






MapReduce工作原理
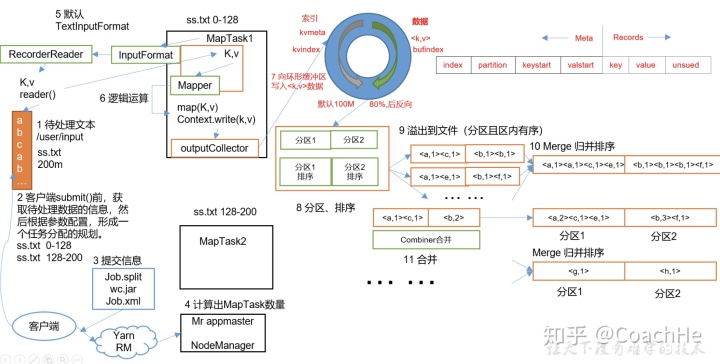
1 Map阶段工作大纲
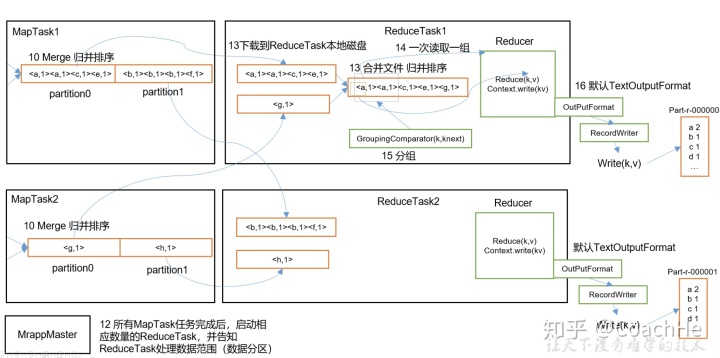
2 Reduce阶段工作大纲
Shuffle机制
1 Shuffle机制简介
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
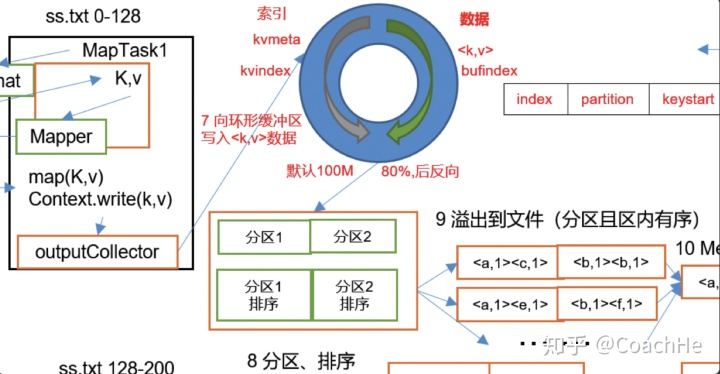
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件
4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
6)ReduceTask会取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
2 Partition分区
① 简介和默认分区方法
问题引出
要求将统计结果按照条件输出到不同文件中(分区)。
比如:
统计京东9月10号某商品top10排行
统计京东9月11号某商品top10排行
因此需要根据时间来进行分区,有几个文件就有几个区。(简单来说,就是有多少reduce就有多少分区)
默认Partitioner分区是HashPartitioner
Public class HashPartitioner<K, V> extends Partitioner<K,V>{
public int getPartition(K key, V value, int numReduceTasks){
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}默认分区方式下,根据key的hashCode对ReduceTasks个数取模得到,用户没法控制哪个key在哪个分区。
这个就是分区数量,也就是输出文件的数量。默认为1,因为默认的输出文件数量就为1
② 源码查看
使用的程序案例是wordcount。
首先在map中的context.write(k,v);打上断点,然后进行调试,可以看到,程序会首先进入map中。
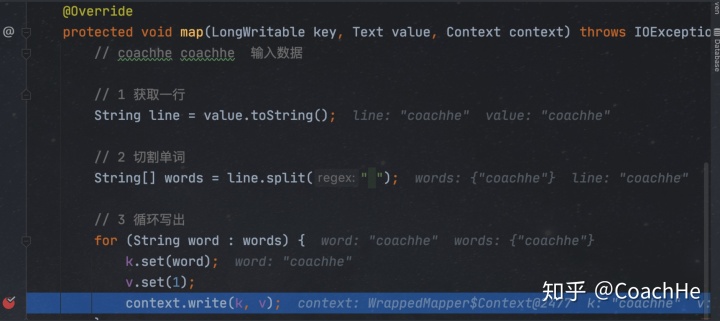
进入之后可以看到:

在这里key是coachhe,value是1
再进入会进入收集器中:

参数为key,value和partition的值。
这个收集器会循环将文件输出到环形缓冲区中,然后缓冲区满了80%之后就会往外写数据到不同的文件中(根据分区)。
进入getPartition中可以看到:
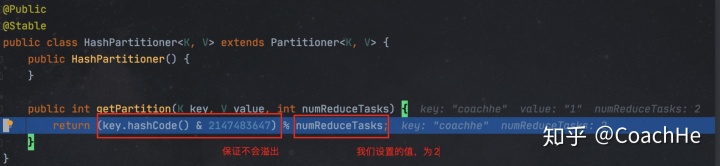
通过当前key的hashCode和numReduceTasks进行求余可以得到分区号(因为若我们设置的numReduceTasks为n那么求余的可能性就只有n种,所以可以将其区分开)。
得到分区号之后进入collect:
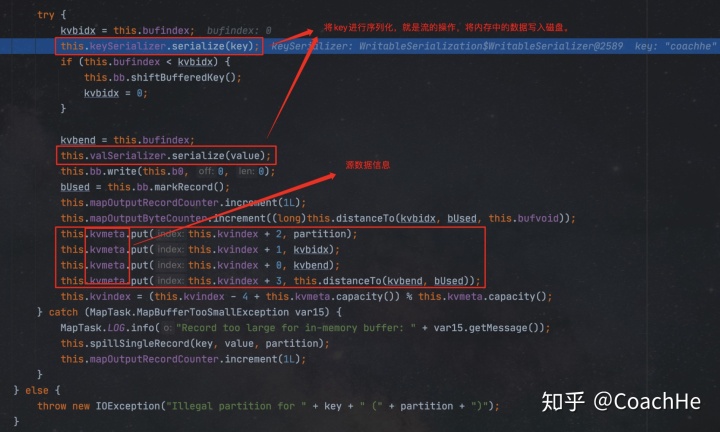
3 WritableComparable排序
简介
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序,该操作属于Hadoop的默认行为。任何应用中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写到磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件带下或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上所有的数据进行一次归并排序。
排序的分类
- 部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件都有序。
- 全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
