



 本文介绍了SQL的汇总分析,包括COUNT、SUM、AVG、MAX、MIN等函数的使用,以及如何进行数据分组、对分组结果指定条件(HAVING子句)。详细讲解了如何用SQL解决业务问题,如计算各科平均成绩、分组查询成绩范围、性别统计等。此外,还讨论了对查询结果排序的方法(ORDER BY)及常见的SQL错误。提供了多个练习题帮助读者巩固学习。
本文介绍了SQL的汇总分析,包括COUNT、SUM、AVG、MAX、MIN等函数的使用,以及如何进行数据分组、对分组结果指定条件(HAVING子句)。详细讲解了如何用SQL解决业务问题,如计算各科平均成绩、分组查询成绩范围、性别统计等。此外,还讨论了对查询结果排序的方法(ORDER BY)及常见的SQL错误。提供了多个练习题帮助读者巩固学习。
大纲
1.汇总分析
2.分组
3.对分组结果指定条件
4.用sql解决业务问题
5.对查询结果排序
6.如何看懂报表信息
一,汇总分析
- 汇总函数
汇总函数 作用
count 求某列的行数
sum 对某列数据求和
avg 求某列数据的平均值
max 求某列数据的最大值
min 求某列数据的最小值
- 函数的三个功能
功能 输入 输出
count函数
1.count(选择列名)
会自动排除null

count(全部列)不会排除null

2.求和(sum)

3.求某列数据平均值

4.求某列数据的最大值,最小值

如果计算之前,不想计算重复值,就可以把重复值删除

二,分组
sql分组:group by
分组方法:
1.数据分组
2.应用函数
3.组合结果
2.select 性别,count(*)
3.from student
1.group by 性别;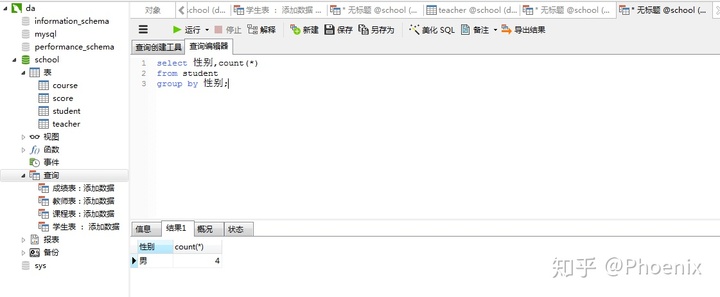
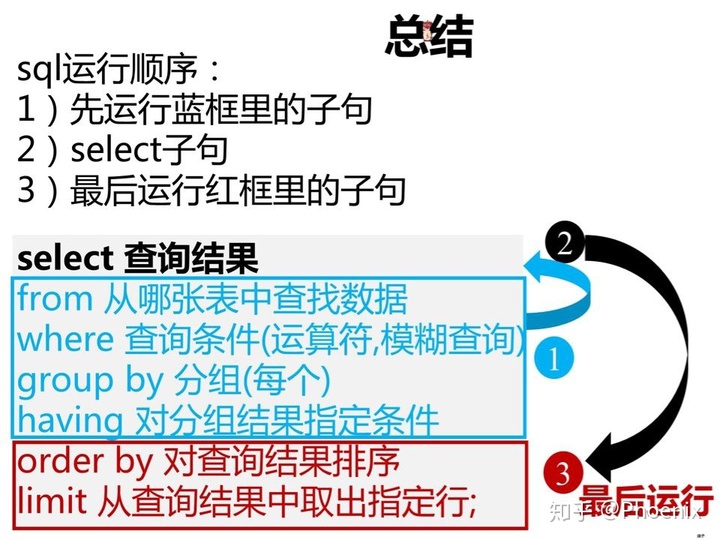
运行顺序:
1.从哪张表查找数据
2.查询条件
3.对第二步查询出的数据进行分组
4对分组应用函数,并组合结果
三,对分组结果指定条件(having)
select 性别,count(*)
from student
group by 性别
-- 对分组结果指定条件
having count(*)>1;四,如何用sql解决业务问题
步骤:
1.翻译成大白话
2.写出分析思路
3.写出对应的sql子句
1.翻译大白话
问题:
如何计算各科的平均成绩
=如何计算每门课程的平均成绩
2.写出分析思路
select 查询结果[每门课的课程号:分组,平均成绩:avg(成绩)]
from 从哪张表中查找数据[成绩表:score]
where 查询条件[没有]
group by 分组[每门课程:按课程号分组]
having 对分组结果指定条件;[没有]五,对查询结果排序
对查询结果排序 order by
降序(desc):从大到小
升序(asc):从小到大
limit 从查询结果中取出指定行
六,如何看懂报错信息?
常见错误:
1.在group by 里使用了select的别名
因为group by在select之前运行,所以如果设置别名,group by是识别不出的。

