







参考链接:http://robotframework.googlecode.com/hg/doc/userguide/RobotFrameworkUserGuide.html?r=2.7.3
RF是基于python语言的,可扩展性关键字驱动测试的自动化框架,主要用于验收测试(AT)和验收测试驱动开发(ATDD)。RF可用于验证时总是要触及多种技术和界面的分布式异构应用程序。
- RF的优势:
1.易用的表格语法创建测试用例
2.能通过已有的关键字创建更高级的可复用关键字
3.提供易读的HTML格式的报告和日志
4.平台和应用程序相互独立
5.提供一个简单的API 库,用户可以用过python/java直接调用来创建自己的测试库
6.为持续集成系统提供了命令行介面及XML格式的输出文件(output.xml)
7.支持 Selenium for web testing, Java GUI testing, running processes, Telnet, SSH
8.支持数据驱动测试(DDT)用例的创建
9.支持变量
10.支持通过tag方式组织和选择要执行的测试用例
11.能很容易的与source control整合:所有的测试集都是一个文件或是文件夹(原文:Enables easy integration with source control: test suites are just files and directories that can be versioned with the production code.)
12.提供了测试用例及测试集级别的setup和teardown
13.模块化结构,对于一些包含各种接口的应用程序也同样能创建测试 - RF的模块化结构:

"test data"可能很简单地用表格格式进行编辑. RF一开始运行,就处理这些测试数据,执行测试用例,并生成日志和测试报告. 而测试中的目标和交互对核心框架来说都是透明的,因为这都是由"test libraries"来控制的. 库可以直接通过应用接口或低级别的"test tools"来驱动测试. - 入口点:
1.执行行测试用例的入口点:python robot\run.py (或者:python –m robot.run)
或执行batchfile: python27\scripts\pybot.bat
2.生成log,report文件的入口点:python robot\rebot.py (或者:python –m robot.rebot)
或执行batchfile: python27\scripts\rebot.bat
3.几个内置工具:
a. libdoc : Library Documation Tool 主要可用于生成指定库或源文件的对应HTML/xml格式的文档,细节参考:http://robotframework.googlecode.com/hg/doc/userguide/RobotFrameworkUserGuide.html?r=2.7.3#libdoc
b. testdoc: Test data Documation Tool 主要可用于将指定测试集生成HTML格式的文档,细节参:http://robotframework.googlecode.com/hg/doc/userguide/RobotFrameworkUserGuide.html?r=2.7.3#testdoc
c. tidy: Test data Clean-up Tool 主要可用于格式化测试用例,或转化测试用格的文件格式,细节参:http://robotframework.googlecode.com/hg/doc/userguide/RobotFrameworkUserGuide.html?r=2.7.3#tidy - 安装&卸载:
1.先装python
2.装RF:pip install robotframework
3.升级已有RF:pip install –upgrade robotframework
4.安装指定版本:pip install robotframework ==2.7.3
5.验证安装是否成功:pybot –version 可以看到RF的版本及python版本
6.卸载:pip uninstall robotframework - Test data 语法: (RIDE)
1. 测试用例位于一个测试用例文件中,一个测试文件默认为一个测试集,一个文件夹类测试集可以包含多个文件类测试集作为子集,也可以包含子文件夹类测试集作。每个测试集文件夹内会包含一个与其子测试用例文件格式相同的__init__文件(后缀与用例文件相同)
2. 测试数据是定义在表格形式的,测试文件格式有:
hypertext markup language (HTML):支持实现字符写入。支持所有编码,如未指出,默认ISO-8859-1。HTML文件需要加META标签,例如:<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">,XHTML文件则用XML序言,例如: <?xml version="1.0" encoding="Big5"?>
tab-separated values (TSV): 文件编码支持UTF-8、由于ASCII是UTF-8的一个子集,所以也支持ASCII
plain text:文件编码支持UTF-8
reStructuredText (reST): RF是不直接分析reST文件的,RF自动通过docutils工具先转换为临时HTML文件再进行分析。此文件在读完后立该删除
可在以下链接中下载相关格式的模板:http://code.google.com/p/robotframework/wiki/Templates
3. Test data 所包含的表格:
- 解析数据的规则:
1. 忽略的数据:- All tables that do not start with a recognized table name in the first cell.
