






近期频频登上头条的几项研究大多如此:比如利用算法识别犯罪团伙或者,利用图像识别判定同性恋。
这些问题的出现往往是因为历史数据中的偏差特征,比如种族和性别上的小众团体,往往因此在机器学习预测中产生不利的歧视结果。在包括贷款,招聘,刑事司法和广告在内的各种广泛使用AI的领域,机器学习因其预测误差伤害到了历史上弱势群体,而广受诟病。
本月,在瑞典斯德哥尔摩举行的第35届机器学习国际会议上,伯克利AI研究协会发布了一篇论文,来试图解决这一问题。

这篇文章的主要目标,是基于社会福利的长期目标对机器学习的决策进行了调整。
通常,机器学习模型会给出一个表述了个体信息的分数,以便对他们做出决定。 例如,信用评分代表了一个人的信用记录和财务活动,某种程度上银行也会根据信用评分判断该用户的信誉度。本文中将继续用“贷款”这一行为作为案例展开论述。
如下图所示,每组人群都有信用评分的特定分布。
信用评分和还款之间的分布
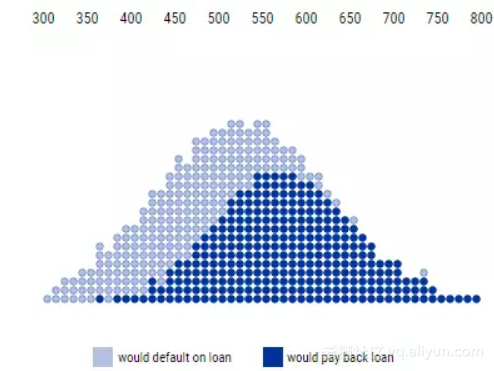
上图中,最上面的数字表示信用评分,评分越高表示偿还能力越强。每一圆圈表示一个人,深蓝色的圆圈表示将会偿还贷款的人,浅蓝色的圆圈表示将会拖欠贷款的人。
通过定义一个阈值,就可以根据信用评分进行决策。例如,向信用评分超过阈值的人发放贷款,而拒绝向信用评分低于阈值的人发放贷款。这种决策规则被称为阈值策略。
信用评分可以被解释为对拖欠贷款行为的估计概率。例如,信用评分为650的人中估计有90%的人可能会偿还他们的贷款。
银行就可以给信用评分为650的个人发放相同的贷款,并获得预期的利润。同样,银行可以给所有信用评分高于650的个人发放贷款,并预测他们的利润。
贷款阈值和盈亏结果
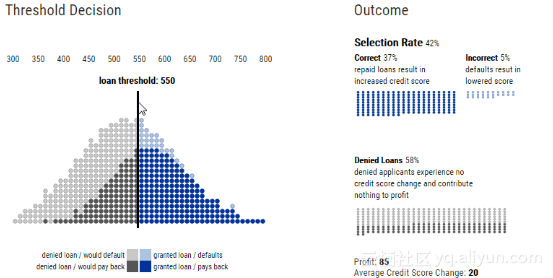
不考虑其他因素,银行肯定会最大化自己的总利润。利润取决于银行从偿还贷款中获得的金额与从拖欠贷款中损失的金额之比。在上面的动图中,营收与亏损的比率的取值是-4~1。
当损失的成本相对高于收益成本时,银行会更保守地发放贷款,并提高贷款阈值。我们称信用评分超过该阈值的人群比例为选择率(selection rate)。
信用评分变化曲线
是否发放贷款的决策不仅影响机构,而且影响个人。违约事件(借款人未能偿还贷款)不仅会让银行损失利润,也降低了借款人的信用评分。
按时偿还贷款的行为会为银行带来利润,同时也会增加借款人的信用评分。在本文的示例中,借款人信贷评分变化率为-2~1,-2表示拖欠贷款,1表示偿还贷款。
