







何为站在巨人的肩膀上?
GoogleNet是一个复杂的深度学习网络结构,在后文中会有其结构图片。此网络中用到卷积操作、最大池化操作、平均池化操作、Merge操作(Concat)、全连接操作和dropout操作,分布于不同的位置中的每个操作都会因着参数的不同而使用多次。理解了GoogleNet之后,我们可以总结如下:LeNet是最受欢迎的CNN网络结构的始祖,接下出现了为了识别物体的更大型精度更高的网络AlexNet和VggNet,可是这两个网络真的是太大了,参数太多了,如此庞杂的网络和复杂的模型如何适应正在飞速发展的移动时代,随着Network in Network文中提出的卷积全连接结构,即1×1的卷积层来提取特征的风刮向学术界和工业界,多层感知机臃肿的时代意味着即将结束,不是说我们不会去应用全连接层,而是我们会尽量减少全连接层的使用,从而减少大型的参数。SqueezeNet的提出开启了一个新的时代,1×1的卷积层和3×3的卷积层分别具有不同提取特征的能力,我们可以将其merge一下,由纵向的罗列转换成横向的添加,使得如同电线杆一样的网络丰满了不少,GoogleNet的出现似乎是AlexNet,VggNet和SqueezeNet的综合结晶,网络虽为复杂,但不臃肿,为未来移动端做个铺垫吧。
GoogleNet模型属于深度学习模型的一种。在深度学习处理问题的过程中,我们只需要做好这三样工作:
- 明确的输入
- 黑匣子(由输入到输出的映射关系)
- 一个或多个明确的输出
首先,输入就是我们需要训练的大量数据,本文中的输入就是分为5类的共5000多张图片所经过处理的4维张量(Tensor);输出就是所有训练数据对应的标签label(分别为0,1,2,3,4,5),比如我们设置狗狗对应的标签为0,校车对应的标签为1等等;这个俗称为黑匣子的,就是我们所说从输入到输出的映射就是我们需要借助深度学习的工具来建立这种关系,也是我们称之为模型的搭建。本文中,图片处理成4维张量的工具是OpenCV和Python skimage;label处理成One-Hot编码;搭建模型用到的工具是Tensorflow。
准备数据集
ImageNet官网中的图片的种类和数量非常之多,为了研究问题,笔者选择5类物体(铃铛,狗狗,高尔夫球,校车和iPod),每一类物体大约1000多个。所以,我们需要将所有下载的图片处理成4维张量,其格式为(图片数量,长,宽,3),其中由于图片是彩色的具有RGB值,自然张量最后一位是3,即通道数。如下是处理大量图片的部分代码,笔者代码并非最优,只是解决笔者需要的图片处理问题。
import cv2
import numpy as np
from skimage import io
image = io.imread(trainFile)
image = cv2.resize(image, (60, 60))
image = image * 1.0 / 255
image = np.array(image)
if image.shape != (60, 60, 3):
file_object.write(trainFile + '\n')
continue
image = image.reshape(1, 60, 60, 3)
feature = np.concatenate((feature, image), axis=0)import numpy as np
trainfile = open("train_label.txt","r")
label = []
line = trainfile.readlines()
for i in range(len(line)):
label.append(int(line[i]))
trainfile.close()
Y_train = np.array(label)
Y_train = np.eye(5)[Y_train]首先我们需要导入Python一些库,本例中用到cv2,numpy和skimage,都需要自行下载和安装(cv2的配置需要在本地配置OpenCV),然后我们读取我们所有的文件,再将我们的图片的长和宽重新复制,本文中规定的大小是60×60。Google和很多大牛们都喜欢将大小设置为224×224,笔者并非专业AI领域人员,机器性能有限,所以重置图片大小为60×60。后文中会提到映射关系是Y=Wx+b,通常W是服从正太随机分布,其大小的范围是(-1,1),所以我们要将我们的4维图片张量进行归一化操作,使我们的输入的范围在(-1,1)。上述代码中,笔者加入了一个判断,由于ImageNet图片集中的图片有合成的有自然的,有黑白的也有彩色的。笔者处理模型的过程中通道数都用的是3,所以我们要去除掉黑白的图片。最后我们将其加入到我们的训练集初始化feature矩阵中,得到我们可以使用的feature张量,其维度是(5284,60,60,3),验证集处理和训练集处理的方法相同。如下图所示,显示了训练集和测试集feature张量的shape(图后半部分暴露了笔者调用GPU的信息,显卡不是很高端GTX1060滴)。关于label数组的处理,我们首先要把图片和对应的label对应上,最好写在一个txt的文件中,然后用一个数组将文件中的内容读出,转换成numpy数组后在用numpy中eye函数将其变为One-Hot编码
至此,我们对输入和输出的准备工作就完成了,接下来就是模型的设计。
搭建类GoogleNet
为何说是类GoogleNet呢?
