







简介:Lingua::RU::Inflect是Perl模块中的俄语变位工具,特别适用于处理复杂语法的俄语文本。该模块能高效、灵活地处理俄语名词、形容词和代词的变形,支持不同的语法格和数的变化,并能够自动识别并应用这些规则。它简化了俄语文本处理,适用于构建自然语言处理系统和Web应用。模块还支持动词时态和语态变化,并提供扩展功能。源代码开放,便于开发者研究和自定义。Lingua::RU::Inflect是Perl开发者在处理俄语任务中的得力助手,提高了代码的可读性和效率。 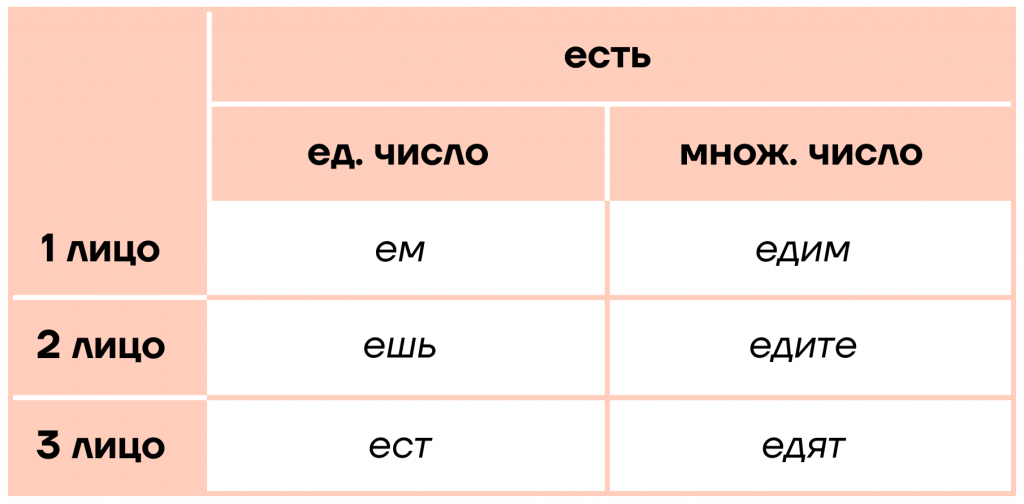
1. Perl模块处理俄语变形
简介
俄语作为世界上最广泛的语言之一,拥有复杂的语法结构和丰富的变位规则。为了在计算机程序中处理俄语文本,开发人员经常需要应对名词、动词、形容词和副词的变形问题。Perl作为一种功能强大的编程语言,配合特定的模块,可以有效地解决这些问题。
使用Perl模块的优势
通过Perl模块,程序员能够简洁地实现俄语的变格和变位功能。这类模块通常提供了丰富的接口,允许开发者在不深入了解俄语语法细节的情况下,快速实现文本的处理和转换。此外,模块还支持自动化处理,提高开发效率,减少重复性劳动。
Perl模块的选择与应用
在处理俄语变形时, Lingua::RU::Inflect 是一个广泛使用的Perl模块。它提供了强大的接口,能够对俄语名词、动词、形容词和副词进行变形处理。下一章我们将深入探讨 Lingua::RU::Inflect 模块的功能和使用方法,以及如何解决在处理过程中可能遇到的问题。
2. 俄语语法和变位规则
2.1 俄语名词的变格系统
2.1.1 名词的性别、数和格的变化
俄语名词的变格系统是俄语语法中最为核心的部分之一,它包含了名词的性别、数和格的变化。这三个要素是名词在句中地位变化的体现。在俄语中,名词有三性(阴性、阳性和中性)、两数(单数和复数),以及六个格(主格、宾格、与格、属格、工具格和前置格)的变化。
- 性别 :俄语名词的性别非常关键,因为它影响着形容词、数词和代词的变格。阴性名词通常以"-а"或"-я"结尾,阳性名词以辅音结尾,中性名词则以"-о"或"-е"结尾。每个性别的名词在变化时,与之相连的词也需要相应地变化。
- 数 :名词的数分为单数和复数。多数情况下,复数形式是通过在单数形式后添加特定后缀来构成的,例如"-ы"或"-и"。
- 格 :名词的格变化用于表示名词在句子中的功能,如主语、直接宾语、间接宾语等。每个格都有其特定的后缀,这与名词的性别和数紧密相关。
由于名词变格的重要性,在编写任何涉及俄语的程序时,正确处理这些变化是至关重要的。
下面通过一个表格来展示不同性别名词变格的实例:
| 性别/格 | 单数主格 | 单数宾格 | 单数与格 | 单数属格 | 单数工具格 | 单数前置格 | |---------|-----------|-----------|-----------|-----------|-------------|-------------| | 阴性 | книга | книгу | книге | книги | книгой | книгe | | 阳性 | стол | стол | столу | стола | столом | столе | | 中性 | окно | окно | окну | окна | окном | окне |
2.1.2 特殊名词变格案例分析
除了上述的规则变化之外,俄语中还存在着特殊名词,其变格过程并不遵循一般规则,需要单独记忆。例如,一部分不规则名词和专有名词、外来词的变格通常与普通名词有所区别。
考虑以下名词变格的例子,它显示了不规则名词"женщина"(女人)的变格过程,其变格方式与普通阴性名词有所不同:
| 单数主格 | 单数宾格 | 单数与格 | 单数属格 | 单数工具格 | 单数前置格 | |-----------|-----------|-----------|-----------|-------------|-------------| | женщина | женщину | женщине | женщины | женщиной | женщине |
了解这些特殊名词的变格对于俄语自然语言处理至关重要,尤其是在自动化文本分析和生成的场合。
2.2 俄语动词的时态和语态
2.2.1 动词的变位基础