- 辅助排序(GroupingComparable分组)
在Reduce端对key进行分组。
应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以使用分组排序。
- 二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序
WritableComparable排序案例
全排序案例
需求
根据序列化案例实操产生的结果进行流量的倒叙排序
输入数据
/Users/heyizhi/BigData/hadoop/my_project/WritableComparable自定义排序/phone_data
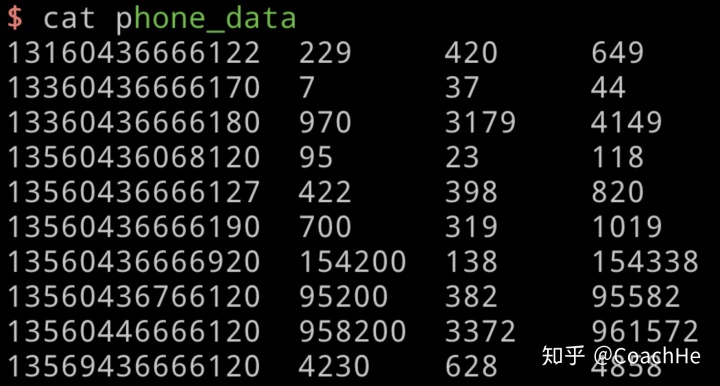
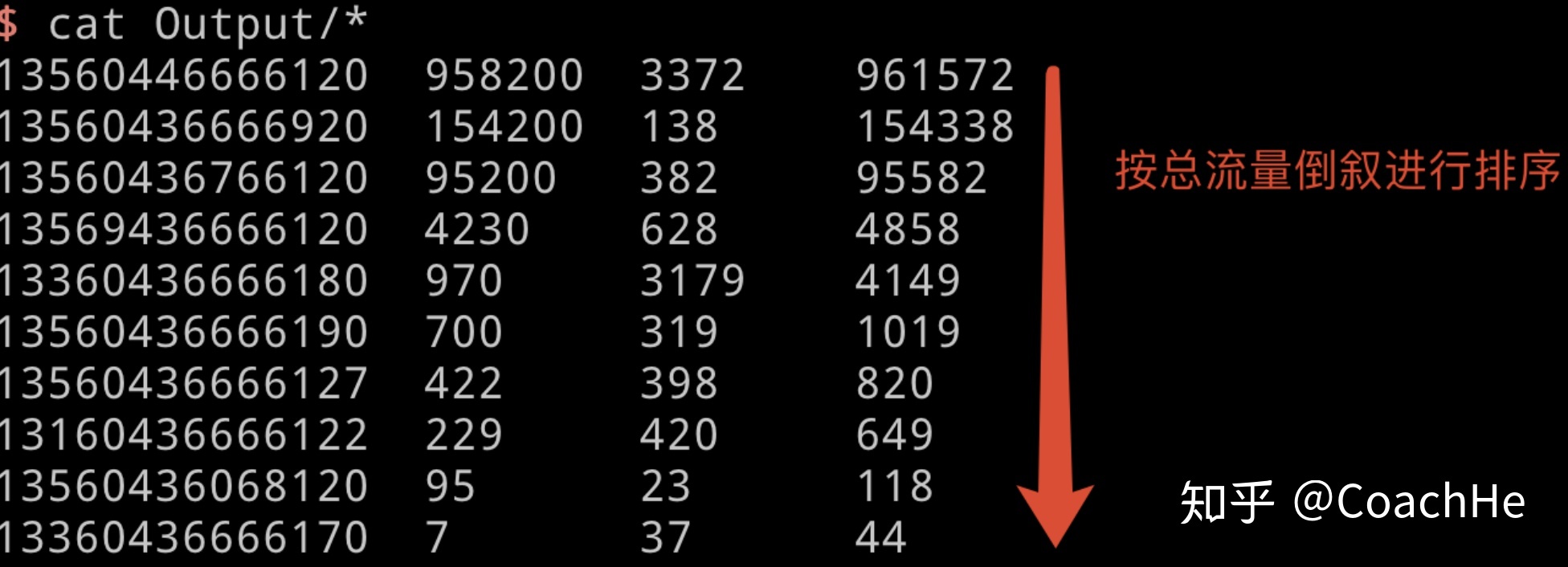
期望输出数据
135XXXX 1234 1234 555
135XXXX 1234 1234 554
135XXXX 1234 1234 553
135XXXX 1234 1234 552
分析
因为MapTask一定会对key进行排序,因此不能像之前那样用手机号作为key,而是一定要用流量作为key。
方法
FlowBean实现WritableComparable接口重写compareTo方法。
@Override
public int compareTo(FlowBean o){
//倒叙排列,按照总流量从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}具体分析

全排序代码实现
FlowBean
package com.coachhe.WritableComparable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow; //上行流量
private long downFlow; //下行流量
private long sumFlow; //总流量
//空参构造,为了后续反射用
public FlowBean(){
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
//序列化方法
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
//反序列化方法,顺序跟序列化方法顺序必须一致
public void readFields(DataInput dataInput) throws IOException {
upFlow = dataInput.readLong();
downFlow = dataInput.readLong();
sumFlow = dataInput.readLong();
}
@Override
public String toString() {
return upFlow + "t" + downFlow + "t" + sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public int compareTo(FlowBean bean) {
//核心比较条件判断
if (sumFlow == bean.getSumFlow()) {
return 0;
}
return sumFlow > bean.getSumFlow() ? -1 : 1;
}
}map
package com.coachhe.WritableComparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
FlowBean k = new FlowBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split("t");
long upFlow = Long.parseLong(line[1]);
