






#####################################################
#本文内容来自《老男孩
linux运维实战培训》学生—郑东旭
#如有转载,请务必保留本文链接及本版权信息。
#欢迎广大运维同仁一起交流
linux/unix网站运维技术!
#QQ:919953500
#E-mail:weilandeshanhuhai@126.com
=====================================================
老男孩
linux运维实战培训中心
咨询
QQ: 70271111 357851641
咨询电话:18911718229
咨询电话:18911718229
网站地址:
http://www.etiantian.org
老男孩博客
: http://oldboy.blog.51cto.com
老男孩的QQ: 31333741
#####################################################
老男孩的QQ: 31333741
#####################################################
本文说明:
绿色为重点 红色为警告或注意
蓝色为提示或说明
黑色为正常输出
===============================================================================
面试经验谈架构
面试经验谈架构
把以前的知识复习一遍,并连串起来
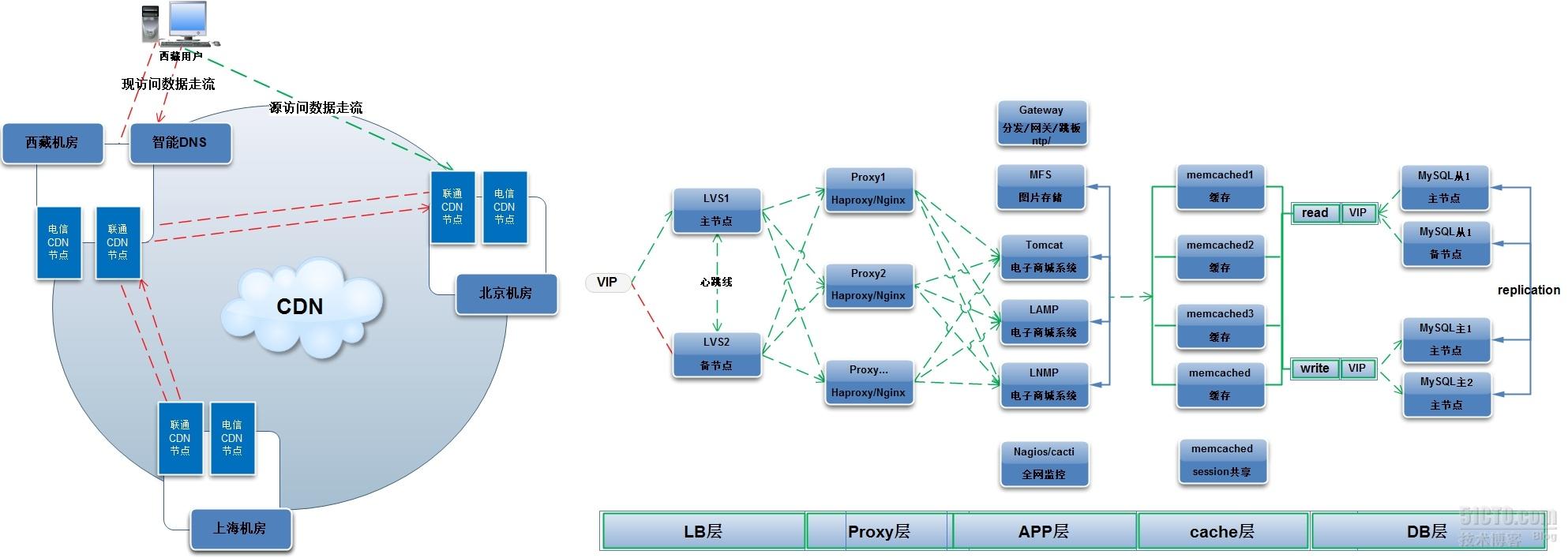
绿色线条为正常数据走流,红色线条为备用线路数据走流
,蓝色线为挂载存储,
CDN网络中红色为同步数据走流
用户请求到达
VIP地址(公网地址,与域名绑定),由四层负载均衡LVS根据自身的算法将用户请求转发到七层负载均衡Proxy代理服务器,代理服务器根据用户的请求(可判断head头部信息)判断用户请求的资源(如:如果用户使用手机访问,代理服务器将请求wap业务机,如果用户使用电脑访问,代理服务器将请求web业务机),
有些公司会有如下的需求,是四层负载均衡做不到的
(1)、代理服务器根据用户的请求
(可判断head头部信息)判断用户请求的资源(如:如果用户使用手机访问,代理服务器将请求wap业务机,如果用户使用电脑访问,代理服务器将请求web业务机)
(2)、如果内网服务器跑多个应用,比如启动多个基于
IP地址的虚拟主机,代理服务器可将用户访问一个地址,转发到不同的应用服务器
(3)、四层和七层负载均衡在中小企业首选七层负载均衡,等以后架构扩展在前端添加四层负载均衡
(原因:七层负载均衡配置简单,不像lvs需要对后端服务器配置操作,并且七层负载均衡可以抵挡千万PV)
当有西藏的用户访问电子商城,如果直接访问北京机房的电子商城,速度会非常缓慢,,大大减少用户访问速度
各地机房放两台
CDN节点服务器(电信和联通)
(1)、无
CDN节点访问流程
西藏联通用户直接访问北京服务器
(绿色线),延迟非常大,有可能页面显示"无法显示该页面"
(2)、
CND节点访问流程
1)、西藏联通用户请求到智能
DNS解析域名
2)、通过智能
DNS解析最近西藏机房域名后返回给用户,用户请求到西藏机房
3)、如果西藏机房
CDN中无用户请求资源,CDN代替用户从上海或北京CDN节点请求用户资源,应答给用户
4)、请求后的资源缓存到本地
CDN节点
2、LB层
lvs+keepalived四层负载均衡高可用
(1)、LVS原理
通过网络地址转换,用户发送请求包到调度器(负载均衡器)的VIP地址,调度器重写请求报文的目标地址,根据预设的算法,将请求分发给后端的真实服务器,真实服务器响应报文通过调度器时,调度器重写报文的源地址,再返回给用户,完成整个负载调度过程
应用范围:由于LVS/NAT模式入站和出站的流量都经过LB,大于处理的后端真实服务器是10-20台
采用