- Everything else on the first row of a table apart from the first cell.
- Data outside tables in HTML/reST and data before the first table in TSV.
- All empty rows, which means these kinds of rows can be used to make the tables more readable.
- All empty cells at the end of rows; you must add a backslash (\) to prevent such cells from being ignored.
- All single backslashes (\); they are used as an escape character.
- All characters following a hash mark (#), if it is the first character of a cell; this means that hash marks can be used to enter comments in the test data.
- All formatting in the HTML/reST test data.

2. 字符转义:
The escape character for the Robot Framework parser is the backslash (\). The escape character can be used as follows:
To escape special characters so that their literal values are used:
\${notvar} means a literal string ${notvar} that looks like a variable
\\ means a single backslash (for example, C:\\Temp)
\# means a literal hash (#) mark, even at the beginning of a cell
To affect the parsing of whitespaces.
To prevent ignoring empty cells at the end of a row in general and everywhere when using the plain text format. Another, and often clearer, possibility is using built-in variable ${EMPTY}.
To escape pipe character when using the pipe and space separated format.
To escape indented cells in for loops when using the plain text format.
To prevent catenating documentation split into multiple rows with newlines.
注意:转义规测只用于argument to keywords、value to settings。不用于诸如keyword names、test case names
3. 空格的控制:
To prevent Robot Framework from parsing data according to these rules, a backslash can be used:
Before leading spaces, for example \ some text.
Between consecutive spaces, for example text \ \ more text.
After trailing spaces, for example some text \ \.
As \n to create a newline, for example first line\n2nd line.
As \t to create a tab character, for example text\tmore text.
As \r to create a carriage return, for example text\rmore text.
Another, and often clearer, possibility for representing leading, trailing, or consecutive spaces is using built-in variable ${SPACE}. The extended variable syntax even allows syntax like ${SPACE * 8} which makes handling consecutive spaces very simple.
- 关键字中参数的使用:
1. 必选参数:参数数目必须关键字文档内指定的一致
2. 参数默认值:通常带有默认值的参数都是可选型,如:arg=default value。关键字的所有参数都可以有默认值
。定义参数时,可选参数后面不可再有位置参数(或称必选参数),如:arg1=v1,arg2.这样是不对的,arg1,arg2=v2则是正确的。
3. 可变数目的参数:属可选型,用于创建可接受不定数目的参数的关键字。定义参数时,可变数目的参数应当位于最后面,如:arg1=v1,*arg2