long downFlow = Long.parseLong(line[2]);
long sumFlow = upFlow + downFlow;
k.setUpFlow(upFlow);
k.setDownFlow(downFlow);
k.setSumFlow(sumFlow);
v.set(line[0]);
// 4写出
context.write(k, v);
}
}reduce
package com.coachhe.WritableComparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// bean 138XXXX
for (Text phone_num : values) {
context.write(phone_num, key);
}
}
}driver
package com.coachhe.WritableComparable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length == 0) {
args = new String[]{"/Users/heyizhi/BigData/hadoop/my_project/WritableComparable自定义排序/phone_data",
"/Users/heyizhi/BigData/hadoop/my_project/WritableComparable自定义排序/Output"};
}
Configuration conf = new Configuration();
// 1 获取job对象
Job job = Job.getInstance(conf);
// 2 设置jar路径
job.setJarByClass(FlowCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 4 设置mapper输出的key和value类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 5 设置最终输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}结果
分区内排序案例
需求
将每个号码前三位相同的进行分区,然后每个分区按照降序进行排序。
需求分析
基于前一个需求,增加自定义分区类,分区按照省份手机号设置。
输入输出

代码实现
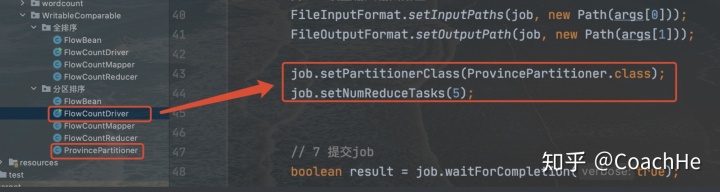
在驱动里面加上这个
FlowBean
package com.coachhe.WritableComparable.分区排序;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<FlowBean, Text> {
public int getPartition(FlowBean flowBean, Text text, int i) {
//按照手机号前三位分区
String prePhoneNum = text.toString().substring(0, 3);
int partition = 4;
if ("136".equals(prePhoneNum)) {
partition = 0;
} else if ("137".equals(prePhoneNum)) {
partition = 1;
} else if ("138".equals(prePhoneNum)) {
partition = 2;
} else if ("139".equals(prePhoneNum)) {
partition = 3;
}
return partition;
}
}GroupingComparator分组
简介
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 比较的业务逻辑
return result;
}(3)创建一个构造将比较对象的类传给父类