NAT模式时,由于请求和响应报文都经过负载均衡器地址重写,当客户端请求越来越来越多时,调度器的处理能力将成为瓶颈,为了解决这个问题,调度器通过算法把请求的报文通过IP隧道(加密的相当于ipip,或ipsec)分发至后端真实服务器,后端真是服务器将响应直接发送给客户端,这样调度器只处理请求的报文,由于一般网络服务应答数据比请求报文大很多,采用VS/TUN技术后,集群系统的最大吞吐量可以提高10倍
说明:
LVS/TUN不改IP地址,是通过隧道转发,开启隧道会有系统开销,并且响应报文不经过负载均衡器,由真实服务器直接响应给用户
应用范围:LVS/TUN在互联网中用的不多,它可以处理局域网的请求也可处理广域网的请求
LVS/DR模式通过修改请求报文的
MAC地址,将请发送发给后端真是服务器,后端真是服务器将响应直接返回给用户,和VS/TUN模式一样,VS/DR模式可极大提高集群系统的伸缩性,它没有IP隧道的开销,集群系统对后端真是服务器也没有必须支持IP隧道协议的要求,但是要求调度器和所有后端真是服务器都有一块网卡连在同一物理网段上(都在一个网段上)(最后一段话重要,加颜色),因为他是通过数据链路层ARP协议实现的
1、客户端计算机
CIP请求被发送到LVS调度器VIP
2、
LVS调度器收到目标地址为VIP的请求包后,将该数据包的目的MAC地址通过算法改成某一台RS的MAC地址,并通过交换机发送个这台RS服务器,(因为目的MAC地址是RS服务,所以RS服务器可以接受该数据包)注意:此时数据包的目标IP地址和源IP地址没有发生任何改变
3、
RS服务器收到发来的数据报文请求后,会从链路层上传到IP层,此时IP层需要验证请求的目标IP地址,因为包的目标IP地址(Director的VIP地址)并不像常规数据包那样为RS的本地IP,而仅仅目的MAC地址是RS的
这个时候
RS的IP层是验证不过的,因为数据包的目的MAC地址是自己的,数据包目的的IP地址却不是自己的,那么这个时候,网络层就不会把包上传到传输层来处理这个数据包
所以在
RS上需要配置一个VIP的loopback device,因为loopback device是服务器本地使用的网络接口,对外是不可见的,与LVS的VIP不会冲突,(会有一个ARP抑制问题)(RS收到的数据包在自己的网络层验证不过,所以要配置一个loopback device上绑定一个IP地址)
4、
RS处理数据包完成后,将应答包直接返回给客户端CIP,(此时数据包报文的源地址为客户端请求的目的地址VIP,而目的地址为客户端的CIP),应答数据包不会在经过LVS调度器。因此,如果是对外提供LVS负载均衡服务,则RS需要连上互联网(公网IP或网关)才能将应答包返回给客户端,生产环境中RS最好有带公网IP的服务器,这样可以不经过网关直接回应客户端,如果多个RS使用了同一个出口网关,网关可能会成为LVS架构的瓶颈,会大大降低LVS的性能
说明:为什么
RS能直接回应给客户端,因为客户端的请求包报文的源地址和目的地址都没有被调度器在网络层改动,所以根据以太网的协议,回应数据包可以将请求的数据包的源IP当前目的IP,把目标IP当前源IP
应用范围:互联网公司常用的模式
1、可以跨
VLAN通信,支持更多的后端RS
2、有防
DDOS模块
应用范围:淘宝新出的一种模式,占未广泛使用
(2)、DR模式的问题
过程原理:当客户端的请求包到达路由器,路由器会发出广播谁是
VIP,负载均衡器会响应,负载均衡器收到请求包通过自身的算法选择一台RS,(比如RS1)修改客户端请求包的目的MAC地址为RS1的MAC地址并发送给RS1,这个时候RS1的数据链路层把请求包给网络层,网络层需要验证请求包的目标IP地址不是自己就会丢掉此包(此时的数据包源IP是CIP,目的IP是VIP),这个时候需要在RS节点上绑定VIP
过程原理:当客户端的请求包到达路由器,路由器会发出广播谁是
VIP,这个时候,拥有VIP的负载均衡器和RS真实服务器都会响应这个包,导致无法正常工作,所以还有对RS做ARP抑制
RS
绑定VIP地址,一般情况下是绑定到lo网卡上,但我们也可以绑定到其他虚拟网卡,比如eth0:10,设置改网卡的ARP功能即可
思考:RS没有公网地址(dr模式)出站流量怎么走(这个问题有待考证)
负载均衡为
DR模式,后端RS没有公网IP地址,如何将用户请求直接返回给用户
