







社会学家、心理学家和消费者研究人员在分析多元数据时,常常会遇到这样的问题:应该使用主成分分析(PCA)还是探索性因子分析(EFA)呢?选择不当可能导致错误的结果或者对数据的错误理解。
在我们过往的推文《这样的数据分析员才有时间谈恋爱?》中,我们已经从概念、区别及各自的使用优势上向大家介绍了主成分分析和因子分析的区别。今天,我们将借助于JMP平台进一步解释PCA和EFA之间的关键区别,帮助大家掌握并思考何时使用最适合的方法来解决最相关的问题。(需要本案例JSL的小伙伴,可私信留下邮箱及信息,小编发你哦~)
本文原作者Laura Castro Schilo,JMP研发统计开发员,原博文发表在JMP全球用户社区,感兴趣的小伙伴也可以看原帖:https://community.jmp.com/t5/JMP-Blog/Principal-components-or-factor-analysis/ba-p/38347
01 从一个小案例谈起
为了举例说明,我们首先创建一组符合标准正态分布的数据表,包含1000个观测变量和互不相关的4个变量。
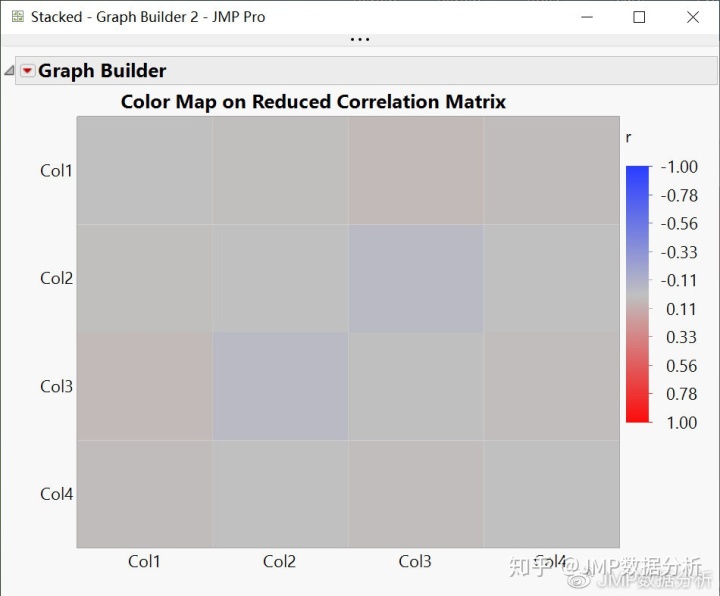
打开JMP软件的多元平台(JMP菜单:多元分析->多元),观看变量之间的相关性。通过相关性色图(图1),我们可以看到非对角线的相关系数都接近于0,这说明变量之间相互独立。

