






教材习题 Page7
1-1 数据压缩的一个基本问题是“我们要压缩什么”,对此你是怎样理解的?
我的答案:数据压缩,顾名思义就是对数据进行压缩,例如文字、图片、声音、动画等等。数据压缩通常有时间域、空间域、频率域和能量域几个方面,所以也可以说数据压缩是对时间、空间、频率以及能量的压缩。
1-2 数据压缩的另一个基本问题是“为什么要进行压缩”,对此你又是怎样理解的?
我的答案:一切事物都可以用数据表示,但往往需要大量的数据空间。而数据压缩以缩减数据量以减少存储空间,提高其传输、存储和处理效率,对数据进行重新组织,减少数据的冗余。这就是我们为了什么
1-6 数据压缩技术是如何分类的?
我的答案:数据压缩根据重构需求,分为有损压缩和无损压缩;根据可逆性又可以分为可逆压缩和不可逆压缩。有损压缩是存在失真的,压缩后不能回归原本,所以也叫不可逆压缩;无损压缩是不存在失真的,压缩后可以解压缩回归本真,所以又叫可逆压缩。
参考书《数据压缩导论(第4版)》Page 8
1.4 项目与习题
1. 用你的计算机上的压缩工具来压缩不同文件。研究原文件的大小和类型对于压缩文件与原文件大小之比的影响。
我的答案:通过多次实验发现,压缩软件对文件进行压缩后,存储所占用的空间比原文件要小,更适合传输,节约空间与时间。不同的压缩工具压缩的程度是不一样的,但差别不是很大。而且原文件的大小和类型对其均有影响。一般文本文档的压缩程度比图片数据的压缩要 小,而音频、视频等的压缩程度比较大,并且同类型不同大小的数据的压缩也有变化,一般越大的数据压缩程度越大。最重要的一点是,这些压缩工具对数据的压缩都是无损压缩,被压缩后的数据可以通过解压工具使其还原。
2. 从一本通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,实现压缩。例如,在"this is the dog that belong to my friend” 中,删除 is 、the、that和to之后,仍然能传递相同的意思。用被删除的单词数与原文本的总单词数之比来衡量文本中的冗余度。用一本技术期刊中的文字来重复这一实验。对于摘自不同来源的文字,我们能否就其冗余度做出定量论述?
我的答案:压缩文字就像语文课本中讲的缩短句子(一般都是找出句子的主谓宾),类似,压缩原理也大同小异。例如莎士比亚语录:Discard time, and the time has abandoned up to him.(抛弃时间的人, 时间也抛弃他。)这段话有10个单词,包含40个字母、9个空格、2个标点符号。如果每个字母、空格或 标点都占用1个内存单元,那么文件的总大小为51个单元。为了减小文件的大小,我们需要找出冗余的部分。我们立刻
发现:如果忽略大小写字母间的区别,这个句子冗余度是非常大的。四个单词(Discard 、time、abandoned、him)几乎提供了组成整句话所需的所有东西,然后加上空格和标点就行了。这样一来,文件就大大缩小了。经过多次试验,结果都大同小异,不同的文字段落都存在冗余,或大或小,经过对字段的压缩,均可以减少存储空间。就数据的冗余度来说,数据的重复存贮称为数据冗余,会造成存贮空间的浪费。
参考书《数据压缩导论(第4版)》Page 30
3、给定符号集A={a1,a2,a3,a4},求一下条件下的一阶熵:
(a)P(a1)=P(a2)=P(a3)=P(a4)=1/4
(b)P(a1)=1/2 , P(a2)=1/4 , P(a3)=P(a4)=1/8
(c)P(a1)=0.505 , P(a2)=1/4 , P(a3)=1/4 , P(a4)=0.12
我的答案:
(a)该条件下信源的概率模型为
P={P(a1),P(a2),P(a3),P(a4)}= {1/4, 1/4, 1/4, 1/4}