4. 命名参数:当有多个参数都有默认值时,在使用时,如果只想对最后一个参数赋新值,则需要用到命名参数,如定义了arg1=v1,arg2=v2,使用时如果只想赋值给arg2,则用法应当是:arg2=new,而arg1就自动用默认值v1。这种语法只能用于自定义关键字、使用python静态库(static library API)和混合库(hybrid library API)定义的关键字
5. 关键字名称嵌入参数: 只支持自定义关键字。例字如下:
step1:创建关键字
step2:在用例中使用此关键字
- 测试库的使用:测试库内有最低级别的关键字,而这些关键字才实际和被告测系统交互
1. 引入:可直接在setting中加入Library,当需要带路径时,用“/”,如:
也可直接用关键字Import Library引入Setting Value Value Value Library PythonLib.py Library /absolute/path/JavaLib.java Library relative/path/PythonDirLib/ possible arguments Library ${RESOURCES}/Example.class
2. 测试库搜索路径:先从PYTHONPATH中找模块或类。当前PYTHONPATH的查看方法如下:>>> import os >>> os.sys.path ['D:\\program files\\Python27', 'D:\\program files\\Python27\\Lib\\idlelib', 'D:\\Program Files\\Python27\\lib\\site-packages\\inbox-0.0.5-py2.7.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\logbook-0.3-py2.7-win32.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\gevent-0.13.7-py2.7-win32.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\greenlet-0.3.4-py2.7-win32.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\pip-1.1-py2.7.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\robotframework_ride-0.48-py2.7.egg', 'D:\\Program Files\\Python27\\python27.zip', 'D:\\Program Files\\Python27\\DLLs', 'D:\\Program Files\\Python27\\lib', 'D:\\Program Files\\Python27\\lib\\plat-win', 'D:\\Program Files\\Python27\\lib\\lib-tk', 'D:\\Program Files\\Python27', 'D:\\Program Files\\Python27\\lib\\site-packages', 'D:\\Program Files\\Python27\\lib\\site-packages\\wx-2.8-msw-unicode'] >>> os.sys.path.append("e:\\rf") >>> os.sys.path ['D:\\program files\\Python27', 'D:\\program files\\Python27\\Lib\\idlelib', 'D:\\Program Files\\Python27\\lib\\site-packages\\inbox-0.0.5-py2.7.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\logbook-0.3-py2.7-win32.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\gevent-0.13.7-py2.7-win32.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\greenlet-0.3.4-py2.7-win32.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\pip-1.1-py2.7.egg', 'D:\\Program Files\\Python27\\lib\\site-packages\\robotframework_ride-0.48-py2.7.egg', 'D:\\Program Files\\Python27\\python27.zip', 'D:\\Program Files\\Python27\\DLLs', 'D:\\Program Files\\Python27\\lib', 'D:\\Program Files\\Python27\\lib\\plat-win', 'D:\\Program Files\\Python27\\lib\\lib-tk', 'D:\\Program Files\\Python27', 'D:\\Program Files\\Python27\\lib\\site-packages', 'D:\\Program Files\\Python27\\lib\\site-packages\\wx-2.8-msw-unicode', 'e:\\rf'] >>>
3. 为测试库起化名:Library Selenium2Library WITH NAME S2
使用中,则以化名出现:S2.Open Browser http://www.baidu.com
- 标准库