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}GroupingComparator分组案例
需求
有如下订单数据
订单
| 订单id | 商品id | 成交金额 | | ------- | ------ | -------- | | 0000001 | Pdt_01 | 222.8 | | | Pdt_02 | 33.8 | | 0000002 | Pdt_03 | 522.8 | | | Pdt_04 | 122.4 | | | Pdt_05 | 722.8 | | 0000003 | Pdt_06 | 232.8 | | | Pdt_07 | 33.8 |
现在需要求出每一个订单中最贵的商品。
输入数据

期望输出数据
1 222.8
2 722.4
3 232.8
需求分析
(1)利用“订单id和成交金额”作为key,可以将Map阶段读取到的所有订单数据按照id升序排序,如果id相同再按照金额降序排序,发送到Reduce。 (2)在Reduce端利用groupingComparator将订单id相同的kv聚合成组,然后取第一个即是该订单中最贵商品
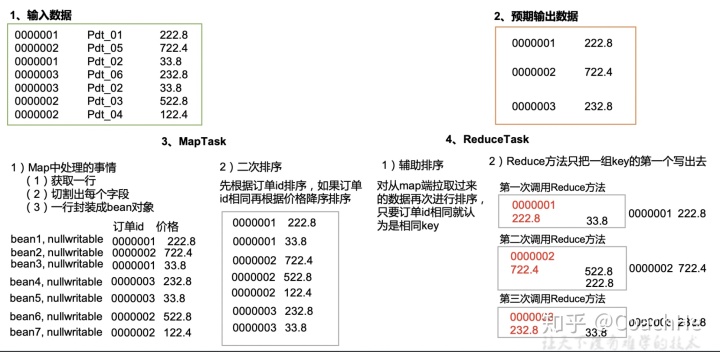
分组原因
对上面的需求进行分析,因为只有key相同才会进入同一个reduce中,但是前面定义的key是OrderBean,比较的是OrderBean里面的价格和id,因此不同的价格和id就会对应不同的OrderBean,因此所有的结果都会进行输出,因此我们需要进行分组排序,目的是让id相同的key就能进入同一个reduce中,那我们就不循环直接输出即可得到价格最大的那个订单!
代码
根据简介中的方法,我们可以得到GroupingComparator的代码为
package com.coachhe.order;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderGroupingComparator extends WritableComparator {
public OrderGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//要求只要id相同,就认为是相同的key
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
// 在这里,如果是0则表示为同一个key
}
}map
package com.coachhe.order;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 0000001 Pdt_01 222.8 输入数据
// 将0000001和222.8封装到bean对象之后输出就行了,不需要value
String[] line = value.toString().split(" ");
k.setOrder_id(Integer.parseInt(line[0]));
k.setPrice(Double.parseDouble(line[2]));
context.write(k, NullWritable.get());
}
}reduce
package com.coachhe.order;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 0000001 Pdt_01 222.8 输入数据
// 将0000001和222.8封装到bean对象之后输出就行了,不需要value
String[] line = value.toString().split(" ");
k.setOrder_id(Integer.parseInt(line[0]));
k.setPrice(Double.parseDouble(line[2]));
context.write(k, NullWritable.get());
}
}bean