那么问题来了:如果在这些数据上执行PCA,结果会是怎样?如果执行EFA,结果又会是怎样?
02 PCA VS EFA
打开JMP的因子分析平台,同时对数据集执行PCA和EFA。需要说明的是,因为只有四个变量,这里我们只保留一个因子。另外,不采用任何的因子旋转。之后得到如图2所示的PCA和EFA的因子载荷矩阵。
因子载荷,测量的是主成分或公因子对变量的影响,可以帮助我们理解主成分或公因子代表的到底是什么。载荷的绝对值越接近1,主成分或公因子对变量的影响就越大。通常定义为绝对值≥0.4为高载荷,因为这表明至少16%的测量变量方差与因子的方差重叠。具有高载荷的变量最能代表主成分或公因子。
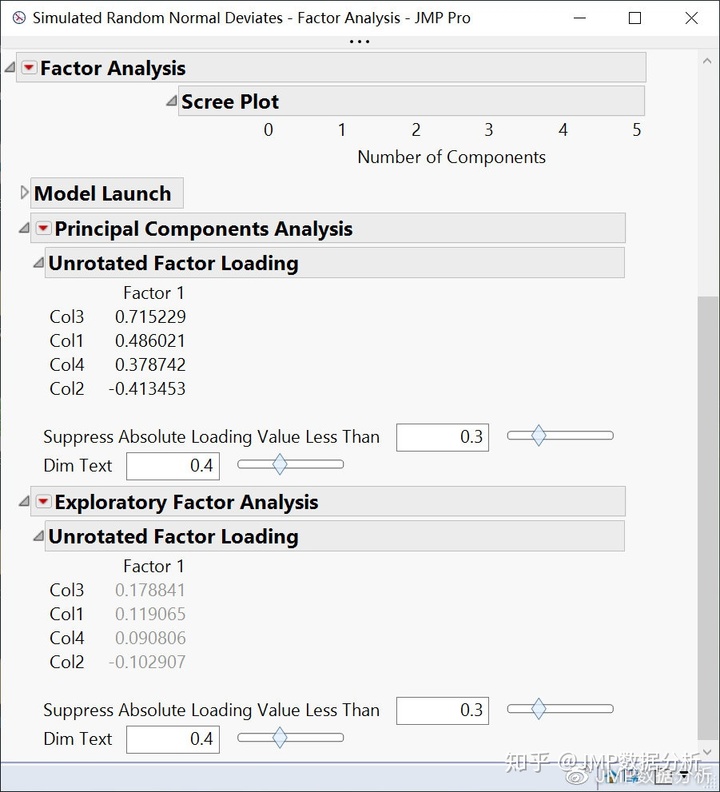
对比PCA和EFA的因子载荷矩阵,我们不难发现两者截然不同!PCA给了我们三个绝对值大于0.4的载荷,而EFA没有给出任何高载荷。
为什么结果会截然不同呢?
03 截然不同的两种结果,为什么?
这是因为当我们执行EFA时,本质上是针对简化相关性矩阵执行特征值分解。简化相关性矩阵是对角线元素被多重相关的平方 (SMC) 系数取代的相关性矩阵。
实际上,相关性色图也揭示了为什么会得到这样不同的结果。
在这个例子中,简化相关性矩阵中的每个元素都是非常小,几乎为零。对于PCA,特征值分解是在完全相关性矩阵(图1)上完成的,但对于EFA,特征值分解在简化相关性矩阵(图3)上完成的。
因此,计算方法的差异解释了不同分析的结果差异,但我们还需要从实际解决问题的角度来看看这些差异意味着什么。
04 有何实际意义?
PCA和EFA有不同的目标:PCA是一种降低数据维度的技术,而EFA是一种识别无法直接测量的变量(即潜在变量或因子)的技术。
因此,在PCA中,数据的所有方差由完全相关性矩阵反映,都用于计算以获得结果,最终所得到的主成分是变量所要测量的方差和其他方差来源(例如测量误差)的混合(见图4的左图)。
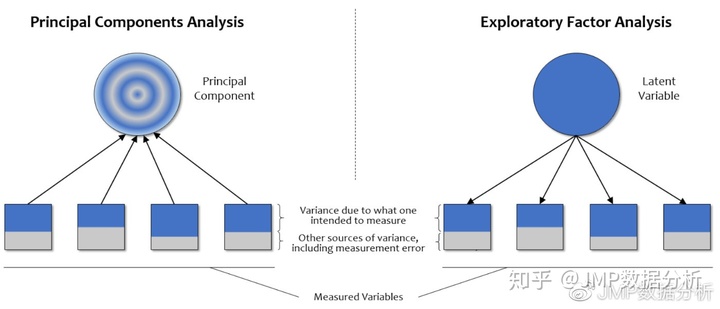
相比之下,在EFA中,并非数据的所有方差都来自潜在变量(见图4的右图)。EFA算法通过用SMC值“减少”相关性矩阵来体现这一特征,因为SMC是潜在因子在给定变量中所解释的方差的估计。如果我们以对角线为单位执行EFA,那么就意味着这些因子可以解释所测变量的所有方差,我们做的将是PCA而不是EFA。
图4还说明了PCA和EFA之间的另一个重要区别。请注意, PCA中的箭头从所测量的变量指向主成分,而在EFA中箭头则是相反的方向。箭头表示因果关系,因此PCA中测量变量的变异导致主成分的变异。这与EFA相反,EFA的潜在因子被视为导致被测变量之间相关性的变化和模式(Marcoulides&Hershberger,1997)[1]。
为了清楚起见,我们总结了一些观察结果。
- 首先,大多数多元数据都具有一定程度的相关性,因此PCA和EFA之间的差异不会像本例中那样明显。
- 其次,随着分析中所涉及的变量数量的增加,PCA和EFA的结果会变得越来越相似。研究人员认为,至少有40个变量的分析只会导致细微的差异(Snook&Gorsuch,1989)[2]。
- 第三,如果测量变量的共同性很高,那么PCA和EFA之间的结果也是相似的。
- 最后,这个例子依赖于“主轴”分解方法,但也存在其他估计方法,其结果可能会有所不同。
当分析师在EFA和PCA之间做出选择时,必须考虑所有这些观察结果。但是对于心理学家(最先开发EFA的人)来说,最重要的也许是EFA提出了关于所分析变量的理论。这种理论可以追溯到Spearman(1904)[3],他提出未观察到的因子决定了我们能够直接测量的因子。
下面列出了一些关键要点,希望对大家有所启发。Widaman(2007)[4] 是继续学习此主题的一个很好的资源。
05一些要点与思考
- PCA可用于减少变量的数量,同时保留数据中的最多信息,而EFA可用于测量未观察到的(潜在的)无误差变量。
- 当变量没有任何共同点时,如上例所示,EFA将找不到定义明确的潜在因子,但PCA会找到定义明确的主成分,以此来解释数据中的最大方差。
- 当目标是测量无误差的潜在变量但使用了PCA时,成分的载荷很可能高于使用EFA时的载荷。这会使得分析人员误以为他们有一个定义明确、没有误差的因子,而实际上他们有一个明确定义的成分,即数据中所有方差来源的混合物。
- 当目标是获取一小部分变量,这些变量保留了数据中的大部分变异,但使用了EFA时,因子载荷可能会比使用PCA时要低。这将使得分析人员误以为他们保留了数据中最大的方差,而实际上他们却保留了所有被测变量的共同方差。
参考文件
[1] Marcoulides, G.A., & Hershberger, S. L. (1997). Multivariate statistical methods: Afirst course. Psychology Press.
[2] Snook, S. C.,& Gorsuch, R. L. (1989). Component analysis versus common factor analysis:A Monte Carlo study. Psychological Bulletin, 106, 148-154.
[3] Spearman, C.(1904). "General intelligence," objectively determined andmeasured. The American Journal of Psychology, 15, 201-293.
[4] Widaman, K. F.(2007). Common factors versus components: Principals and principles, errors andmisconceptions. Factor analysis at 100: Historical developments and futuredirections, 177-203.
最后,如果你也想体验基于JMP的PCA和EFA分析,欢迎点击这里下载JMP 30天免费试用;
如果需要文中案例JSL代码的小伙伴,请私信或下方留言留下邮箱及信息,我们发送给你。
















 9148
9148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