俄语动词的变化涉及时态、语态、人称和数的组合,具有相当的复杂性。掌握俄语动词的变位是正确使用和理解俄语的关键。
动词变位的规则非常严格,需要根据动词的类型和所要表达的时间意义来变化。动词的变位包括人称后缀的添加以及词干的变化。基本规则适用于规则动词,但许多常用动词属于不规则动词,需要特别记忆。
下面是一个俄语动词变位的流程图,用于展示一个规则动词在不同人称和数的变位过程:
graph TD
A[动词原型] --> B[第一人称单数]
A --> C[第二人称单数]
A --> D[第三人称单数]
A --> E[第一人称复数]
A --> F[第二人称复数]
A --> G[第三人称复数]
以动词"читать"(读)为例,其第一人称单数形式是"читаю"。以下是动词"читать"在不同人称和数的变位:
| 人称/数 | 单数 | 复数 | |---------|-------|-------| | 第一人称 | читаю | читаем | | 第二人称 | читаешь | читаете | | 第三人称 | читает | читают |
2.2.2 不规则动词的变位特点
不规则动词的变位没有统一的规则可寻,它们通常需要通过记忆来掌握。这些动词可能在词干的元音、词尾的变化等方面不遵循规则动词的变位方式。
例如,不规则动词"быть"(是),其变位如下:
| 人称/时态 | 现在时 | 过去时 | 未来时 | |-----------|---------|---------|---------| | 第一人称单数 | я есть | я был | я буду | | 第二人称单数 | ты есть | ты был | ты будешь | | 第三人称单数 | он/она есть | он/она был | он/она будет | | 第一人称复数 | мы есть | мы были | мы будем | | 第二人称复数 | вы есть | вы были | вы будете | | 第三人称复数 | они есть | они были | они будут |
不规则动词的变位需要格外注意,特别是在开发自然语言处理工具时,对这些动词的正确处理尤为关键。
3. Lingua::RU::Inflect核心功能
3.1 模块的基本语法和结构
3.1.1 模块安装与配置
Lingua::RU::Inflect是一个用于处理俄语文本变形的Perl模块。它可以帮助开发者轻松地实现俄语单词的变格和变位功能。在开始使用之前,需要先进行模块的安装与配置。
首先,可以通过CPAN工具安装Lingua::RU::Inflect模块,操作步骤如下:
perl -MCPAN -e shell
install Lingua::RU::Inflect
如果在安装过程中出现任何问题,例如权限不足或者网络问题导致的下载失败,可以参考官方文档中提供的解决方案。
安装完成后,为了验证模块是否正确安装,可以在Perl脚本中加入以下测试代码:
use Lingua::RU::Inflect;
print "Module installed successfully!\n";
如果脚本运行成功并且输出"Module installed successfully!",则说明模块安装无误,可以进入下一步的学习。
3.1.2 核心函数和方法概述
Lingua::RU::Inflect模块提供了丰富的函数和方法来处理俄语的变形。以下是一些核心函数和方法的概述:
-
gender($word, $gender):用于判断和设置名词的性别。 -
number($word, $number):用于判断和设置名词的数。 -
case($word, $case):用于判断和设置名词的格。 -
conjugate($verb, $person, $number, $tense, $aspect):用于动词的变位。 -
adjective_compare($adj):用于形容词的比较级变形。 -
adverb_from_adjective($adj):用于由形容词生成对应的副词。
这些函数和方法是实现俄语变形处理的基础,它们可以根据需要组合使用来处理更复杂的文本变形场景。
3.2 名词变格功能详解
3.2.1 实现名词变格的函数使用
