






我将向您展示如何使用FastAIv1和Pytorch构建神经网络(多层感知器)并成功训练它以识别图像中的数字。Pytorch是一个非常流行的深度学习框架,FastAI v1是一个使用现代最佳实践简化训练快速准确的神经网络的库。它基于对fast.ai进行快速学习最佳实践的研究,包括对视觉,文本,表格和协作(协作过滤)模型的支持。我会在本文最后贴出源代码地址。
BoilerPlate命令
使用以下三行代码可以确保对您所创建的库的任何编辑都自动重新加载,并且显示的任何图表或图像都会显示在此内容中。
%reload_ext autoreload%autoreload 2%matplotlib inline导入Fast AI库
让我们导入fastai库并将我们的batch_size参数定义为128。图像数据库是巨大的,所以我们需要使用批处理将这些图像输入GPU,批处理大小为128意味着我们将一次输入128幅图像来更新我们的深度学习模型的参数。如果由于GPU RAM较小而导致内存不足,则可以将批处理大小减小到64或32。
from fastai.vision import *bs=128使用数据集
我们将从MNIST手写数据集开始。MNIST是小型(28x28)手写灰度数字的标准数据集,于20世纪90年代开发,用于测试当今最复杂的模型; 现在,经常被用作介绍深度学习的基本“hello world”。此fast.ai数据集版本使用标准PNG格式而不是原始的特殊二进制格式,以便您可以在大多数库中使用常规数据路径; 如果您只想使用与原始输入通道相同的单个输入通道,只需从通道轴中选取一部分即可。
path = untar_data(URLs.MNIST);path
通过运行上述命令,数据被下载并存储在上面显示的路径中。让我们看看如何设置数据目录,因为我们必须从这些目录导入数据。让我们从查看路径目录开始,我们可以看到下面的数据已经有了训练和测试文件夹。
path.ls()
让我们看一下训练文件夹。数据在不同的文件夹中按数字1到9分离出来。
(path/'training').ls()
在每个数字文件夹中,我们还有图像。
(path/'training/0').ls()[1:5]
导入数据
现在我们了解了如何设置数据目录; 我们将使用FastAI 的data block API导入数据和FastAI image transform函数来进行数据扩充。
ds_tfms = get_transforms(do_flip=False, flip_vert=False, max_rotate= 15,max_zoom=1.1, max_lighting=0.2, max_warp=0.2)
在get_transforms函数中,我们可以定义我们想要做的所有转换。FastAI使得数据增强非常容易,因为所有转换都可以在一个函数中传递并使用非常快速的实现。函数中给出的每个参数:
- do_flip = False,flip_vert = False:不允许在垂直和水平方向上翻转数字。
- max_rotate = 15:设置在顺时针和逆时针方向上导入图像时最多随机旋转15度。
- max_zoom = 1.1:设置放大/缩小原始图像的尺寸不超过10%
- max_lighting = 0.2:设置将应用由max_lighting控制的随机闪光和对比度变化
- max_warp = 0.2:在-max_warp和+ max_warp之间的随机对称扭曲应用概率p_affine,在这种情况下默认为0.75。
现在我们已经定义了我们想要对输入图像做什么转换,让我们从定义数据批处理或databunch (FastAI将其称为databunch)开始。因为图像数据集的数据量很大,所以尽量不在内存中导入整个数据集,而是我们一个databunch,它允许我们加载批量数据并动态执行所需的转换。
data = (ImageItemList.from_folder(path, convert_mode='L') .split_by_folder(train='training', valid='testing') .label_from_folder() .transform(tfms=ds_tfms, size=28) .databunch(bs=bs))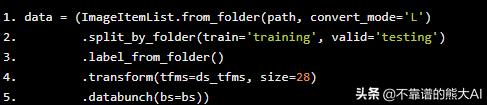
Jeremy Howard将上述步骤称为标签工程,因为大部分时间和精力花在正确导入数据上。FastAI的data block API使我们可以非常容易地定义我们想要如何使用R ggplots (如API)来导入我们的数据,可以一直链接不同的函数,直到数据集准备好为止。让我们理解上面的代码在做什么 -
- ImageItemList.from_folder(path,convert_mode ='L') - 在带有文件名后缀扩展名的文件夹中创建ItemList。Convert_mode ='L'帮助我们定义我们导入的图像是灰度/单通道图像默认为'RGB',这意味着一个3通道图像。FastAI使用PIL库,所以convert实际上是PIL函数