答案:
应答请求不走
LB,直接从路由器返回
(3)、LVS调度算法
|
算法
|
说明
|
|
rr 轮询调度
(Round-Robin)
|
它将请求一次分配不同的
RS,也就是在RS中均摊请求,算法简单,但是只适合于RS处理性能相差不大的情况(多个服务器硬件配置差不多)
|
|
wrr加权轮询调度
(Weighted Round-Robin)
|
它根据
RS不同的权值分配任务,权值高的RS优先获得请求,分配到的连接数将比权值低的RS更多,权值相同的RS得到的连接数数目相同
|
|
wlc加权最小连接数调度
(Weighted Least-Comnection) (WLC)
|
具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
假设各台
RS的权值一次为Wi(l = 1..n),当前的TCP连接数依次为Ti(l=1..n)一次选取Wi/Ti为最小的RS作为下一个分配的RS
|
|
dh 目的地址哈希调度
(Destination Hashing)
|
以目的地址为关键字查找一个静态
hash表来获得需要的RS
|
|
sh 源地址哈希调度
(Source Hashing)
|
以源地址作为关键字查找一个静态
hash表来获取需要的RS
|
|
LBLC 基于局部性的最少链接(
Locality-Based Least Connections)
|
针对目标
IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接” 的原则选出一个可用的服务器,将请求发送到该服务器。
|
|
LBLCR 带复制的基于局部性最少链接(
Locality-Based Least Connections with Replication)
|
也是针对目标
IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标 IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按“最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
|
|
DH 目标地址散列(
Destination Hashing)
|
根据请求的目标
IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
|
|
SH 源地址散列(
Source Hashing)
|
根据请求的源
IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
|
|
SED 最短的期望的延迟(
Shortest Expected Delay Scheduling SED)
|
基于
wlc算法
ABC三台机器分别权重
123 ,连接数也分别是123。那么如果使用WLC算法的话一个新请求进入时它可能会分给ABC中的任意一个。使用sed算法后会进行这样一个运算
A(1+1)/1
B(1+2)/2
C(1+3)/3
根据运算结果,把连接交给
C 。
|
|
NQ 最少队列调度(
Never Queue Scheduling NQ)
|
无需队列。如果有台
realserver的连接数=0就直接分配过去,不需要在进行sed运算
|
提示:现在大约有12中算法常用的有算法有:rr,wrr,wlc
(4)、keepalived高可用两大功能
ha failover 功能:实现
LB Master主机和LB Backup主机之间故障转移和自动切换
这是针对有两个负载均衡器
Director同时工作而采取的故障转移措施,当主负载均衡器(Master)失效或出现故障时,备份负载均衡器(Backup)将自动接管主负载均衡的所有工作,一旦主负载均衡器(Master)的故障恢复,Master又会接管原来处理的工作,而备份负载均衡器(Backup)会释放Master失效时它接管的工作,此时两者将恢复到各自最初的角色状态
rs healthcheck功能:负载均衡定时检查
RS的可用性决定是否给分发请求
