









简单的人工智能,我尝试用最通俗易懂的语言将复杂的技术讲给大家听。
深度学习中的损失函数:AI的“评分标准”
1. 什么是损失函数?
在深度学习中,损失函数(Loss Function)是一个“打分器”,用来衡量模型的表现好不好。它计算出模型的预测值和真实值之间的差距,差距越小,模型越“聪明”;差距越大,模型就还需要努力学习。
2. 损失函数的作用
损失函数的核心作用是为模型的优化提供方向和目标:
- 衡量预测的准确性:告诉模型当前的预测和实际情况有多大差距。
- 指导参数调整:梯度下降算法会根据损失函数的值,调整模型参数,逐步减小误差。
3. 损失函数的分类与常见类型
- 根据不同的任务,损失函数主要分为以下几类:
回归任务中的损失函数
适用于连续值预测(比如房价预测、温度预测等)。
1. 均方误差(Mean Squared Error, MSE)
- 公式:
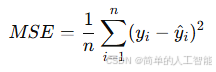
其中,是真实值,
是预测值,n 是样本数量。
- 含义:MSE计算的是预测值和真实值的平方差的平均值,差距越大,损失越大。
- 优缺点:
优点:对大误差敏感(平方让大的错误更突出)。
缺点:对异常值(outliers)过于敏感,可能导致模型不稳定。
- 举个栗子:如果你预测了明天的气温是25°C,但实际是20°C,那么误差是5°C,MSE会将误差平方(5² = 25)后累计,提醒模型需要关注。
2. 平均绝对误差(Mean Absolute Error, MAE)
-
公式:
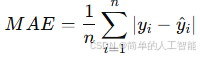
-
含义:直接计算预测值和真实值的绝对差距的平均值。
-
优缺点:
- 优点:对异常值不敏感,比MSE更鲁棒。
- 缺点:优化时可能会有不连续点,不如MSE平滑。
-
举个栗子:仍然是气温预测,MAE只关心差了多少°C,不像MSE那样对大误差惩罚特别严重。
分类任务中的损失函数
适用于离散类别的预测(比如图像分类、情感分析等)。
1. 交叉熵损失(Cross-Entropy Loss)
- 公式:
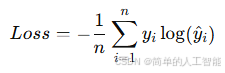
其中,是真实标签(1或0),
是模型预测为类别1的概率。
-
含义:用于衡量分类模型的输出概率分布和真实分布之间的差异。真实标签为1时,
越接近1,损失越小;反之损失越大。
-
优缺点:
- 优点:非常适合概率模型和多类别分类任务。
- 缺点:对模型输出的概率敏感,错误预测会导致较大的损失。
-
举个栗子:假设你用模型预测一张图片是猫的概率是90%,而真实情况也是猫(标签=1),损失会很小。但如果你预测它是狗的概率高达80%,损失就会非常大。
2. Hinge Loss(铰链损失)
- 适用于支持向量机(SVM)和二分类任务,用于鼓励更大的分类间隔。
- 公式:
![]()
- 其中,
是真实标签(+1或-1),
- 含义:如果预测的类别与真实类别一致且置信度高,损失为0;否则损失随着差距增加。
特殊任务中的损失函数
适用于特定任务,比如生成模型或强化学习。
1. 对抗损失(Adversarial Loss)
- 常用于生成对抗网络(GAN)。生成器试图最小化其生成样本被判别器识别为假的概率,而判别器试图最大化区分真假样本的概率。
- 举个栗子:生成器和判别器像两个对手在下棋,一个拼命让假数据看起来更像真数据,一个拼命找出假数据,损失函数就是这场博弈的胜负标准。
2. 自定义损失函数
- 在某些特殊场景下,标准损失函数无法满足需求,可以设计自定义损失函数。例如,在自动驾驶中,可以为碰撞风险的预测设置较高的惩罚。
4. 损失函数的选择与注意事项
1)根据任务选择损失函数
- 如果是回归任务,优先选择MSE或MAE。
- 如果是分类任务,交叉熵损失是默认选择。
- 对于复杂或多任务模型,可以结合多种损失函数使用。
2)权衡异常值影响
- 如果数据中异常值较多,MSE可能会放大误差,MAE会更鲁棒。
3)理解与调整
- 损失函数不是一成不变的工具。根据实际情况微调或自定义损失函数,能够显著提升模型的表现。

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