Lingua::RU::Inflect模块提供了针对名词变格的功能。名词变格分为性、数、格的变化。下面通过具体的代码示例来说明如何实现名词变格的功能。
use Lingua::RU::Inflect qw(case gender number);
my $word = "стол"; # 选择一个名词
my $gender = gender($word); # 判断名词的性别
my $number = 3; # 假设我们要设置名词为复数形式
# 名词在不同格的变化示例
for my $case (qw(Nominative Genitive Dative Accusative Instrumental Prepositional)) {
my $deformed = case($word, $case, $number);
print "$case: $deformed\n";
}
上述代码展示了如何将一个名词变格,包括不同性、数、格的情况。通过 gender 函数来确定名词的性别,并用 case 函数来对名词进行变格。
3.2.2 名词变格的案例应用
在实际应用中,可能需要将某个名词在特定的句子结构中进行变格。下面是一个实际应用的例子,如何在句子中应用名词变格。
use Lingua::RU::Inflect qw(case);
my $subject = "студент";
my $verb = "учиться";
my $object = "математике";
# 构造句子
my $sentence = "$subject $verb в $object";
# 变格名词
my $deformed_subject = case($subject, "Nominative", 1);
my $deformed_object = case($object, "Prepositional", 1);
# 更新句子
$sentence =~ s/$subject/$deformed_subject/;
$sentence =~ s/$object/$deformed_object/;
print $sentence; # 输出: "студент учится в математике"
在这个例子中,我们通过 case 函数对句子中的主语和宾语名词进行了变格,以适应特定的语句结构。通过这种方式,开发者可以轻松地处理和构造符合俄语语法的句子。
3.3 动词变位功能详解
3.3.1 实现动词变位的函数使用
动词变位是俄语语法中一个复杂的部分,Lingua::RU::Inflect模块提供了 conjugate 函数来简化动词变位的过程。这个函数需要指定动词、人称、数、时态和语态等参数。
use Lingua::RU::Inflect qw(conjugate);
my $verb = "учиться"; # 需要变位的动词
my $person = 3; # 第三人称
my $number = 1; # 单数形式
my $tense = "Present"; # 现在时
my $aspect = "Imperfect"; # 不完全体
my $conjugated = conjugate($verb, $person, $number, $tense, $aspect);
print "$verb $conjugated\n"; # 输出: учится
上述代码展示了如何将动词“учиться”在现在时、第三人称单数的情况下进行变位。
3.3.2 动词变位的案例应用
在更复杂的句子结构中,动词变位的应用会更加多样。下面的例子演示了如何在句子中应用动词变位。
use Lingua::RU::Inflect qw(conjugate);
my $sentence = "Он будет $verb завтра";
my $verb = "учиться";
my $conjugated = conjugate($verb, 3, 1, "Future", "Imperfect");
$sentence =~ s/$verb/$conjugated/;
print $sentence; # 输出: "Он будет учиться завтра"
在这个例子中,我们通过 conjugate 函数对句子中的动词“учиться”进行了未来时的变位,使得句子在语法上正确且符合俄语表达习惯。
