach α系数相对较大,则该题删除可提高试卷的信度,
输出结果显示,选择题(B)和计算题(D)的Cronbach α指标较高,原因结果分析在于选择题(B)是送分题,参考人员答得都比较好,无法区分出优劣;而计算题(D)可能出的偏,就算优秀的人员也不一定该题得分高。
根据结果可知,对该试卷进行优化调整可以将选择题(B)和计算题(D)更换或删除。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