2.在where中使用聚合函数

3.字符串和数字的排序是不一样的,在排序之前需要把表格中的数字转换为数值格式
练习:
一,汇总分析
1.查询课程编号为“0002”的总成绩
select sum(成绩)
from score
-- 设定指定查询条件
where 课程号="0002";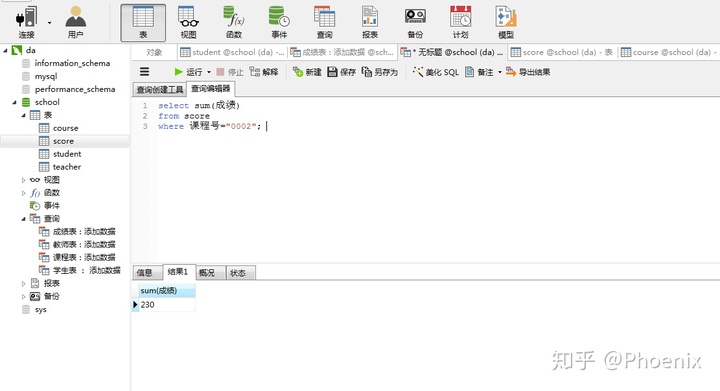
2.查询选了课程的学生人数
select count(学号)
from score;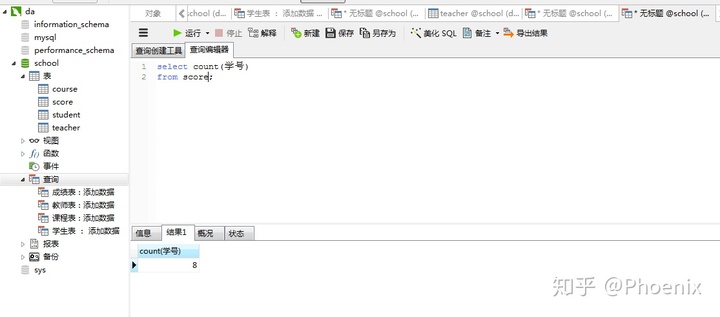
二,分组
1.查询各科成绩最高和最低的分
select 课程号,max(成绩),min(成绩)
from score
group by 课程号;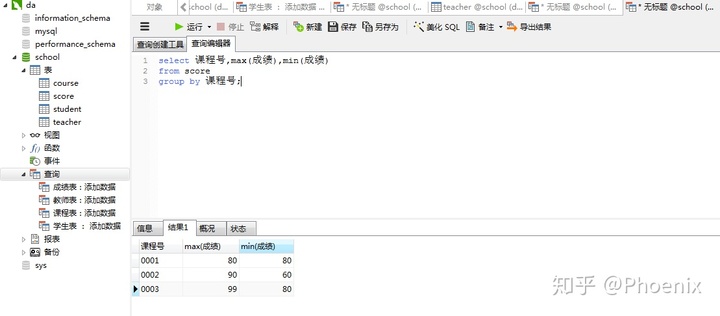
2.查询每门课被选修的学生人数
select 课程号,count(学号)
from score
group by 课程号;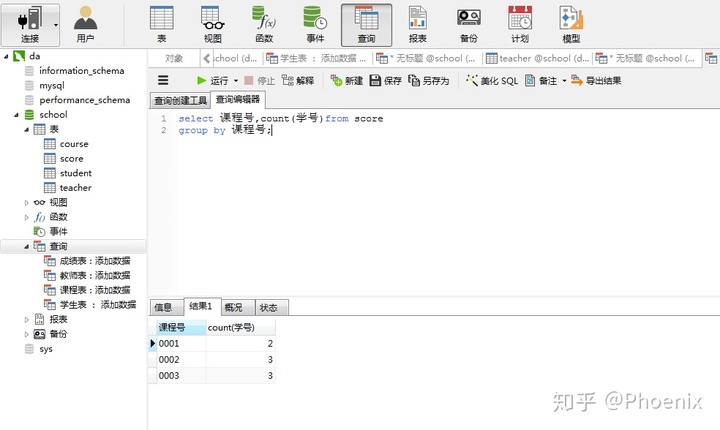
3.查询男生,女生人数
select 性别,count(姓名)
from student
group by 性别;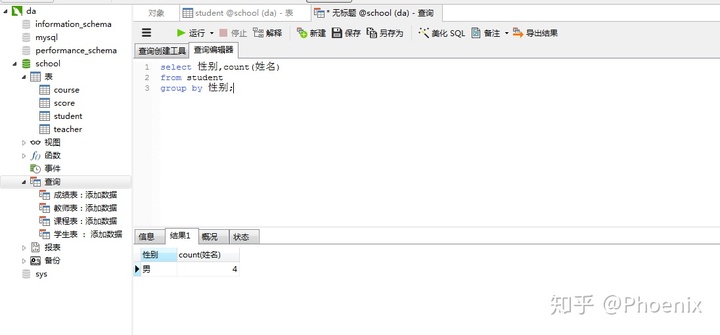
三,对分组结果指定条件(having)
1.查询平均成绩大于60分学生的学号和平均成绩
select 学号,avg(成绩)
from score
group by 学号
having avg(成绩)>60;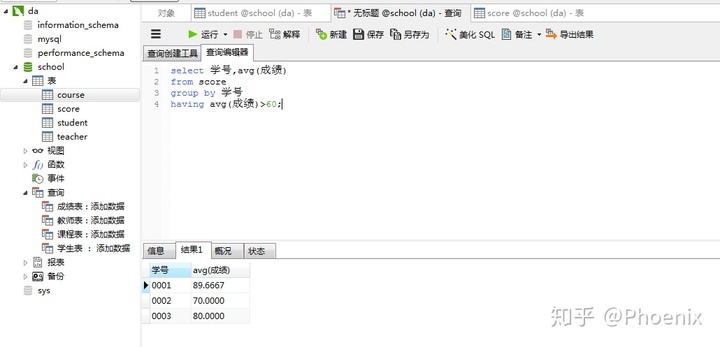
2.查询至少选择两门课程的学生学号
step1:计算每个学生选修课程数
step2:统计选择至少两门课程的学生数