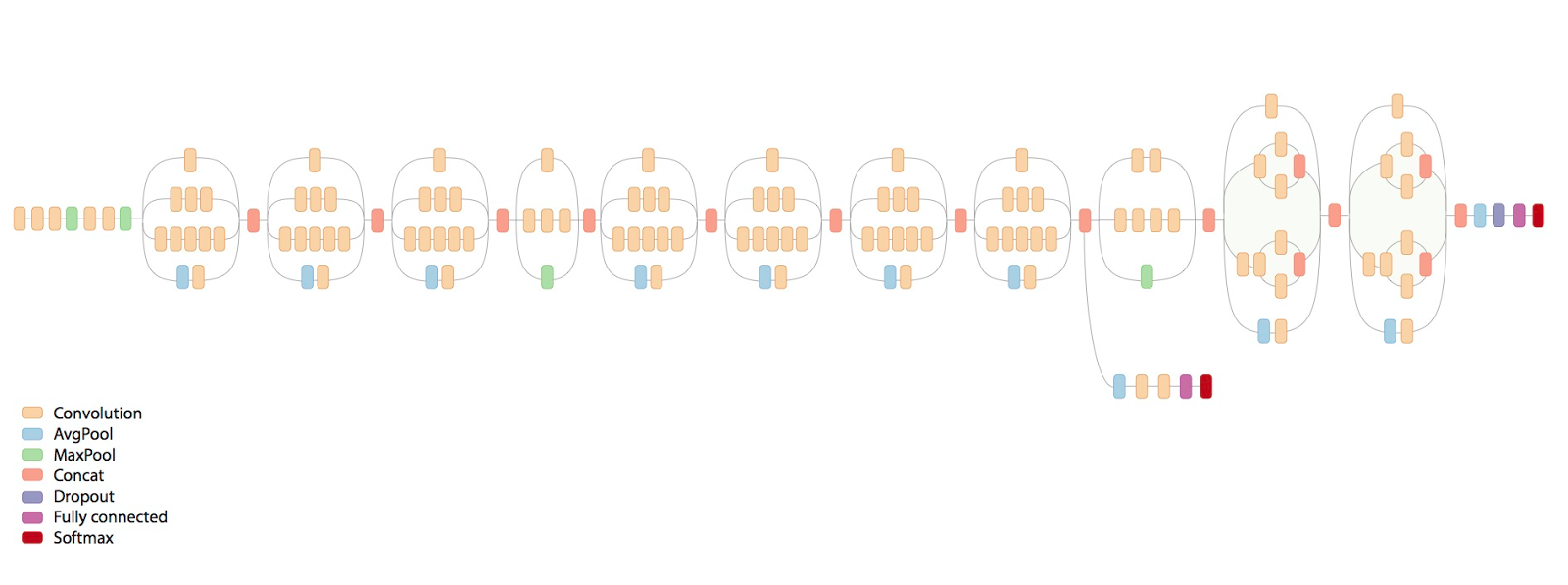
因为下图就是真正的GoogleNet。要完成这个模型的训练,我的msi GTX1060还真没那么大的本事,这个模型的训练需要至少是需要Titan的工作站和多块Titan的显卡完成的,我的机器还是比较脆弱的,所以要根据GoogleNet的思想制定适合的模型来完成验证。
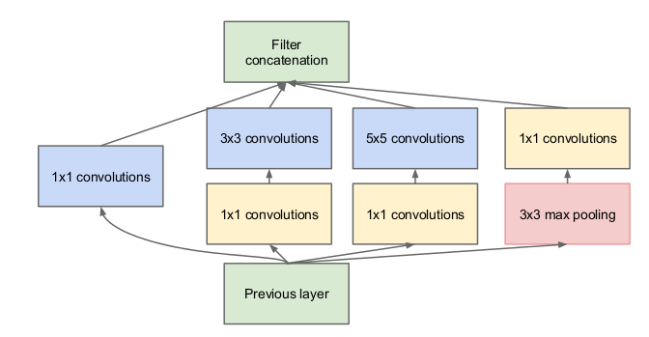
GoogleNet中一个重要的思想是Inception,Inception层是由不同的层次结构组合而成的一个层。下图中,上一层的输出经过以下四种方式进行处理:
- 1×1的卷积操作
- 1×1的卷积操作后再经过3×3的卷积操作
- 1×1的卷积操作后再经过5×5的卷积操作
- 3×3的最大池化操作后再经过1×1的卷积操作
下面笔者用简单的两块代码示例来说明Inception模块
#Layer Inception
with tf.name_scope('layer2-inception'):
with tf.variable_scope('conv2_1'):
W_conv2_1x1_1 = tf.Variable(tf.truncated_normal([1, 1, kernels1, 32], dtype=tf.float32,
stddev=1e-1), name='weights')
variable_summaries(W_conv2_1x1_1, 'W_conv2_1x1_1')
b_conv2_1x1_1 = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32),
trainable=True, name='biases')
variable_summaries(b_conv2_1x1_1, 'b_conv2_1x1_1')
conv2_1x1_1 = tf.nn.conv2d(pool1, W_conv2_1x1_1, [1, 1, 1, 1], padding='SAME')
conv2_1x1_1_sum = tf.nn.bias_add(conv2_1x1_1, b_conv2_1x1_1)
conv2_1x1_1_relu = tf.nn.relu(conv2_1x1_1_sum)
with tf.variable_scope('conv2_2'):
with tf.variable_scope('conv2_2_1x1'):
W_conv2_1x1_2 = tf.Variable(tf.truncated_normal([1, 1, kernels1, 32],
dtype=tf.float32,stddev=1e-1), name='weights')
variable_summaries(W_conv2_1x1_2, 'W_conv2_1x1_2')
b_conv2_1x1_2 = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32),
trainable=True, name='biases')
variable_summaries(b_conv2_1x1_2, 'b_conv2_1x1_2')
conv2_1x1_2 = tf.nn.conv2d(pool1, W_conv2_1x1_2, [1, 1, 1, 1], padding='SAME')
conv2_1x1_2_sum = tf.nn.bias_add(conv2_1x1_2, b_conv2_1x1_2)