- split_by_folder(train ='training',valid ='testing'):这个函数告诉数据库我们在Path目录的'training'和'testing'子文件夹中有训练和测试数据
- label_from_folder() - 此函数通知databunch从其文件夹名称中获取数字标签
- transform(tfms = ds_tfms,size = 28) - 此函数通知databunch将ds_tfms变量中定义的转换应用于每个图像
- databunch(bs = bs) - 此函数将此数据库转换为FastAI的ImageDataBunch类,批量大小在bs变量中定义,本例中为128。
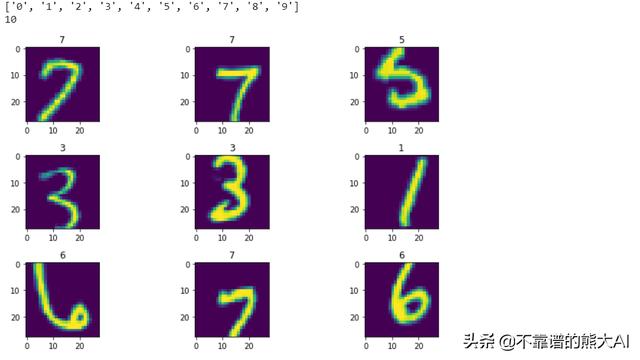
现在我们已经定义了我们的databunch,现在可以看看我们的数据。如下所示,您可以看到数字是使用show_batch函数导入和可视化,这些图像已应用了我们定义的转换。
print(data.classes) ## Prints class labelsprint(data.c) ## Prints number of classesdata.show_batch(rows=3, figsize=(10,6), hide_axis=False) ## Show sample data
使用Pytorch定义多层感知器
现在我们已经定义了我们的databunch。让我们使用Pytorch定义我们的Multilayer感知器模型。对于完全连接的层,我们使用nn.Linear函数,我们使用ReLU转换应用于非线性。在Pytorch中,我们只需要定义前向函数,并使用autograd自动定义后向函数。
class Mnist_NN(nn.Module): def __init__(self): super().__init__() self.lin1 = nn.Linear(784, 512, bias=True) self.lin2 = nn.Linear(512, 256, bias=True) self.lin3 = nn.Linear(256, 10, bias=True) def forward(self, xb): x = xb.view(-1,784) x = F.relu(self.lin1(x)) x = F.relu(self.lin2(x)) return self.lin3(x)
训练模型
现在我们已经定义了我们的模型,我们需要训练它。我们可以使用FastAI的Learner函数,它可以更轻松地利用现代增强优化方法和许多其他巧妙的技巧,如1-Cycle样式的训练。
现在定义Learner类
## Defining the learnermlp_learner = Learner(data=data, model=Mnist_NN(), loss_func=nn.CrossEntropyLoss(),metrics=accuracy)解释一下我们做了什么:
- data = data - 传递Databunch函数
- model = Mnist_NN() - 传递我们定义的MLP模型Mnist_NN
- loss_func = nn.CrossEntropyLoss() - 定义优化损失函数,在本例中我们使用交叉熵损失函数。
- metrics =准确度 - 这只是为了在训练时进行输出。
我们可以试着在训练深度学习模型时找到理想的学习速率。
## Finidng Ideal learning latemlp_learner.lr_find()mlp_learner.recorder.plot()
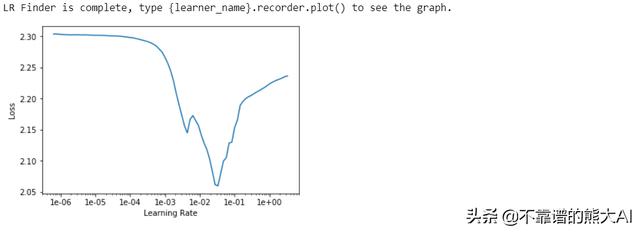
理想情况下,我们要找到斜率最大的点。在这种情况下,该点是1e-2。因此,我们将开始从1e-2作为我们的学习率,并使用fit_one_cycle函数开始五个训练周期,该函数使用1-Cycle样式训练方法。此外,FastAI 在训练时显示tqdm样式进度条,在训练结束时,它开始显示我们在验证数据上定义的损失函数和指标的进度。
mlp_learner.fit_one_cycle(5,1e-2)
通过降低学习速率来对模型进行更多的训练。
mlp_learner.fit_one_cycle(5,1e-3)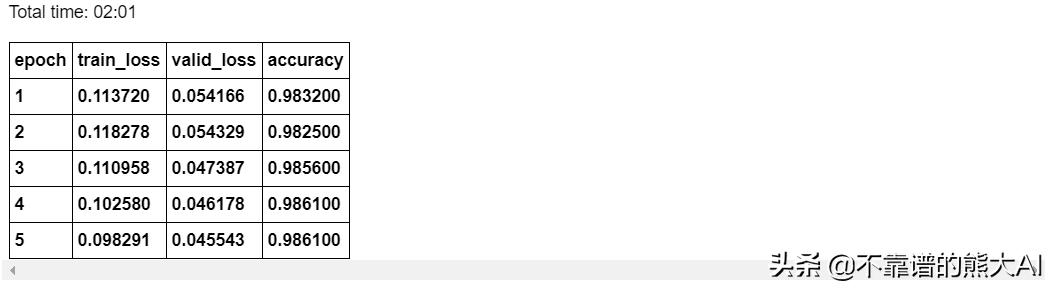
mlp_learner.recorder.plot_losses()我们可以看到,通过使用简单的多层感知器,我们的准确率达到了98.6%。

结论
Fast.ai是Jeremy Howard和他的团队的一项出色的倡议,我相信fastai库可以通过使构建深度学习模型变得非常简单,真正实现将深度学习大众化,让每个人都可以建造自己的深度学习模型。














 3027
3027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