1. Built-In: 自动引入的一个库,主要提供处理验证,转换类关键字。详见:http://robotframework.googlecode.com/hg/doc/libraries/BuiltIn.html
2. OperatingSystem: 提供对与系统相关的一些关键字。 详见:http://robotframework.googlecode.com/hg/doc/libraries/OperatingSystem.html
3. Telnet: 提供连接Telnet服务器及并执行操作的一些关键字。详见:http://robotframework.googlecode.com/hg/doc/libraries/Telnet.html
4. Collections: 提供处理python中链表和字典的一些关键字。详见:http://robotframework.googlecode.com/hg/doc/libraries/Collections.html
5. String: 提供处理字符串和验证字符串内容的一些关键字。详见:http://robotframework.googlecode.com/hg/doc/libraries/String.html
6. Dialogs: 提供在测试中获取用户输入的一些关键字。详见:http://robotframework.googlecode.com/hg/doc/libraries/Dialogs.html
7. Screenshot: 提供截取和保存整个桌面的一些关键字。详见:http://robotframework.googlecode.com/hg/doc/libraries/Screenshot.html
8. Remote : 大课题!参考链接中的4.2.4节: http://robotframework.googlecode.com/hg/doc/userguide/RobotFrameworkUserGuide.html?r=2.7.3#remote-library-interface - 变量
1. 变量类型有:标量${VAR}、列表@{VAR};大小写不敏感;变量名中的下划线、空格被自动忽略;全局变量建议用大写表示,局部变量建议用小写表示
2.当一个cell中只有一个标量变量时,变量将是所赋于值的原内容,这个值可以是任何对象;当一个cell中有两个标量变量出现时,每个变量值将会首先调用__unicode()__转成Unicode字符串,然后再与其它内容相连。
3. 列表变量内元素访问方式为:@{VAR}[i],i 从0开始。在使用列表变量类的关键字时,列表变量通常会被写成${VAR},前提是,不存在标量变量${VAR},否则会被标量变量赋值所替代
4. 在setting中使用变量:
a. Library: 库的名称不能是列表变量,但可以是标量变量,库的参数可以是任一类型变量
b. Variables: 变量文件的名称不能是列表变量,但可以是标量变量
c. Resource: 不接受列表变量
d. setup & teardown: 名称不能是列表变量,但可以是标量变量,参数可以是任一类型变量
e. tag: 可以是任一类型变量
5. 自动变量:参考列表http://robotframework.googlecode.com/hg/doc/userguide/RobotFrameworkUserGuide.html?r=2.7.3#automatic-variables
6. 扩展变量语法:主要用于标量变量为对象,扩展变量语法允许访问对象属性及调用对象的方法,如:${OBJ.name}, ${OBJ.getage("xiaoming")};扩展变量语法的运算顺序如下:
a. 先找是否有变量批配整个变量名称。如没有,则进行扩展变量语法运算
b. 创建基础变量的真实名称。基础变量是指变量开始连续的字母类字符串,如上例中的OBJ
c. 搜索与基础变量名称匹配的变量。如果不存在,则报异常
d. 基础变量被赋值
e. 整个扩展变量被赋值
下面是一个关于string和number的例子:

7. 扩展变量赋值:可通过关键词返回对扩展变量设置属性,如:${OBJ.name}= set variable hcp,此时对象OBJ的属性name被重新赋值为hcp, 如${OBJ.newAttr}= set variable age,此时,对象OBJ就有了新的属性newAttr,且值为:age;所有的属性赋值在整个测试运行中都有效。扩展变量赋值计算遵守如下规约:
a. 变量必须是标量变量,且变量名称内只少存在一个圆点"." , 否则作为普通变量赋值
b. 如果存在与扩展变量完全一样的普通变量,则不执行扩展变量赋值语法
c. 创建基础变量名称。基础变量名称是指变量内最后一个圆点"."之前的所有字符串。如${foo.zar.zip}中的foo.zar,注意此时的基础变量可能包含了普通的扩展变量语法
d. 创建要设置的属性名称。属性名称指最后一个圆点后面的字符串。如果属性名称不是以字母或下划线开头,而只包含了符号和数字时,则以变量全名创建一个新的变量
e. 搜索与基础变量名相符的变量。如果没有搜到,则以变量全名创建一个新的变量
f. 如果基础变量被赋值为string或number值,则以变量全名创建一个新的变量,因为python中是没法为string和number设置变量的
g. 如果以上规约都符合,则基础变量的属性设置成功。否则报异常且测试fail
8. 嵌套变量:即变量内包含变量,此时变量是由内到外解析的,如果内部变量解析出错,则整个变量异常。如${var${subvar}}
9. 变量文件:标准的python文件。文件中所有非"_"开头的全局属性都当作变量:VAR="robot testing",LIST__VARS=[1,2,3]。当有些属性不想作为充量时,可加前缀"_":import math as _math。也可以将需要作为变量的属性以列表方式赋值给__all__: __all__ = ["VAR1","VAR2"]。另还可以在文件中创建函数get_variables(或getVariables)并可以选择对函数加参数的方式来返回指定的变量列表,因为rf会自动调用get_variables()