conv2_1x1_2_relu = tf.nn.relu(conv2_1x1_2_sum)
with tf.variable_scope('conv2_2_3x3'):
W_conv2_3x3_2 = tf.Variable(tf.truncated_normal([3, 3, 32, 32], dtype=tf.float32,
stddev=1e-1), name='weights')
variable_summaries(W_conv2_3x3_2, 'W_conv2_3x3_2')
b_conv2_3x3_2 = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32),
trainable=True, name='biases')
variable_summaries(b_conv2_3x3_2, 'b_conv2_3x3_2')
conv2_3x3_2 = tf.nn.conv2d(conv2_1x1_2_relu, W_conv2_3x3_2, [1, 1, 1, 1], padding='SAME')
conv2_3x3_2_sum = tf.nn.bias_add(conv2_3x3_2, b_conv2_3x3_2)
conv2_3x3_2_relu = tf.nn.relu(conv2_3x3_2_sum)首先呢,我的类GoogleNet模型的第一层采用的是传统的卷积+池化的操作;第二层就用到Inception层;第三层采用全连接操作;第四层就是分5类的输出层。简单的想一想,无非是将传统的LeNet中第二层的卷积+池化的操作层换成Inception。上述代码解释了Inception结构中左边的两个模块,笔者可以选用tf.slim来搭建这个网络结构,或者用keras更能快速的搭建Inception层,但由于Tensorflow有可使模型可视化的Tensorboard,Tensorboard具有保存很多变量模型等等信息的功能,所以,笔者坚持臃肿的一层一层的去写W和b,为的是在Graph中可以获得内存和computing等无价的信息。代码中conv2_1就是建立一个1×1的卷积操作;conv2_2包括两个模块conv2_2_1×1和conv2_2_3×3,即1×1的卷积操作后将其输出作为下一层3×3的卷积操作的输入。
with tf.variable_scope('merge'):
inception = tf.nn.relu(tf.concat(3, [conv2_1x1_1_relu,
conv2_3x3_2_relu,
conv2_5x5_3_relu,
conv_1x1_4_relu]))Inception层中我们会得到四个模块最后的输出:
- conv2_1×1_1_relu
- conv2_3×3_2_relu
- conv2_5×5_2_relu
- conv_1×1_4_relu
我们将其合并成一个输出,并采用relu的激励函数。这样,一个完整的较为基础的Inception层就这样搭建完了,Inception还有其他的搭建结构,不过都是大同小异,笔者认为,掌握一个通用的方法是非常必要的。
验证类GoogleNet
sess = tf.InteractiveSession()
merged = tf.summary.merge_all()
saver = tf.train.Saver()
train_writer = tf.summary.FileWriter('train/', sess.graph)
