






准备数据
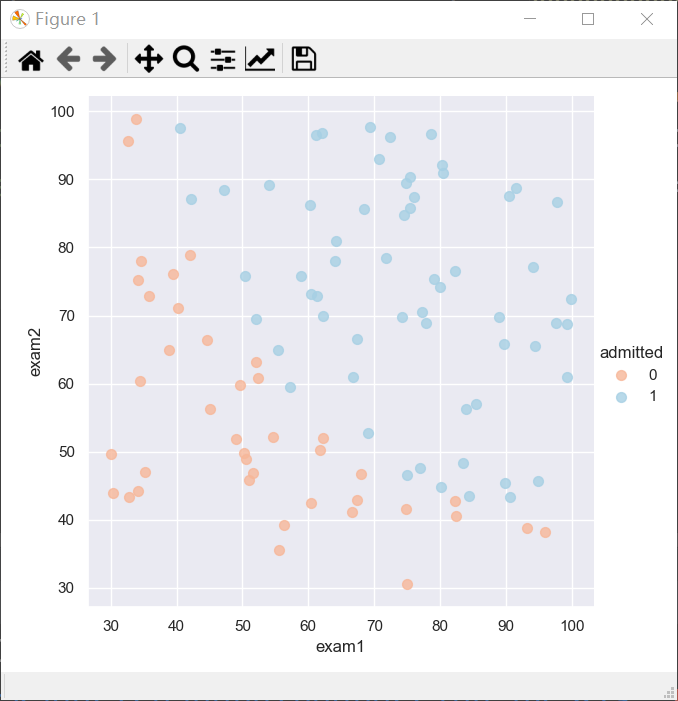
data1的数据是学生两个学期的成绩exam1,exam2和是否能被录取admitted
把作业的data1数据导入,画出图形
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')#一种绘图风格
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report#这个包是评价报告
data=pd.read_csv(r'D:\MachineLearning\ex2\ex2_data1.txt',names=['exam1','exam2','admitted'])
sns.set(context='notebook',style='darkgrid',palette=sns.color_palette('RdBu',2))
sns.lmplot('exam1','exam2',hue='admitted',data=data,size=6,fit_reg=False,scatter_kws={'s':50})
plt.show()
运行结果如下:
 读取数据
读取数据
#读取特征
def get_X(df):
ones=pd.DataFrame({'ones':np.ones(len(df))})#ones是m行1列的dataframe
data=pd.concat([ones,df],axis=1)#合并数据,axis=1是列合并,=0是行合并。concat对大型数据集来说效率不高
return data.iloc[:,:-1].values
#读取标签
def get_y(df):
return np.array(df.iloc[:,-1])#取所有行和取最后一列
#特征缩放
def normalize_feature(df):
return df.apply(lambda column:(column-column.mean())/column.std())#apply是应用到每个数据,lambda是匿名函数
sigmoid函数
 根据定义画出sigmoid函数图形
根据定义画出sigmoid函数图形
#sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
fig,ax=plt.subplots(figsize=(8,6))
ax.plot(np.arange(-10,10,step=0.01),sigmoid(np.arange(-10,10,step=0.01)))
ax.set_ylim((-0.1,1.1))#y轴的刻度范围从-0.1到1.1
ax.set_xlabel('z',fontsize=18)
ax.set_ylabel('g(z)',fontsize=18)
ax.set_title('sigmoid funciton',fontsize=18)
plt.show()
结果如图:
 计算代价函数
计算代价函数
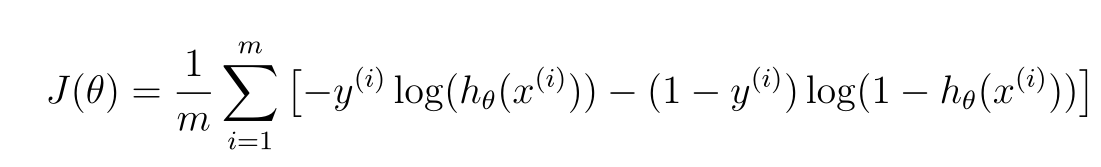
theta=np.zeros(3)#因为X(m*n)所以theta是n*1
def cost(theta,X,y):
return np.mean(-y*np.log(sigmoid(X@theta))-(1-y)*np.log(1-sigmoid(X@theta)))#X@theta与X.dot(theta)等价
print(cost(theta,get_X(data),get_y(data)))
输出的结果是0.69314718055994529
梯度下降
公式如下:
