







在数据挖掘的过程中,数据预处理占到了整个过程的60%
脏数据:指一般不符合要求,以及不能直接进行相应分析的数据
脏数据包括:缺失值、异常值、不一致的值、重复数据及含有特殊符号(如#、¥、*)的数据
数据清洗:删除原始数据集中的无关数据、重复数据、平滑噪声数据、处理缺失值、异常值等
缺失值处理:删除记录、数据插补和不处理


主要用到VIM和mice包
install.packages(c("VIM","mice"))
1.处理缺失值的步骤
步骤:
(1)识别缺失数据;
(2)检查导致数据缺失的原因;
(3)删除包含缺失值的实例或用合理的数值代替(插补)缺失值
缺失值数据的分类:
(1)完全随机缺失:若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失(MCAR)。
(2)随机缺失:若某变量上的缺失数据与其他观测变量相关,与它自己的未观测值不相关,则数据为随机缺失(MAR)。
(3)非随机缺失:若缺失数据不属于MCAR或MAR,则数据为非随机缺失(NIMAR)。
2.识别缺失值
NA:代表缺失值;
NaN:代表不可能的值;
Inf:代表正无穷;
-Inf:代表负无穷。
is.na():识别缺失值;
is.nan():识别不可能值;
is.infinite():无穷值。
is.na()、is.nan()和is.infinte()函数的返回值示例
| x |
is.na(x) |
is.nan(x) |
is.infinite(x) |
| x<-NA |
TRUE |
FALSE |
FALSE |
| x<-0/0 |
TRUE |
TRUE |
FALSE |
| x<-1/0 |
FALSE |
FALSE |
TRUE |
|
|
|
|
|
complete.cases()可用来识别矩阵或数据框中没有缺失值的行,若每行都包含完整的实例,则返回TRUE的逻辑向量,若每行有一个或多个缺失值,则返回FALSE;
3.探索缺失值模式
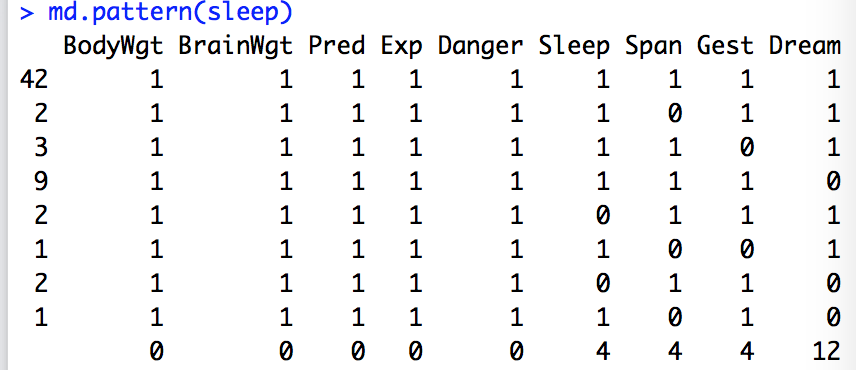
(1)列表显示缺失值
mice包中的md.pattern()函数可以生成一个以矩阵或数据框形式展示缺失值模式的表格
library(mice)
data(sleep,package="VIM")
md.pattern(sleep)
(2)图形探究缺失数据
VIM包中提供大量能可视化数据集中缺失值模式的函数:aggr()、matrixplot()、scattMiss()
library("VIM")
aggr(sleep,prop=TRUE,numbers=TRUE)#用比例代替了计数
matrixplot()函数可生成展示每个实例数据的图形
matrixplot(sleep)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









