







GAN自从被提出之后就受到了广泛的关注,GAN也被逐渐用于各种有趣的应用之中。虽然GAN的idea对研究者们有着巨大的吸引力,但是GAN的训练却不像普通DNN那样简单,generator和discriminator之间的平衡,训练过程中没有很好的指标度量训练效果成为了训练GAN的难点。WGAN的提出几乎完美解决了这两个问题。
参考文章:
原始GAN存在的问题
要想知道原始GAN存在什么问题,我们先看一下GAN的优化目标。
作者在原始论文中提到,在真正优化G的时候 $log(1-D(G(z))$ 可能无法给G提供足够的梯度,于是可以通过maxmize $log(D(G(z))$ 的方式来更新G。而在WGAN的前序论文中,证明了这两种优化G的方式都是有一定问题的。
优化准则$log(1-D(G(z))$ 带来的梯度消失
在论文中,作者也给出了相关的证明,通过一步步优化公式$ref{gan_target}$,最终的目标就是使得$p_{data}(x) = p_g(x)$ .优化D
由$cfrac{partial Loss}{partial D(x)} = 0$ 可以得到:
优化G
将公式$ref{d_res}$ 中的结果,带入公式$ref{gan_target}$ ,可以得到得到最优的D之后,优化G的目标
在此,介绍连个分布距离度量的指标:KL divergence: $KL(P_1||P_2) = mathbb{E}_{x sim P_1} logcfrac{P_1}{P_2} label{kl_div}tag{4}$
JS divergence: $JS(P_1||P_2)= cfrac{1}{2}KL(P_1||cfrac{P_1+P_2}{2})+cfrac{1}{2}KL(P_2||cfrac{P_1+P_2}{2}) label{js_div}tag{5}$
G的优化目标$ref{g_loss}$可以通过形式的变换转为JS的的形式:
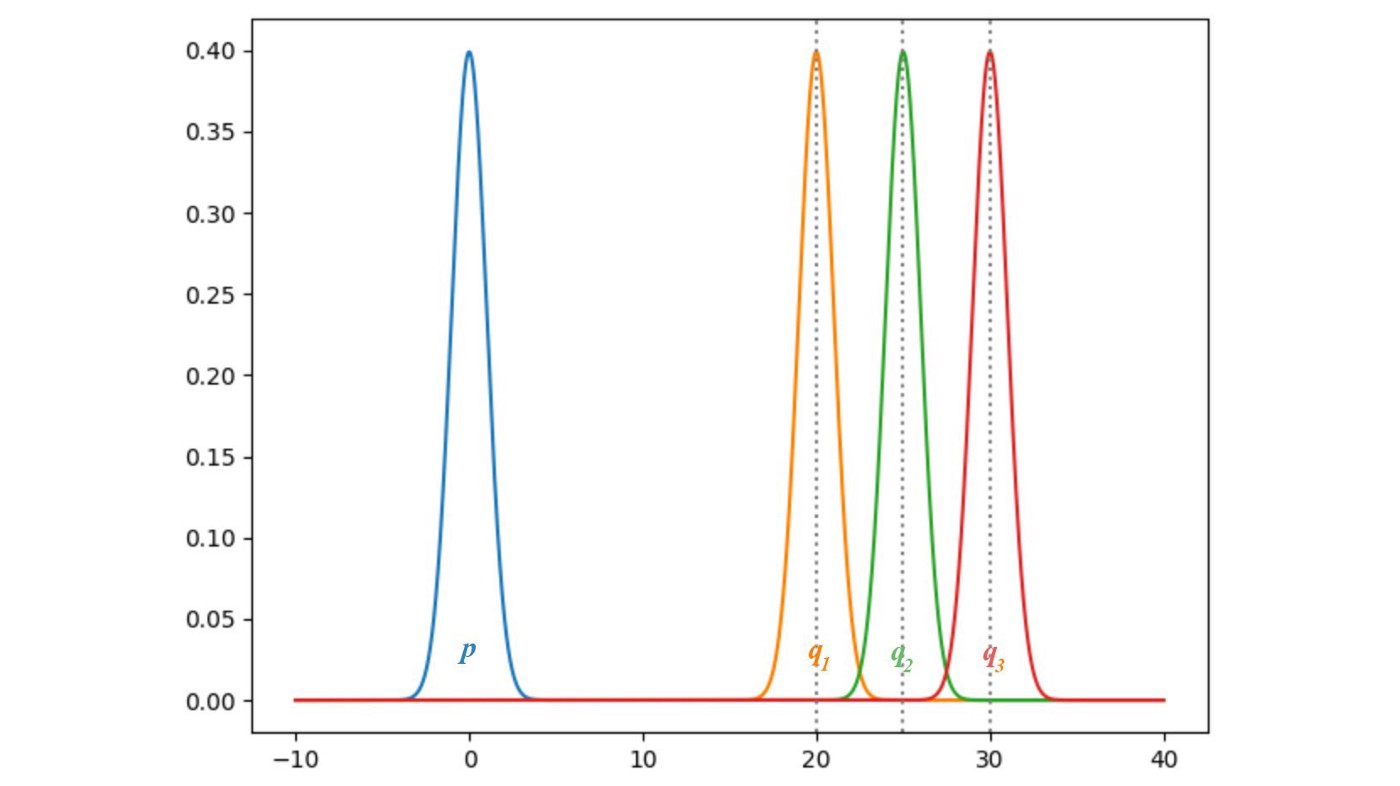
虽然我们将G的loss转为了某种距离,即JS,但是这种距离是有点问题的。看下面两张图,假设p就是真实分布,q是我们生成的分布。可以清晰的看出,KL和JS散度在q的均值为零的时候都为0。但是随着q远离p,KL和JS逐渐趋于定值,而且JS趋于定值的速度更快。既然趋于定值了,那么相应的梯度就是0了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