 这里不像之前那样,写一个循环和设置一个学习率α,这里用到python里的fmin函数可以直接计算得到最优参数θ,实现如下:
这里不像之前那样,写一个循环和设置一个学习率α,这里用到python里的fmin函数可以直接计算得到最优参数θ,实现如下:
导入scipy包:
import scipy as sp
#梯度下降
def optimizeTheta(theta,X,y):
result=sp.optimize.fmin(cost,x0=theta,args=(X,y),maxiter=400,full_output=True)
return result[0],result[1]
theta,mincost=optimizeTheta(theta,get_X(data),get_y(data))
print(cost(theta,get_X(data),get_y(data)))
运行结果如下:
得到最优参数θ:0.20349
 用训练集预测和验证
用训练集预测和验证
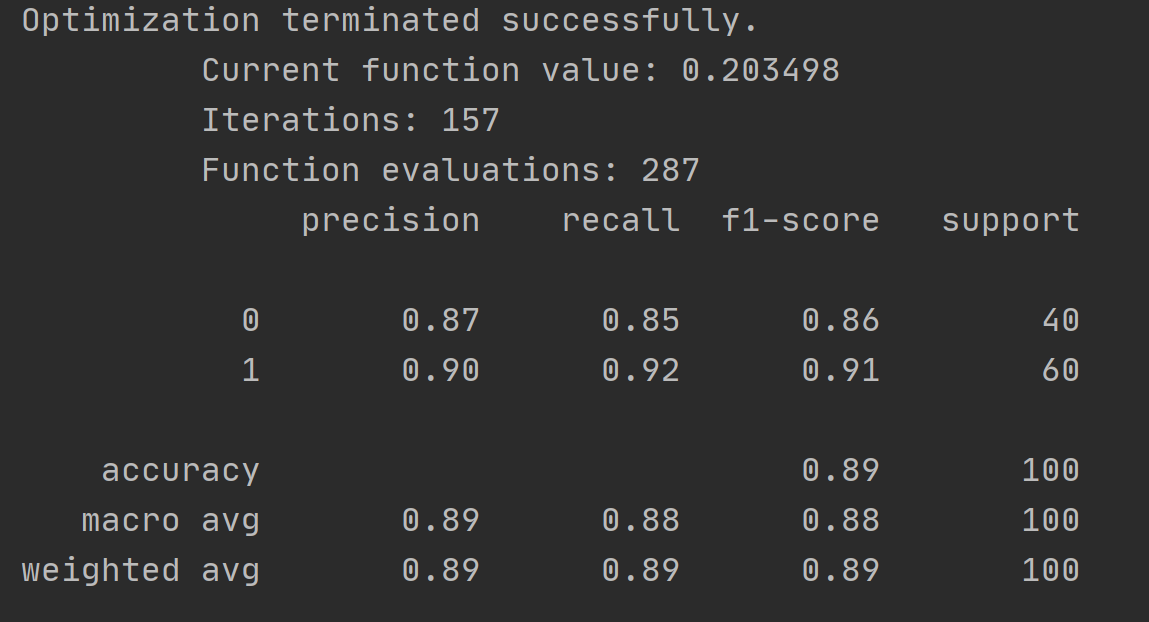
#用训练集预测和验证
def predict(x,theta):
prob=sigmoid(x@theta)
return (prob>=0.5).astype(int)
y_pred=predict(get_X(data),final_theta)
print(classification_report(get_y(data),y_pred))
运行结果如下:
 其中classification_report函数的详解可以参考这篇文章:https://blog.csdn.net/akadiao/article/details/78788864
其中classification_report函数的详解可以参考这篇文章:https://blog.csdn.net/akadiao/article/details/78788864
预测样本
预测样本的入学概率
#预测样本exam1:45,exam2:85的入学概率
print(sigmoid(np.dot(final_theta,[1,45,85])))#1是x0
运行结果是0.7762915904112411
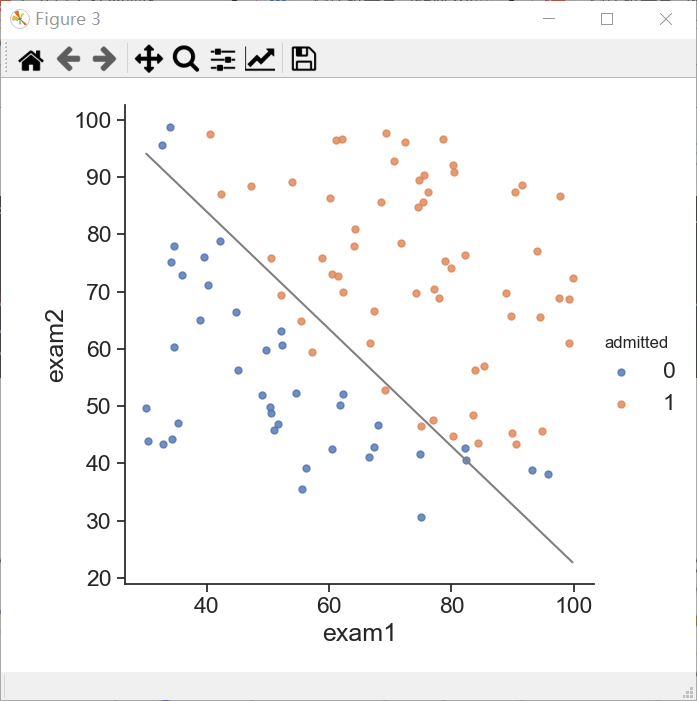
决策边界
类似 ax+by+c= 0,求出y即可。
#绘制决策边界
sns.set(context='notebook',style='ticks',font_scale=1.5)
sns.lmplot('exam1','exam2',hue='admitted',data=data,size=6,fit_reg=False,scatter_kws={'s':25})
boundary_x=np.array([np.min(get_X(data)[:,1]),np.max(get_X(data)[:,1])])
boundary_y=(-1./final_theta[2]*(final_theta[0]+final_theta[1]*boundary_x))
plt.plot(boundary_x,boundary_y,'grey')
plt.show()
 正则化逻辑回归
正则化逻辑回归
data2是芯片经过两个测试后是否能通过
先是画出数据集的图形
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')#一种绘图风格
import matplotlib.pyplot as plt
data=pd.read_csv(r'D:\MachineLearning\ex2\ex2_data2.txt',names=['test1','test2','accepted'])