在本章节中,我们了解了Lingua::RU::Inflect模块如何处理名词变格和动词变位的基本语法和结构,以及实际案例中的应用。接下来的章节中,我们将继续深入了解模块中处理动词时态和语态的方法,以及模块使用方法与二次开发的相关知识。
4. 动词时态和语态处理
4.1 时态处理机制
4.1.1 常见时态的变位规则
俄语的时态系统包括未完成体和完成体两个方面,其中未完成体有过去时、现在时、将来时三种基本时态,完成体有过去时、现在时、将来时以及条件式四种基本时态。每种时态都有其特定的变位规则,这些规则大多受到动词的体、人称和数的影响。
过去时是未完成体和完成体动词变化的一种形式,表示过去某个确定时间发生的动作或状态,它的变位通常依据动词的词根和后缀来确定。现在时则表达现在或将来经常发生的动作或状态,变位则与人称和数有关。将来时通过在动词的将来时形式前加未来时助动词“быть”(将有)来构成。
完成体的现在时和过去时是通过在未完成体动词的基础上添加后缀和变化来表达动作的完成,通常情况下,完成体时态会用于表示动作已经完成或结果对现在造成影响。
4.1.2 时态处理函数的应用
在编程中,处理俄语动词时态通常需要借助专门的模块,如Lingua::RU::Inflect,该模块提供了丰富的函数用于动词时态的生成。以下示例展示了如何使用这些函数来处理俄语中的未完成体动词时态变化:
use Lingua::RU::Inflect qw(conjugate_verb imperfective_verb);
my $verb = "читать"; # "читать" 表示“读”的未完成体动词原形
my @persons = qw(я ты он она оно мы вы они); # 俄语人称代词
my @tenses = qw(present past future); # 常见时态
# 生成现在时态的变位形式
foreach my $person (@persons) {
print conjugate_verb($verb, $person, "present") . "\n";
}
# 生成过去时态的变位形式
foreach my $person (@persons) {
print conjugate_verb($verb, $person, "past") . "\n";
}
# 生成将来时态的变位形式
foreach my $person (@persons) {
print conjugate_verb($verb, $person, "future") . "\n";
}
函数 conjugate_verb 可以根据传入的动词原形、人称代词和时态生成对应的变位形式。这种编程方式可以大大简化处理俄语动词时态的复杂性。
4.2 语态转换方法
4.2.1 主动语态与被动语态的转换逻辑
俄语中的被动语态通常由助动词“быть”(是)加上动词的被动形变位构成。被动语态的转换通常涉及将主动语态中的动作执行者从句子的主语位置转移到由介词“кем”(被谁)或“чем”(被什么)引导的状语位置上。转换为被动语态时,需要特别注意动词变位和语义的对应关系,以及动作的承受者是否明确。
例如,主动句“Учитель проверяет домашнее задание”(老师检查家庭作业)中的动作执行者是“учитель”(老师),当转换为被动语态时,句子变为“Домашнее задание проверяется учителем”(家庭作业被老师检查)。
4.2.2 语态转换的函数实现
要在程序中处理俄语文本时进行语态转换,可以通过编写函数来实现这一过程。这里假设已经有了能够处理语态转换的模块或者函数,我们可以演示如何使用它进行语态转换:
use Lingua::RU::Inflect qw(passivize);
my $active_verb = "проверяет"; # 主动语态的动词形式
my $passive_form = passivize($active_verb); # 被动语态的动词形式
print "Активная форма: $active_verb\n";
print "Пассивная форма: $passive_form\n";
假设模块中有一个 passivize 函数用于将主动形式的动词转换为被动形式。当然,在实际使用中,可能需要对转换逻辑进行更复杂的处理,例如考虑到句子结构、上下文以及动词变位规则的准确性。
4.3 时态和语态在文本中的应用
