







将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。
(一)原理部分
模糊C均值(Fuzzy C-means)算法简称FCM算法,是一种基于目标函数的模糊聚类算法,主要用于数据的聚类分析。理论成熟,应用广泛,是一种优秀的聚类算法。本文关于FCM算法的一些原理推导部分介绍等参考下面视频,加上自己的理解以文字的形式呈现出来,视频参考如下,比较长,看不懂的可以再去看看:
FCM原理介绍
FCM分析1
FCM分析2
FCM分析3
首先介绍一下模糊这个概念,所谓模糊就是不确定,确定性的东西是什么那就是什么,而不确定性的东西就说很像什么。比如说把20岁作为年轻不年轻的标准,那么一个人21岁按照确定性的划分就属于不年轻,而我们印象中的观念是21岁也很年轻,这个时候可以模糊一下,认为21岁有0.9分像年轻,有0.1分像不年轻,这里0.9与0.1不是概率,而是一种相似的程度,把这种一个样本属于结果的这种相似的程度称为样本的隶属度,一般用u表示,表示一个样本相似于不同结果的一个程度指标。
基于此,假定数据集为X,如果把这些数据划分成c类的话,那么对应的就有c个类中心为C,每个样本j属于某一类i的隶属度为uij,那么定义一个FCM目标函数(1)及其约束条件(2)如下所示:
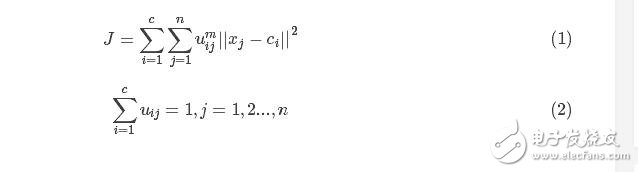
看一下目标函数(式1)而知,由相应样本的隶属度与该样本到各个类中心的距离相乘组成的,m是一个隶属度的因子,个人理解为属于样本的轻缓程度,就像x2与x3这种一样。式(2)为约束条件,也就是一个样本属于所有类的隶属度之和要为1。观察式(1)可以发现,其中的变量有uij、ci,并且还有约束条件,那么如何求这个目标函数的极值呢?
这里首先采用拉格朗日乘数法将约束条件拿到目标函数中去,前面加上系数,并把式(2)的所有j展开,那么式(1)变成下列所示:
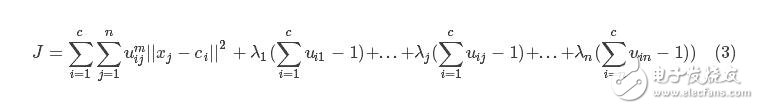
现在要求该式的目标函数极值,那么分别对其中的变量uij、ci求导数,首先对uij求导。
分析式(3),先对第一部分的两级求和的uij求导,对求和形式下如果直接求导不熟悉,可以把求和展开如下:

再来看后面那个对uij求导,同样把求和展开,再去除和uij不相关的(求导为0),那么只剩下这一项:λj(uij−1),它对uij求导就是λj了。
那么最终J对uij的求导结果并让其等于0就是:


我们发现uij与ci是相互关联的,彼此包含对方,有一个问题就是在fcm算法开始的时候既没有uij也没有ci,那要怎么求解呢?很简单,程序开始的时候我们随便赋值给uij或者ci其中的一个,只要数值满足条件即可。然后就开始迭代,比如一般的都赋值给uij,那么有了uij就可以计算ci,然后有了ci又可以计算uij,反反复复,在这个过程中还有一个目标函数J一直在变化,逐渐趋向稳定值。那么当J不在变化的时候就认为算法收敛到一个比较好的结了。可以看到uij和ci在目标函数J下似乎构成了一个正反馈一样,这一点很像EM算法,先E在M,有了M在E,在M直至达到最优。
公式(5),(6)是算法的关键。现在来重新从宏观的角度来整体看看这两个公式,先看(5),在写一遍
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2794
2794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