10. 作为Class方式导入变量文件:没实践成功 - FOR循环
1. FOR ${var} IN @{list}
2. FOR ${v1} ${v2} IN @{list} : 其中list列表内个数一定要是变量个数的倍数
3. FOR ${v1} IN RANGE 1 10 2: 表示在[1,10)中以步长2取值。步长为空时,默认为1
三种循环的列子: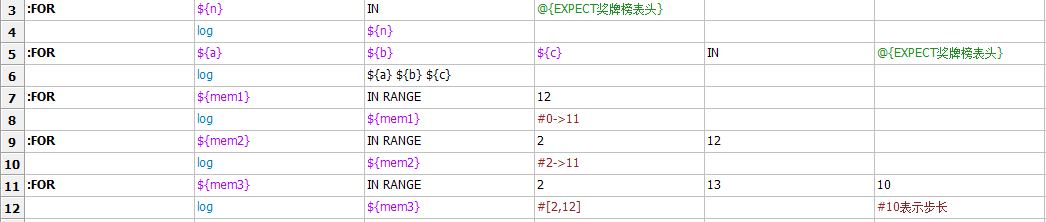
- 相同关键字
1. 作用域:相同关键字的优先级:
a. 在此关键字将要使用的文件内。所有的同名关键字中,此处关键字为最高优先级
b. 在源文件中。此处关键字为第二优先级
c. 在扩测试库中。此处关键字为第三优先级
d. 在标准库中。此处关键字为第最低优先级
2. 用Set Library Search Order关键字可设定搜素顺序。但只在所用的测试集中有效,且如果所设的库/源文件中没有所要的关键字,则测试失败。详见此关键字用法 - 参数用法
1. 运行指定测试用例:bybot --test temp* suite\subsuite.txt 表示执行测试集subsuite中所有以temp开头的测试用例
2. 参数文件:可将参数放入文件中再通过参数--argumentfile使用
3. 启运脚本:
4. 常用参数:@echo off call pybot --variable BROWSER:Firefox --name Firefox --log none --report none --output out\fx.xml login call pybot --variable BROWSER:IE --name IE --log none --report none --output out\ie.xml login call rebot --name Login --outputdir out --output login.xml out\fx.xml out\ie.xml #合并fx.xml和ie.xml生成报告,报告名称为Login,合成后的xml文件为login.xml
--critical tagname 表示把指定tagname的用例设为critical
--noncritical tagname 表示把指定 tagname以外的用例设为critical
--suite 表示要测试的测试集,
--test 表示要测试的测试用例,如果配合--suite参数,则表示在指定的suite中的指定用例被测
--include tagname 表示要测试指定tag的用例 可多次使用,或关系。多个tag,可用&或者NOT
--exclude tagname 表示要测试指定tag外的用例,可多次使用,或关系。多个tag,可用&或者NOT
--name 表示重新set顶级测试集的名称,名称中下划线自动换为空格,名称自动转为大写
--metadata name:value 表示可为所有测试用例设元数据
--settag 表示设置tag,可多次使用以设置多个tag
--pythonpath 表示增加pythonpath中的路径,多个路径用冒号“:”分开,或多次使用
--variable name:value 表示设置单个变量,可多次使用,实现设置多个变量
--variablefile path/to/var.py:argument 表示通过变量文件设置变量,文件参数可以在文件后用冒号“:”设置
--runmode DryRun 表示执行静态检查
--runmode randowm:test 表示单个测试集中的用例随机顺序执行。同类的还有suite表测试集随机,all表suite和test都随机顺序执行
--listener 设置监听者,主要用于监控用例的执行--listener "D:\program files\Python27\lib\site-packages\robotframework_ride-0.48-py2.7.egg\robotide\contrib\testrunner\SocketListener.py:12513
--outputdir(-d) 设置输出文件的目录,目录不存在,自动新建
--output(-o) 设置输出文件名称,默认为output.xml,如果用rebot产生输出文件,则要显式使用此参数,否则只产生log和report文件
--log(-l) 设置日志文件名称,NONE表示不产生日志文件
--report(-r) 设置报告文件名称,NONE表示不产生报告文件
--debugfile(-b) 指定调试文件名称
--timestampoutput(-T) 将当前时间加到所有输入文件的文件名称中:log-20120907-164610.html
--logtitle 设置log标题
--reporttitle 设置report标题
--reportbackground green:red 第一个表示PASS,第二个表示有fail,如果是:green:yellow:red则第一个表示PASS,第二个表示非关键级用例fail,第三个表示存在关键级用例fail
--debuglevel(-L) 设置日志级别,WARN警告,INFO默认认的日志级别,DEBUG调试,失败时记录失败的目体位置,TRACE调试更详细,关键字的参数和返回值自动记录
--splitoutputs 1 project 设置分割输出文件output.xml的级别,1表示级别1,将分割出三个文件,project表示要测的项目















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