test_writer = tf.summary.FileWriter('test/', sess.graph)
run_options = tf.RunOptions(trace_level = tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
tf.global_variables_initializer().run()
for i in range(60000):
if i % 10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict = feed_dict(False),
options = run_options, run_metadata = run_metadata)
test_writer.add_summary(summary, i)
print("step %d, training accuracy %g" %(i, acc))
else: # Record train set summaries, and train
if i % 100 == 99: # Record execution stats
summary, _ = sess.run([merged, train_step], feed_dict = feed_dict(True),
options = run_options, run_metadata = run_metadata)
train_writer.add_run_metadata(run_metadata, 'step %d ' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else:
summary, _ = sess.run([merged, train_step], feed_dict = feed_dict(True))
train_writer.add_summary(summary, i)
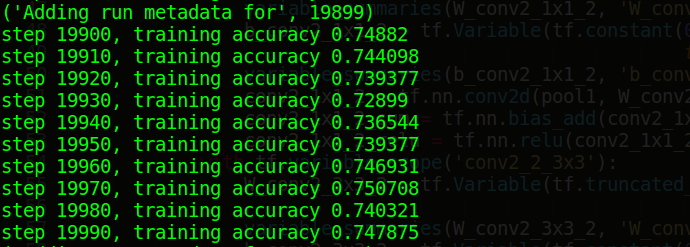
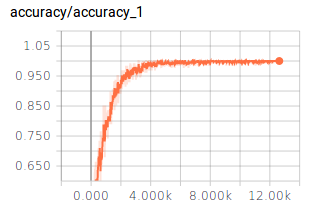
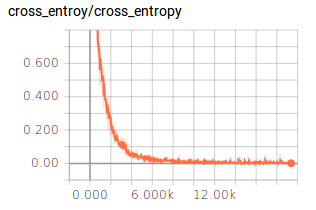
笔者认为Tensorflow比较好玩而且直观的就是Tensorboard可视化工具,Tensorboard可以进行模型的可视化,调试以及模型运行过程中所采集信息的展示,如下代码展示了如何收集训练的信息和测试的信息,没训练10次我们会用测试1000多条测试数据进行测试,并将测试结果打印出来,如下图展示了迭代了20000过程中测试数据的变化情况。虽然精度最高不到76%,但是相对于5000多条的图片训练数据和相对简单的网络结构来说,还算比较理想。Tensorflow的训练过程并非将所有的数据都放在内存中训练,而是采用分批次的方式,此实验中我们的batch大小为128,而测试的验证集数据全部放进,进行测试。
所以,在我们拟合数据的过程中,我们将训练和数据分开来看,如果是加载训练数据,我们需要一个batch的数据(128个),并且设置dropout层中dropout rate的参数值为0.5;如果是加载测试数据,我们将10000多个数据全部放入,并设置dropout rate的参数值为1。next_batch函数的编写如下所示,主要用到numpy库中shuffle函数来洗牌打乱数据集的顺序,并从中随机抽取,保证我们训练的随机和准确。