当虚拟服务器中的某一个甚至多个真实服务器同时发生故障无法提供服务时,负载均衡器会自动将失效的
RS服务器从转发列队中清除出去,从而保证用户的访问不受影响,当故障的RS服务器修复以后,系统又会自动的将它们加入到转发列队中,分发请求提供正常服务
心跳:
heartbeat:主节点和备节点相互检测对方是否存活
脑裂:
split-brain:两端都认为对端有问题,备节点无法检测到主节点的心跳(一般是心跳线故障),各自都自动起VIP,这种冲突的问题就叫裂脑
3、Proxy层
haprox/nginx/apache七层负载均衡
前文已经说过了“为什么要使用七层负载均衡”
4、App层
(1)、lamp & lnmp
生产环境中
web应用程序只用一种,要么apache要么nginx,图中只是作者在做实验时,将两者混用了
(2)、Java
有些公司的页面是由
java编写的,而使用java容器,场景的java容器有:tomcat resin weblogic jboss跑
java程序
前两者是免费的,后两者是收费的
(3)、MFS
分布式文件系统,解决
nfs单点故障问题
1)、MFS读进程机制
1
、客户端向元数据服务器发出读请求
2
、元数据服务器吧所需数据存放的位置
(Chunk Server
的
IP
地址和
chunk
编号
)
告知客户端
3
、客户端向已知的
Chunk Server
请求发送数据
4
、
Chunk Server
向客户端发送数据
特点:数据传输并不通过元数据服务器,这样既减轻了元数据服务器的压力,同时也增大了整个系统的吞吐能力,在多个客户端读取数据时,会被分散到不同的数据服务器请求
2)、MFS写进程机制
1、客户端向元数据服务器发送写请求
2、元数据服务器与Chunk Server进行交互(只有当所需的分块Chunks存在的时候才进行交互)
(1)
、元数据服务器只在某些服务器创建新的分块chunks
(2)、Chunk Server告知元数据服务器,步骤a已经操作成功
3、元数据服务器告知客户端,你可以在哪个Chunk Server的哪些chunks写入数据
4、客户端向指定的Chunk Server写入数据
5、Chunk Server与其他的Chunk Server进行数据同步
6、Chunk Server之间同步成功
7、Chunk Server告知客户端数据写入成功
8、客户端告知元数据服务器本次写入完毕
(4)、Gateway(网关服务器)
有上网需求时:内网服务器通过该网关服务器上网
5、Cache层
memcached应用非常广泛,如:数据库的查询请求、
session同步、前端web用户请求
(2)、memcache原理
1.接到客户请求后首先查看请求的数据是否在
mem中存在,如果存在,直接返回给用户
2.如果不存在,就去查询数据库,把从数据库中获得的数据返回给用户,同时存在
mem中一份,以后再有用户需要这个数据就直接返回给用户
3.每次更新了数据库
(增删改查)以后,mem会同时更新数据,保证memcache中的数据和数据库的数据一致
4.当分配给
memcache内存空间用完后,会使用LRU(Least Recently Used最近最少使用)策略加到期失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据
5.服务停止后,缓存中的数据就会丢失
(2)、什么是Session
说明:该图片由网友所画
存放用户登录信息
集群环境
一个用户访问请求被分配到服务器A,并且在服务器A登录了,并且在很短的时间,这个用户又发出了一个请求,如果没有会话保持功能的话,这个用户的请求很有可能会被分配到服务器B去,这个时候用户在服务器B上是没有登录的,所以又要重新登录,但是用户并不知道自己的请求被分配到了哪里,用户的感觉就是登录了,怎么又要登录,用户体验很不好。
session文件
#ls /tmp
sess_4tsn40hhhk4fjpc5nfqd7klla4
sess_eoej5vhddfnqulbjef24dqq926
sess_qjr829a27dhascevs36mg5c855
sess_53kcemteriqguf7q847nnsj4n3
1).