对于阈值策略,评分结果(outcome)的定义是人群信用评分的预期变化,也是选择率函数的一个参数,我们称这个函数为结果曲线。每组人群的选择率不同,信用评分曲线也不尽相同。
人群的平均信用评分变化结果既取决于还款的概率,也取决于个人贷款决策的成本和收益。
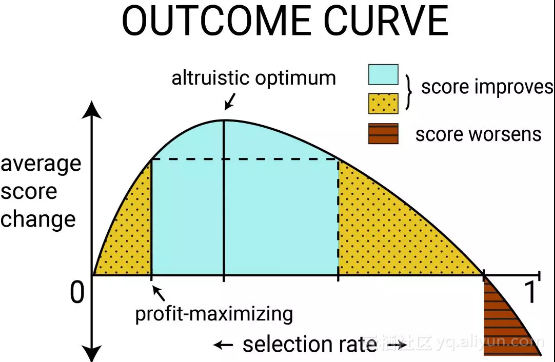
上图显示了典型人群的评分结果曲线。当一组群体中有足够人员获得贷款并成功偿还贷款时,该组的平均信用评分可能会增加。
在这种情况下,银行的利润还未达到最大值时,利润与人群平均信用评分正相关。
当我们以利润最大化为目标而向更多人发放贷款,平均信用评分增加到最大值。我们可以称之为最佳互利点( altruistic optimum)。
为了继续增加利润,银行还可以继续发放贷款,但此时人群的平均信用评分将越过最大值开始下降,如上图黄色虚线区域所示。
但选择率在黄色虚线区域时,将对个人的信用评分造成相对损害。比如,如果有大多数人无法偿还贷款,那么该组人群的平均信用评分将下降,这与红色区域的情况一样。
贷款阈值与评分结果曲线
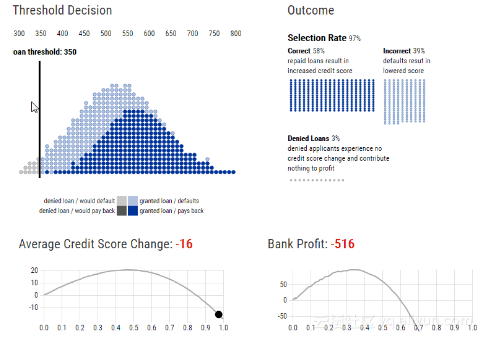
给定的阈值策略如何影响不同群体中的个人?不同人群的信用评分有不同的分布结果。
假设第二组人群的信用评分的分布与第一组不同,并且人数也较少。我们可以认为这个群体是一个历史上处于弱势地位的少数群体。
我们用蓝色部分表示这个群体,并希望确保银行的贷款政策不会过度伤害他们的权益。
我们假定银行为每个群体选择了不同的阈值。尽管根据群体确定阈值可能面临法律挑战,但为了说明固定的阈值策略对不同群体的差异结果,我们不妨先根据群体来确定信用评分的阈值。
不同群体的贷款决策
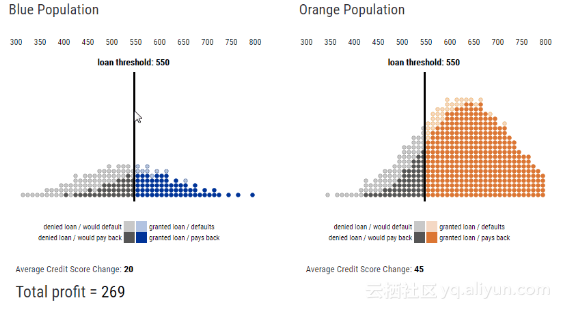
从上面的动图中可以看出,有必要对蓝色小组内人群的信用评分阈值的选择进行改进。
正如上文所述,银行的放贷政策始终以利润最大化作为约束条件,因此银行总会选择达到盈亏平衡点的阈值策略,当个人的信用评分超过该阈值就可以发放贷款。
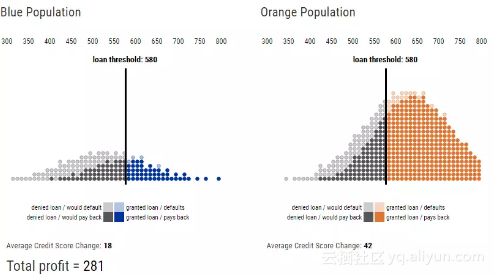
事实上,通过改变阈值发现,当银行的利润达到最大值时(Total profit = 281),两个群体的放贷阈值(loan threshold:580)是相同的,但是选择率却不同,同一阈值策略下,蓝色小组获得贷款的人数更少,如下图所示。