select count(课程号),学号
from score
group by 学号
having count(课程号)>=2;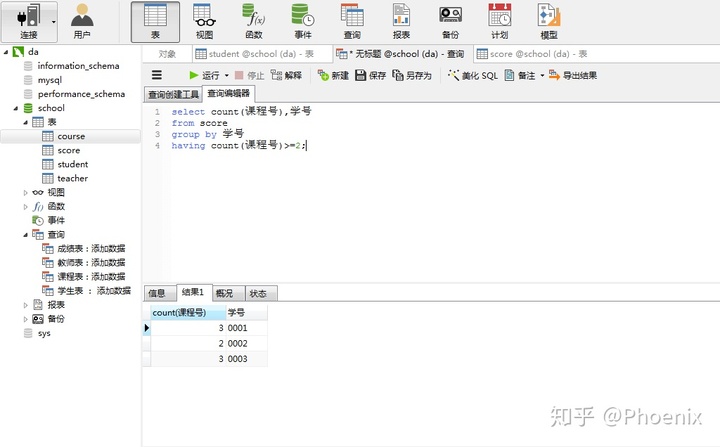
3.查询同姓名学生名单并统计同名人数
step1:知道每一个学生姓名(对姓名分组)
step2:统计同名的人数
select 姓名,count(*) as 人数
from student
group by 姓名
having count(*)>=2;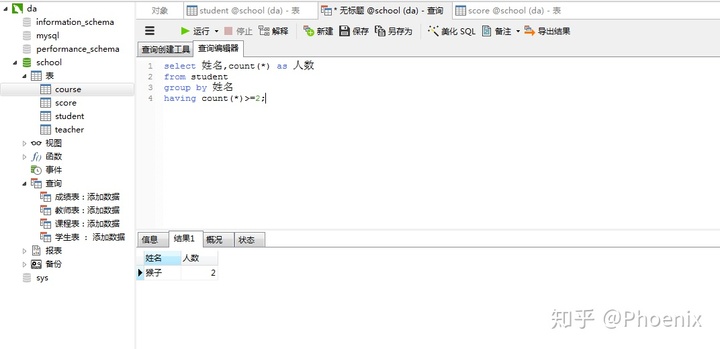
四,用sql解决业务问题
练习:如何计算每门课程的平均成绩,并且平均成绩大于等于80分
分析思路:
select 查询结果[每门课的课程号:分组,平均成绩:avg(成绩)]
from 从哪张表中查找数据[成绩表:score]
where 查询条件[没有]
group by 分组[每门课程:按课程号分组]
having 对分组结果指定条件;[没有]
sql语句:
select 课程号,avg(成绩)
from score
group by 课程号
having avg(成绩)>=80;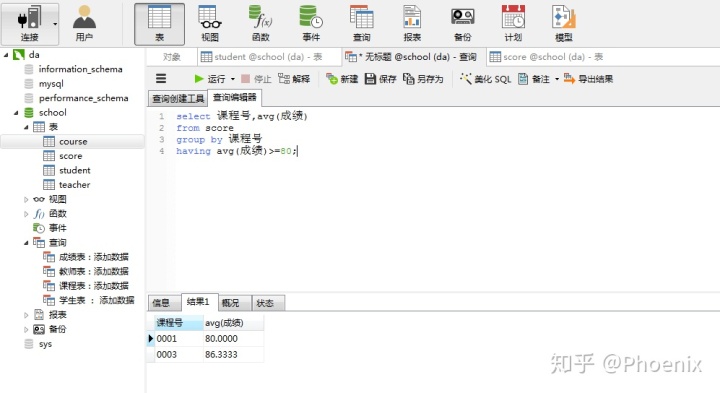
五,对查询结果进行排序
1.查询不及格的课程并按课程号从大到小排列
select count(课程号),成绩
from score
where 成绩<=60
order by 课程号 desc;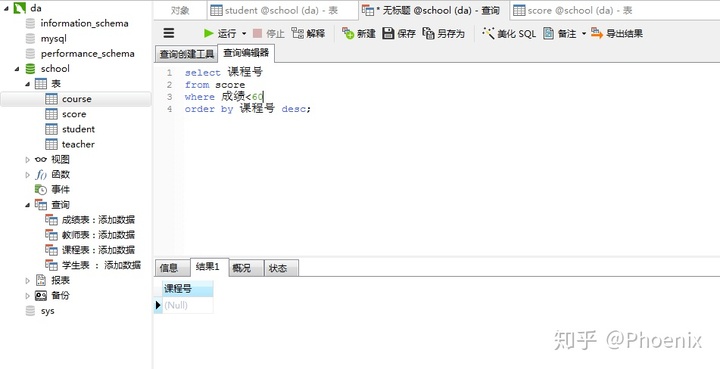
2.查询每门课程的平均成绩,结果按照平均成绩升序排序。平均成绩相同时,按课程号降序排序
select 课程号,avg(成绩) as 平均成绩
