







Knowledge Base Completion by Learning to Rank Model
基于模型排序学习的知识库推理
摘要
1. 知识库推理(Knowledge Base Completion)就是从KB中已有的事实预测新的事实;
2. 目前的方法是PRA(Path Ranking Algorithm),基于连接实体的路径类型预测事实,并将预测当做分类问题(使用逻辑回归);
3. 本文的方法是将关系预测视作一个排序问题,并基于YAGO进行试验,最终成绩优于各种分类模型。
介绍
尽管知识库在不断壮大,但是知识库仍然不完整,缺失大量的事实,知识库推理就是通过已有事实来预测未知的事实从而来填补缺失的事实。
符号方法使用规则或者关系路径来推理新的知识,比如PRA算法;嵌入方法将推理问题看做一个矩阵完备(matrix completion)问题,学习KB中的实体和关系在低维空间的表示形式;当然也有人试着将两个方法结合在一起,比如基于路径的TransE(Modeling relation paths for representation learning of knowledge bases, Lin, EMNLP2015)。
本文主要研究PRA算法和它的扩展。
PRA算法
PRA使用随机行走(random walk)来遍历有限长度的连接着实体对的路径,实体对之间包含多关系实例。根据给定关系预测新关系实例的分类器将使用这些路径作为特征。在PRA中,每个关系路径都可被看做一个逻辑规则,因为PRA实际上是一种有区别性训练的逻辑推理。
PRA抽取关系路径来建立LR(Logistic Regression)分类模型,它基于LCWA(local close world assumption)来生成负实体对。然而,真实的KB中有太多的负实体对,以致于正负实体对非常不均衡。另外,知识库推理使用候选实体对来填充缺失的事实,对这些候选进行排序比给他们分类或者评分要更合理。
模型排序学习
对模型的排序学习包含两步:(1)生成特征矩阵;(2)为每个关系推理出新的事实
1. 特征计算
给定一个关系![]() ,集合
,集合![]() 收集所有拥有关系
收集所有拥有关系![]() 的实体对,即
的实体对,即
![]()
然后根据Local Close World Assumption来生成负实体对。
对于每个实体对![]() ,通过随机行走遍历出所有将
,通过随机行走遍历出所有将![]() 和
和![]() 连接起来的有限长度的路径,这些关系路径类型的集合为
连接起来的有限长度的路径,这些关系路径类型的集合为
![]()
这些路径类型都将被当做关系特征来为新的实体对做预测。
我们将这些路径类型二值化,进而为每个实体对计算特征向量。
2. 实体对排序
采用不同的排序方法来建立成对目标函数(pairwise objective function)。定义
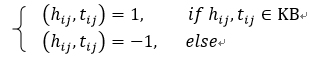
采用梯度提升树(gradient boosting tree)或者lambdaMART作为排序的方法,该方法将正负实体对作为一个偏序。不用最小化逻辑回归的对数损失函数,我们使用梯度提升学习实体对排序来直接优化MAP。LambdaMART的输出定义为:
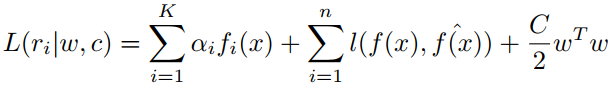
公式的第一部分中,每一个![]() 是由单个树建模的函数,
是由单个树建模的函数,![]() 是第i个树的学习权重,K是树的数量;
是第i个树的学习权重,K是树的数量;
公式的第二个部分是结对损失,度量了预测值和实际值之间的距离;
公式的第三部分是正则化,在叶子值上添加L2惩罚来避免过拟合,C是常量,随机梯度提升被用来提高一个基树每轮迭代的准确率。















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