公平标准
不同群体的信用评分的分布不同,将获得不同形状的结果曲线(参见下图中上半部分,显示了由实际信用评分数据和简单结果模型得出的结果曲线)。
为了改进利润最大化作为约束条件的缺点,可以考虑公平约束条件,在一些目标函数下,这种约束条件可以使团体之间的决策相等。本文提出了各种公平标准来保护弱势群体。通过结果模型,我们获得了公平约束条件与评分结果曲线之间的关系。
常见的一个公平标准,人数均等,要求银行以同样的比例向两个群体发放贷款,同时银行也可以继续实现利润最大化。另一个标准,即机会均等,两个群体之间可以偿还贷款的人,银行要提供相同的放贷比率。
模拟约束条件下的贷款决策
尽管这些公平标准是考虑均衡的一种静态决策方式,但这种方式忽略这些政策对人群未来的影响。
下图对比了最大利润,人数均等和机会均等条件下的政策。动图中展示了不同的贷款策略下对应的银行利润和信用评分变化。与最大利润相比,人数均等和机会均等都会降低银行的利润。
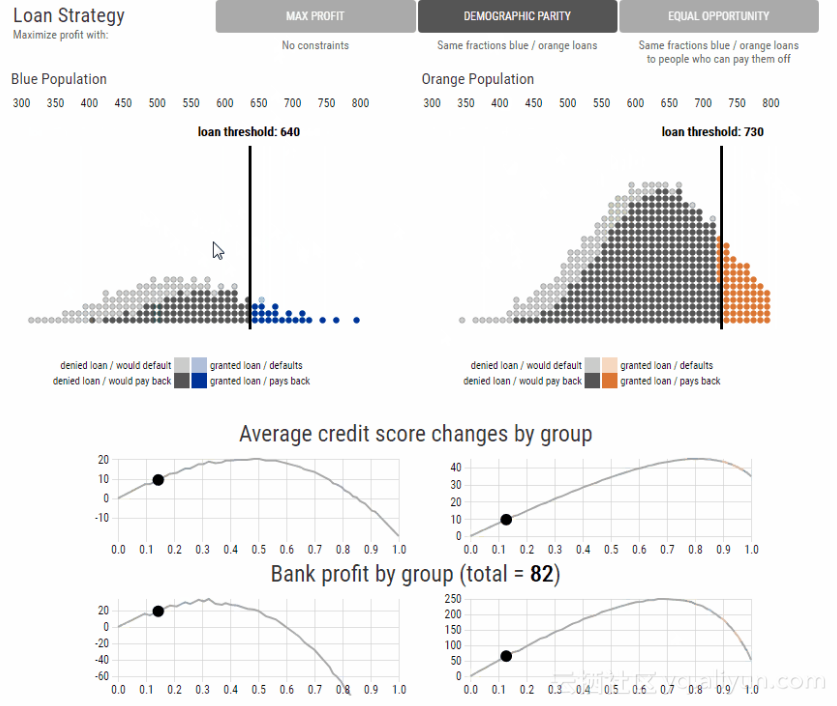
但是,人数均等和机会均等在利润最大的条件下,是否改善了蓝色人群的评分结果曲线?在利润最大化的放贷策略中,蓝色人群的平均信用评分在最佳互利点之前;在机会均等的放贷策略中,蓝色人群的平均信用评分在最佳互利点之后;在人数均等的放贷策略中,蓝色人群的平均信用评分落在了会降低评分的黄色区域。
如果采用公平标准的目标是增加或平衡所有人群的长期福祉,上述结果表明,有些情况下公平标准实际上违背了这一目标。
换句话说,公平约束条件也会减少弱势群体的福利。构建一个准确的模型来预测决策对人群结果的影响,有助于缓解公平约束条件带来的意外结果。
“公平”机器学习的结果
当提到“公平”机器学习时,我们旨在获得长期的研究结果。如果忽略延迟结果对模型的细微影响,我们就无法预测公平标准作为分类系统的约束条件而产生的影响。结果曲线为我们提供了一种以最直接的方式改善利润最大化标准的缺点。
结果模型是将某个领域的知识进行分类的具体方法。这与许多学者指出机器学习中公平性的语境感知的本质一致。结果曲线提供了一个可解释的视觉效果,解决了交易领域内应用程序的公平性问题。
原文发布时间为:2018-05-23
本文作者:文摘菌















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