package com.coachhe.order;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
private int order_id; //订单ID
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
private double price; //订单价格
public OrderBean(){
super();
}
public OrderBean(int order_id, double price) {
super();
this.order_id = order_id;
this.price = price;
}
public int compareTo(OrderBean o) {
// 先按照订单id进行排序,如果相同按照价格降序排序
int res = 0;
if (order_id > o.getOrder_id()) {
res = 1;
} else if (order_id < o.getOrder_id()) {
res = -1;
} else {
if (price > o.getPrice()) {
res = -1;
} else if (price < o.getPrice()) {
res = 1;
} else {
res = 0;
}
}
return res;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(order_id);
dataOutput.writeDouble(price);
}
public void readFields(DataInput dataInput) throws IOException {
order_id = dataInput.readInt();
price = dataInput.readDouble();
}
@Override
public String toString() {
return "order_id=" + order_id + "t" + "price=" + price;
}
}Driver
package com.coachhe.order;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length == 0) {
args = new String[]{
"/Users/heyizhi/BigData/hadoop/my_project/GroupingComparator分组操作/GroupingData",
"/Users/heyizhi/BigData/hadoop/my_project/GroupingComparator分组操作/Output_Grouping"};
}
Configuration conf = new Configuration();
// 1 获取job对象
Job job = Job.getInstance(conf);
// 2 设置jar路径
job.setJarByClass(OrderDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// 4 设置mapper输出的key和value类型
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 设置最终输出的key和value类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setGroupingComparatorClass(OrderGroupingComparator.class);
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}














 3541
3541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









