







 译自《Numerical Optimization: Understanding L-BFGS》,本来只想作为学习CRF的补充材料,读完后发现收获很多,把许多以前零散的知识点都串起来了。对我而言,的确比零散地看论文要轻松得多。原文并没有太多关注实现,对实现感兴趣的话推荐原作者的golang实现。
译自《Numerical Optimization: Understanding L-BFGS》,本来只想作为学习CRF的补充材料,读完后发现收获很多,把许多以前零散的知识点都串起来了。对我而言,的确比零散地看论文要轻松得多。原文并没有太多关注实现,对实现感兴趣的话推荐原作者的golang实现。
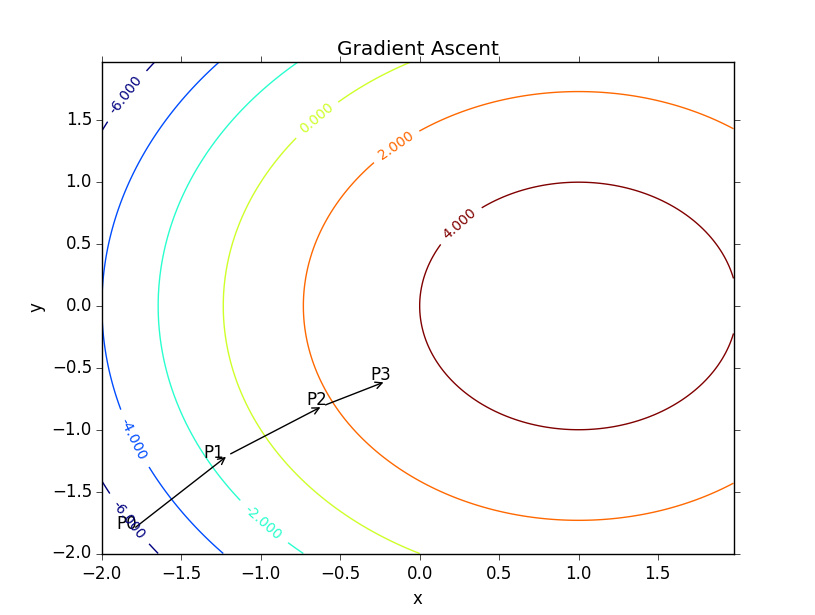
数值优化是许多机器学习算法的核心。一旦你确定用什么模型,并且准备好了数据集,剩下的工作就是训练了。估计模型的参数(训练模型)通常归结为最小化一个多元函数
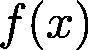 ,其中输入
,其中输入
 是一个高维向量,也就是模型参数。换句话说,如果你求解出:
是一个高维向量,也就是模型参数。换句话说,如果你求解出:
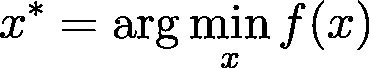
那么
*就是最佳的模型参数(当然跟你选择了什么目标函数有关系)。
在这篇文章中,我将重点放在讲解L-BFGS算法的无约束最小化上,该算法在一些能用上批处理优化的ML问题中特别受欢迎。对于更大的数据集,则常用SGD方法,因为SGD只需要很少的迭代次数就能达到收敛。在以后的文章中,我可能会涉及这些技术,包括我个人最喜欢的AdaDelta 。
注 : 在整个文章中,我会假设你记得多元微积分。所以,如果你不记得什么是梯度或海森矩阵,你得先复习一下。
牛顿法
大多数数值优化算法都是迭代式的,它们产生一个序列,该序列最终收敛于
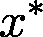 ,使得
,使得
达到全局最小化。假设,我们有一个估计
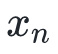 ,我们希望我们的下一个估计
,我们希望我们的下一个估计
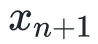 有这种属性:
有这种属性:
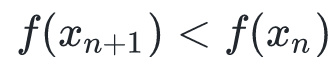 。
。
牛顿的方法是在点
附近使用二次函数近似
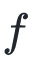 。假设
。假设
是二次可微的,我们可以用
在点
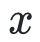 的泰勒展开来近似
的泰勒展开来近似
。

其中,
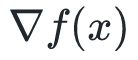 和
和
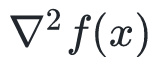 分别为目标函数
分别为目标函数
在点
处的梯度和Hessian矩阵。当
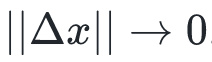 时,上面的近似展开式是成立的。你可能记得微积分中一维泰勒多项式展开,这是其推广。
时,上面的近似展开式是成立的。你可能记得微积分中一维泰勒多项式展开,这是其推广。
为了简化符号
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4123
4123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