from score
group by 课程号
order by 平均成绩 asc,课程号 desc;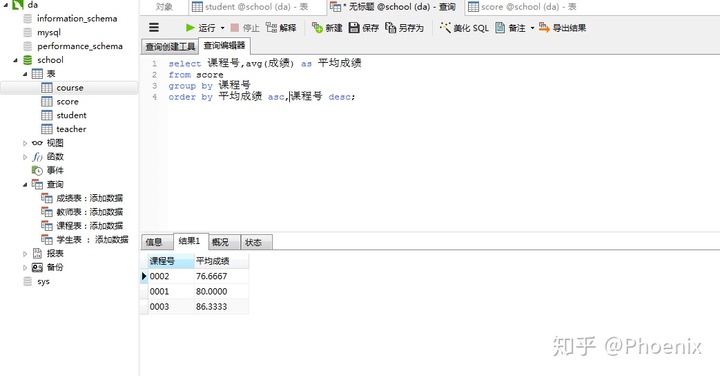
SQLZOO习题
错题
select from nobel prize14.查找1984年获奖者和主题按主题和获胜者名称排序,并把物理奖和化学奖排到最后面显示
select winner,subject
from nobel
where yr=1984
order by subject in ("Physics","Chemistry"),subject,winner;subject in ("Physics","Chemistry")对subject做一个if的判断,有的是1,没有的是0,
而1在0后面,所以物理和化学奖排到最后面显示
sum and count
7.显示每个大陆的国家数量,并且这些国家里人口数量至少为1000万
分析思路:
#首先确定人口数量至少为1000万的国家,然后每个大陆就意味着按照大陆分组
所以先限定条件,再按大陆分组
select continent,count(name)
from world
where population >=10000000
group by continent8.列出每个洲名称,并且每个洲人口要大于等于1个亿
分析思路:
#按照州先分组,然后限定每个洲的人口要大于等于1个亿
select continent,count(name)
from world
group by continent
having sum(population)>=100000000;

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