则信源的一阶熵为
H= P(a1)㏒2P(a1)+P(a2)㏒2P(a2)+P(a3)㏒2P(a3)+P(a4)㏒2P(a4)
= -1/4㏒2 (1/4)-1/4㏒2 (1/4)-1/4㏒2 (1/4)-1/4㏒2 (1/4)
= -1/4㏒2 (1/4)×4
= 2 (bits)
(b)该条件下信源的概率模型为
P={P(a1),P(a2),P(a3),P(a4)}= {1/2, 1/4, 1/8, 1/8}
则信源的一阶熵为
H= P(a1)㏒2P(a1)+P(a2)㏒2P(a2)+P(a3)㏒2P(a3)+P(a4)㏒2P(a4)
= -1/2㏒2 (1/2)-1/4㏒2 (1/4)-1/8㏒2 (1/8)-1/8㏒2 (1/8)
= 1/2+1/2+3/8+3/8
= 7/4=1.75(bits)
(c)该条件下信源的概率模型为
P={P(a1),P(a2),P(a3),P(a4)}= {0.505, 1/4, 1/4, 0.12}
则信源的一阶熵为
H= P(a1)㏒2P(a1)+P(a2)㏒2P(a2)+P(a3)㏒2P(a3)+P(a4)㏒2P(a4)
= -0.505㏒2 0.505-1/4㏒2 (1/4)-1/4㏒2 (1/4)-0.12㏒2 0.12
= -0.505㏒2 0.505+1/2+1/2-0.12㏒2 0.12
≈ 1.26(bits)
5、考虑以下序列:
ATGCTTAACGTGCTTAACCTGAAGCTTCCGCTGAAGAACCTG
CTGAACCCGCTTAAGCTTAAGCTGAACCTTCTGAACCTGCTT
(a)根据此序列估计个概率值,并计算这一序列的一阶、二阶、三阶和四阶熵。
(b)根据这些熵,能否推断此序列具有什么样的结构?
我的答案:
分析:序列的字母总数为84个,A出现21次、C出现24次、G出现16次、T出现23次
(a)P(A)=21/84=1/4 、P(C)=24/84=2/7 、P(G)=16/84=4/21 、P(T)=23/84
该条件下信源的概率模型为
P={P(A),P(C),P(G),P(T)}= {1/4, 2/7, 4/21, 23/84}
则信源的一阶熵为
H= -1/4㏒2 (1/4)-2/7㏒2 (2/7)-4/21㏒2 (4/21)-23/84㏒2 (23/84)
≈ 1/2+0.154+0.137+0.154
≈ 0.945(bits)
(b)
7、做一个实验,看看一个模型能够多么准确地描述一个信源。
(a)编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
我的答案:
程序源代码:
#include<iostream>
using namespace std;
#include<cstdlib>
#include<ctime>
#include<iomanip>
int main()
{
int w,m,n;
char Word[100][100];
srand(time(NULL));
for(m=0;m<100;m++)
{
for(n=0;n<4;n++)
{
w=rand()%26;
Word[m][n]=w+'a';
}
Word[m][4]='\0';
cout<<m+1<<"\t"<<Word[m]<<"\t";
}
cout<<"\n";
return 0;
}
运行结果截图:
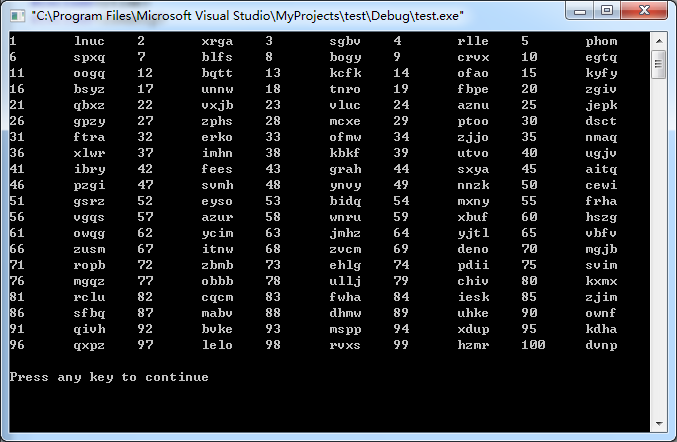
根据运行结果分析有:
基本事件个数:100个; 满足条件(即单词有意义)的有:3个。














 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