4.3.1 文本时态分析的策略
在自然语言处理中,分析文本中的时态和语态是一项复杂的任务。策略上,首先需要对文本进行分词和词性标注,然后使用特定算法识别时态和语态标记。对于时态,可以依据动词的变位后缀和上下文线索进行判断;对于语态,分析句子结构,尤其是动词的被动形式标记(如被动语态的标志词“кем”、“чем”以及动词的特殊变形)。
一个文本时态分析的实例可以是这样的:给定一句话“Он уже прочитал книгу”,分析句子中的动词“прочитал”,识别它的时态为过去时,语态为主动语态。
4.3.2 实际文本中的时态和语态应用案例
在实际应用中,俄语文本处理会涉及到大量的文本数据,例如新闻报道、社交媒体内容等。处理这些数据时,时态和语态的分析可以帮助机器更好地理解文本内容和上下文含义,从而提供更为精确的语言处理服务。
以下是使用Lingua::RU::Inflect模块进行实际文本时态和语态分析的一个案例:
use Lingua::RU::Inflect qw(analyze_verb);
my $text = "Когда ученик вернётся домой, он уже прочитал книгу";
my @verbs = split(' ', $text); # 假设已经分词
foreach my $verb (@verbs) {
my ($tense, $mood, $aspect) = analyze_verb($verb);
print "Глагол: $verb, Время: $tense, Наклонение: $mood, Вид: $aspect\n";
}
在这个例子中,我们使用 analyze_verb 函数分析文本中的每个动词,并输出其时态(时)、语气(语气)和体(体)。注意,实际使用中还需要一个有效的分词器来准确分割文本中的单词。这个例子仅用于说明如何使用模块进行处理,实际应用中可能需要结合复杂的算法和数据集来提高准确性。
通过这些案例,可以看出,在处理俄语的时态和语态时,利用编程模块可以有效简化开发过程,并提高程序对语言规则的处理能力。
5. 模块使用方法与二次开发
5.1 常规使用场景
5.1.1 模块在脚本中的基本使用
在编写涉及俄语文本处理的脚本时,Lingua::RU::Inflect模块可以显著简化代码。使用该模块,开发者无需手动处理复杂的变格和变位规则。以下是一个基本的使用示例,展示如何在Perl脚本中使用该模块进行名词和动词的变格和变位。
use Lingua::RU::Inflect qw(:Nouns :Verbs);
my $nominative = inflect_noun('стол', 'м', 'ед'); # 单数主格
my $genitive = inflect_noun($nominative, 'м', 'ед', 'род'); # 单数生格
print " стол -> $nominative\n";
print " стола -> $genitive\n";
my $past masculine singular = conjugate("читать", 'прош', 'м', 'ед');
my $present masculine singular = conjugate("читать", 'наст', 'м', 'ед');
print " читал -> $past\n";
print " читает -> $present\n";
5.1.2 常见问题及解决方法
在使用Lingua::RU::Inflect模块时,可能会遇到一些问题。例如,某些词干没有预设的变格信息,模块可能返回错误或不准确的结果。解决这类问题的方法通常包括更新模块到最新版本,以及使用模块提供的函数来扩展其内置词典。
# 添加缺失的名词变格规则
add_noun_rule('новость', 'ж', 'ед', 'вин', 'новость');
5.2 源代码分析与定制化修改
5.2.1 模块内部结构的解析
Lingua::RU::Inflect模块由多个文件组成,其主要逻辑位于 Lingua/RU/Inflect.pm 文件中。这个文件使用Perl的面向对象方法实现了俄语的变格和变位规则。模块的主要功能由几个核心函数和类方法实现,如 inflect_noun 、 conjugate 、 add_noun_rule 等。开发者可以通过阅读 lib/Lingua/RU/Inflect.pm 来理解这些方法的工作原理。