基于NFS
的Session
共享
2).
基于数据库的Session
共享
3).
基于Cookie
的Session
共享
4).
基于Memcache
的Session
共享(
推荐)
6、DB层
面试必问
(1)
、当有数据写入到master,执行的SQL语句会写入到binlog日志中(select查询语句不记录)
(2)
、Slave的IO线程会通过Master上授权的复制用户请求连接Master服务器,请求从指定Binlog日志文件的指定位置之后的Binlog日志内容(日志文件和位置是在配置主从服务时执行change master命令时指定的)
(3)
、Master服务器接收到Slave服务器的IO线程请求后,Master上负责复制的IO线程根据Slave上的IO线程请求的信息读取指定Binlog日志文件制定位置之后的Binlog日志内容,然后返回给Slave端的IO线程,返回的信息中还包括本次返回的binlog日志内容后在Master服务端的新的Binlog文件名称以及Binlog的位置点
(4)
、Slave的IO线程获取到来自Master的IO线程发来的日志内容及日志文件及位置点后,将新的binlog日志位置点存放到master-info中,以便下次读取Master端新Binlog日志时能够告诉Master需要从新Binlog日志的那个文件那个位置开始请求新的Binlog日志内容。并将Binlog日志内容一次写入到Slave端自身的Relay Log(中继日志)文件的最末端(MySQL-relay-bin.xxxx)
(5)
、Slave端的SQL线程会实时的检测本地Relay Log新增加的日志内容,然后及时的把Real Log文件的内容解析成在Master端曾经执行的SQL语句的内容,并在自身Slave上按语句的顺序执行应用这些SQL语句
(6)
、经过上面的过程,就可以确保在Master端和Slave端执行了同样的SQL语句,当复制状态正常情况下,Master端和Slave端的数据完全一致
(2)、MySQL主从同步注意事项
1
、主库和从库的版本要完全相同
2
、主库和从库的server-id不能一样(一般为IP地址的最后一位)
3
、主库需要开启binlog日志功能,从库无需开启binlog日志功能,除非做双主模式和级联复制模式
(3)、MySQL主从同步解决方案
方案一:MySQL主从同步
方案二:MySQL一主多从架构
方案三:MySQL多实例主从同步(互为主从)
方案四:MySQL双主架构
方案五:MySQL多主(拆库拆表)
方案六:MySQL级联复制
由开发人员参与
备份时,从库停止
SQL线程,备份后开启SQL线程,保证不丢失数据,如果要求比较严格可以备份binlog日志
mysql+heartbeat+drbd
mysql+heartbeat+replication
mysql+heartbeat+存储
说明:也可以用keepalived做高可用软件
数据库脑裂非常危险,会导致数据不一致,
(8)、MySQL高可用脑裂解决方法
R710有四个网口,一般无特殊情况只用其中两个,剩下两个在插两根心跳线
转载于:https://blog.51cto.com/shanhu/1069909















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









