






论文
Improved Training of Wasserstein GANsxxx.itp.ac.cn我们之前说了,WGAN的(启发式的)保证函数
这一看就是很扯淡的方法,这篇文章则是对这个的改进。
先说说有什么问题。在GAN-GP这篇论文中,作者给出了WGAN的两个主要缺点,同时用了一个toy example说明这些问题。
作者发现不仅是原文中的直接对
总之一句话,直接对
Capacity underuse
这是容易理解的,毕竟你把
作者们的toy example的大致思想是,把
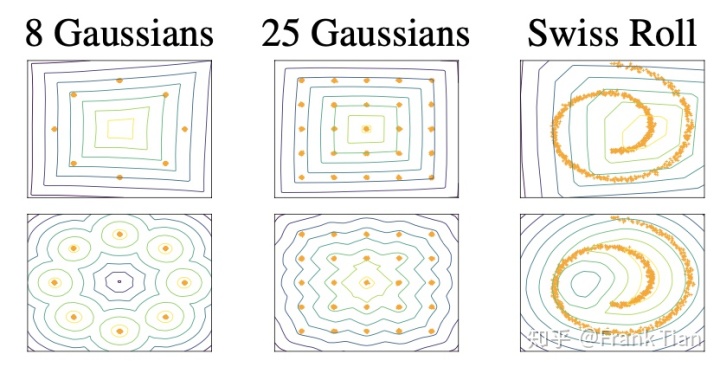
上图中的第一排是WGAN中critic(其实就是discriminator,他们换了个名字)的值的图像,下图的则是WGAN-GP的,很容易看出WGAN的模型复杂度确实有影响,WGAN-PG要看起来好得多。
Exploding and vanishing gradients
这同样是直接对
注意,随着层数越靠近输入层,norm的波动应该越大,毕竟梯度是反着来的。
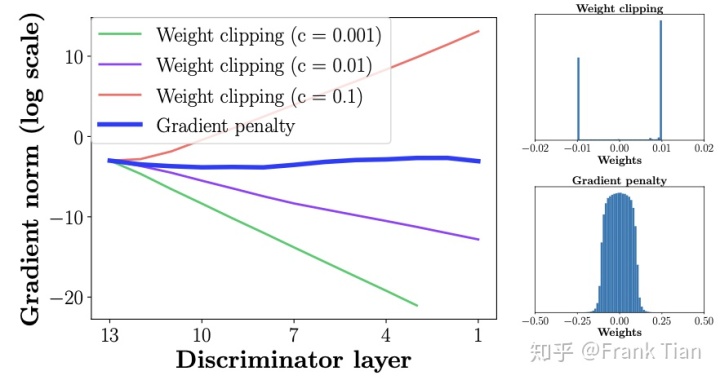
上图说明了WGAN的梯度不是爆炸就是消失。
当然在GAN中一般都使用了batch normalization的技术,梯度的波动不会这么剧烈,但是WGAN的性能可能会受到影响。
当然,原始的WGAN还有一个缺点,就是实际上根本不能保证clip的函数
作者的意思是,既然我们想让
于是他们提出了Gradient penalty,这就是算法名字中GP的由来。
于是,现在的损失函数形如
显然那个Our gradient penalty比较有说道,下面的是对这个公式的具体说明。
Sampling distribution
我们当然希望
因此我们从
Penalty coefficient
这是个超参数,经验上取
No critic batch normalization
这个也显然,用了batch normalization还咋Gradient penalty嘛。
Two-sided penalty
这个比较重要,既然我们希望梯度处处小于1,为什么不做单边约束,也就是
这是因为实际上,EM距离表示为
而函数
但是往往是取等号的,毕竟要求极值
因此这里就启发式的写成Two-sided penalty而不是One-sided penalty了。
当然这只是经验上的改进。
算法长这样

和WGAN的一个小区别是WGAN-GP用了adam做优化,而WGAN用的是RMSprop,不过这是细节啦。














 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