def feed_dict(train):
if train:
batch_xs, batch_ys = next_batch(X_train, Y_train, batch_size)
k = 0.5
else:
batch_xs, batch_ys = X_test, Y_test
k = 1.0
return {x: batch_xs, y_: batch_ys, drop_rate: k}
def next_batch(feature, label, _batch_size):
num_examples = len(feature)
index_in_epoch = 0
start = index_in_epoch
index_in_epoch += _batch_size
if index_in_epoch < num_examples:
perm = np.arange(num_examples)
np.random.shuffle(perm)
feature = feature[perm]
label = label[perm]
start = 0
index_in_epoch = _batch_size
assert _batch_size <= num_examples
end = _batch_size
return feature[start:end], label[start:end]
下图用Tensorboard直观的展示了我们搭建模型的结构,以及训练保存模型的过程,对于Tensorflow这种平台来数,我们可以简单的理解为tensor + flow,就是tensorflow最核心的用法了,的确够简介。
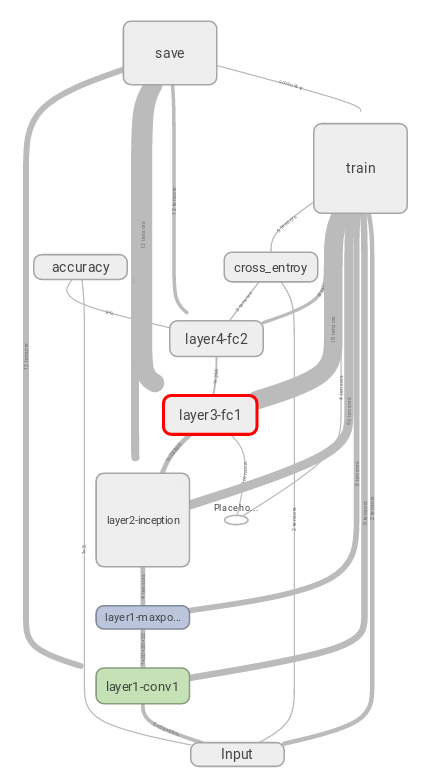
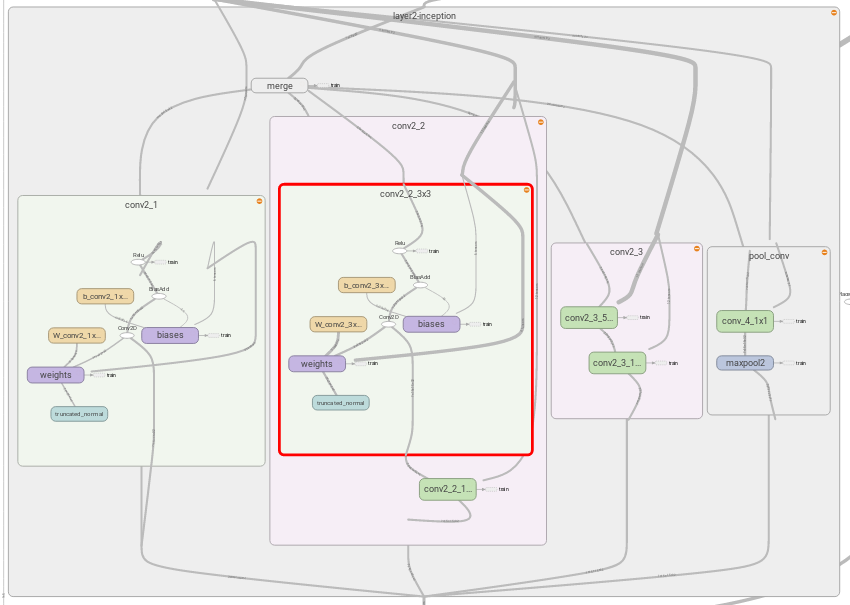
我们上面臃肿的代码真正的用意就在于此,每个Scope中都记录了详细的信息,其中包括我们设置的卷积核,偏移值的信息,而且通过Tensorboard我们还会知道在这个过程中,计算量是怎么产生的,内存占用情况等等,这个图就是Tensorflow实现Inception层的结果,也就是上文的具体解释
接下来的这两个图就是打印出在训练模型过程中训练精度的变化曲线和交叉熵变化的曲线图,这两个图我们都可以从Tensorboard中直接获取,美中不足的是精度曲线的最大值为1.00,1.05是什么鬼!
还想说点什么...
对于GoogleNet自己动手的实现纯属偶然,其主要原因是需要GoogleNet识别较少分类的模型,百度和谷歌搜一下吧?
Negative!
那么就谷歌看看有没有完成这个GoogleNet模型搭建的直接源码吗?有,下面这个
TensoFlow之深入理解GoogLeNet
普通的,没有高端的机器可以运行吗?
Negative!
(虽然GTX1060 6G已经满给力了,毕竟人家是用至少4个Titan来训练的)
所以呀,看看模型,其实也并没有那么难理解,之前动手做过SqueezeNet和Network in Network这两篇文章的模型实现,所以对Inception模块的实现也就是多多细心的问题,如果有问题和对这个感兴趣的朋友留言给我,需要感受运行源码的朋友也可以给我发邮件,下面是我的邮箱
nextowang@stu.xidian.edu.cn
感谢阅读,期待您的反馈!















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