5.2.2 根据需求定制化修改实例
定制化修改实例通常需要对Perl和Lingua::RU::Inflect模块有较深的理解。下面的例子展示了如何为模块添加新的动词变位规则,以便处理不规则动词。
# 添加新的动词变位规则
add_verb_rule('бежать', 'бежал', 'бежала', 'бежало', 'бежали');
5.3 模块在自然语言处理中的应用
5.3.1 结合NLP工具的案例分析
在自然语言处理(NLP)应用中,Lingua::RU::Inflect模块可以用于文本分析和预处理阶段。例如,在情感分析、机器翻译或文本摘要中,需要对文本进行词性和变格分析。下面的案例分析展示了如何结合Lingua::RU::Inflect模块和NLP工具处理俄语文本。
use Lingua::RU::Inflect qw(inflect_noun conjugate);
use Text::Tokenize::Russian qw(tokenize俄语文本);
my $text = 'Я читаю книгу.';
my @tokens = tokenize俄语文本($text);
# 对每个单词进行词性标注和变格分析
foreach my $token (@tokens) {
my $word = $token->{word};
my $part_of_speech = $token->{pos};
if ($part_of_speech eq 'VERB') {
my $past masculine singular = conjugate($word, 'прош', 'м', 'ед');
print "动词过去式单数男性:$past\n";
} elsif ($part_of_speech eq 'NOUN') {
my $genitive = inflect_noun($word, 'м', 'ед', 'род');
print "名词生格:$genitive\n";
}
}
5.3.2 在Web应用中的集成方案
将Lingua::RU::Inflect模块集成到Web应用中,可以为用户提供动态的语言支持和内容本地化功能。下面的示例展示了如何在Web应用中集成该模块来处理用户输入的俄语文本。
# Perl的CGI应用示例,处理表单中的俄语文本
use Lingua::RU::Inflect qw(inflect_noun conjugate);
use CGI;
my $cgi = CGI->new;
my $text = $cgi->param('text');
# 解析文本并执行俄语变格和变位
my @words = split(/\s+/, $text);
for my $word (@words) {
# 假设所有单词都是名词或动词,并进行处理
# 这里仅为示例,实际应用中需要进行词性标注
my $genitive = inflect_noun($word, 'м', 'ед', 'род');
print $word . " -> $genitive\n";
my $past masculine singular = conjugate($word, 'прош', 'м', 'ед');
print $word . " -> 过去式单数男性:$past\n";
}
通过上述示例,我们可以看到,Lingua::RU::Inflect模块不仅可以用于简单的文本处理,而且在复杂的自然语言处理场景和Web应用集成中都有广泛的应用前景。
简介:Lingua::RU::Inflect是Perl模块中的俄语变位工具,特别适用于处理复杂语法的俄语文本。该模块能高效、灵活地处理俄语名词、形容词和代词的变形,支持不同的语法格和数的变化,并能够自动识别并应用这些规则。它简化了俄语文本处理,适用于构建自然语言处理系统和Web应用。模块还支持动词时态和语态变化,并提供扩展功能。源代码开放,便于开发者研究和自定义。Lingua::RU::Inflect是Perl开发者在处理俄语任务中的得力助手,提高了代码的可读性和效率。

















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