#绘制出图形
sns.set(context='notebook',style='ticks',font_scale=1.5)
sns.lmplot('test1','test2',hue='accepted',data=data,size=6,fit_reg=False,scatter_kws={'s':50})#scatter_kws's'点的大小
plt.title('Regularized Logistic Regression')
plt.show()

特征映射
之所以进行特征映射,是因为特征映射的好处在于从每个特征中能创造出更多的特征。
#特征映射
def feature_mapping(x,y,power,as_ndarray=False):
data={"f{}{}".format(i-p,p):np.power(x,i-p)*np.power(y,p)
for i in np.arange(power+1)
for p in np.arange(i+1)}
if as_ndarray:
return pd.DataFrame(data).as_matrix()
else:
return pd.DataFrame(data)
x1=np.array(data.test1)
x2=np.array(data.test2)
data=feature_mapping(x1,x2,power=6)
正则化代价函数
正则化的原因是因为特征映射的过程中生成了太多高次项,当模型的特征(feature variables)非常多,而训练的样本数目(training set)又比较少,会出现过拟合的问题。如果我们发现了过拟合问题,应该如何处理?
1、丢弃一些不能帮助我们正确预测的特征。
2、正则化。保留所有的特征,但是减少参数θ的大小。
选择正则化,就需要减少高幂次的特征变量的影响,为此我们引入的罚项,假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚。
公式如下:
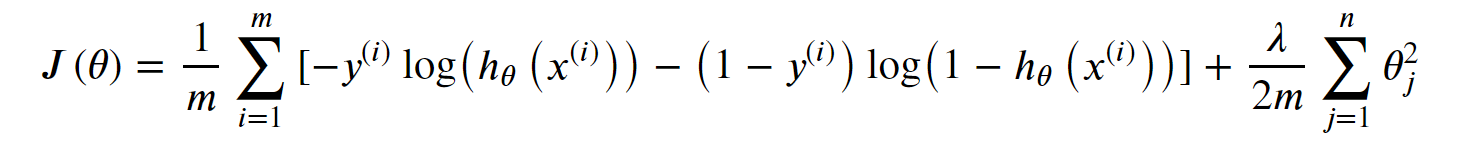
#正则化代价函数
def sigmoid(z):
return 1/(1+np.exp(-z))
def cost(theta,X,y):
return np.mean(-y*np.log(sigmoid(X@theta))-(1-y)*np.log(1-sigmoid(X@theta)))
def get_y(df):
return np.array(df.iloc[:,-1])
theta=np.zeros(data.shape[1])
X=feature_mapping(x1,x2,power=6,as_ndarray=True)
#print(X.shape)
y=get_y(data)
#print(y.shape)
def regularized_cost(theta,X,y,l=1):
theta_j1_to_n=theta[1:]
regularized_term=(1/(2*len(X)))*np.power(theta_j1_to_n,2).sum()
return cost(theta,X,y)+regularized_term
print(regularized_cost(theta,X,y,l=1))
输出结果:0.69314718055
本文地址:https://blog.csdn.net/LunaLee38/article/details/110622495
希望与广大网友互动??
点此进行留言吧!















 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









