







今天,我们介绍的机器学习算法叫xgboost。
不要被这个名字吓唬到,其实它的基本原理并不复杂。要理解xgboost,需要首先理解决策树。还没有接触过决策树的同学可以看一下《人工智能算法通俗讲解系列(三):决策树 》这块内容。
假如我们现在有下面两棵决策树,左侧是tree1,右侧tree2。这些树都是用来判断用户是否喜欢玩游戏的。跟我们之前的案例是类似的。
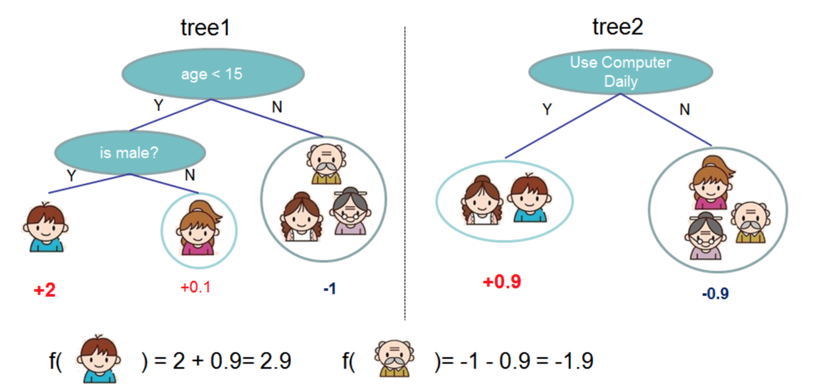
先看右侧这个简单的树。椭圆是用户特征:是否每天用电脑。左边是“是”,右边是“否”。通过数据,他们发现,每天玩电脑的人里面,玩游戏的人占比高。不怎么玩电脑的人里面,玩游戏的占比低。我们给占比高的这一边设置一个大一点的权重,比如0.9,占比低的一边设置低一点的权重。不用管0.9的计算细节,只要知道占比(概率)高权重大就OK。
假设我们只有右侧这一棵树。当来一个新用户时,我们就可以用它来判断它玩游戏的偏好。比如某个新用户每天玩电脑,我们就直接判断“他喜欢玩游戏”。这虽然不会特别准确,但也比瞎蒙要更好一些。
不过我们还要追求更好。因为我们不止有一棵树,还有另一棵决策树可以使用。
现在,让我们看一下左边这棵决策树。它的第一个判断条件是:“年龄是否小于15”。 从已有的数据发现,“否”的这一侧,也就是15岁以上的人里,玩游戏的人占比比较低,于是设置低权重,比如设置为-1。15岁以下的人群里,再分男女。发现男性用户玩游戏的比例明显高于女性。于是,给男性设置高一些的权重,比如2,女性低一点,比如0.1。不过这里的女性权重,要比15岁以上的那个分支权重大一些。
然后,当一个新的数据过来的时候,我们组合两个树,进行综合判断。比如一个新用户年龄小于15,男性,每天玩电脑。 预测他是否喜欢玩游戏的方法就是:找到他在每一颗树中的权重,然后相加。他在第一棵树中的位置为左下角的叶子,权重为2;同时,他在第二棵树的位置也是左下角的叶子,权重为0.9。然后,我们把他在两棵树中的权重相加,得出最终权重,即2.9。
这样,就等于把三个特征:年龄、性别、和玩电脑时长总和考虑进来了,这种判断比单棵决策树更准确。
同样方法,一个年龄大于15,且不怎么玩电脑的人,组合计算后,得分很低。年龄因素减了1分,不玩电脑又减了0.9,所以得分特别低,最终为-1.9。于是,我们就预测他不大可能喜欢游戏。
实际使用时,特征库里面可能不止三个特征,而是几十个或者上百个特征。那怎么办呢?
比如我们有100个特征,同时有100万条数据。我们可以随机选10个特征、随机选10万条数据,生成一颗树。然后,再随机选10个特征,随机选10万条数据,生成第二棵树。同样的方法生成第三棵树,第四棵树...
最后我们可以生成几十个树,比如生成了50个。具体几棵我们自己定。这些树就组成了一个森林。因为是随机生成的,所以叫随机森林。
当我们对一个新用户做判断对时候,就把这个用户往每一棵树上套,这样就得出50个权重。然后把这50个权重相加,得出最终的权重。比较不同的用户的最终权重,就能判断他们所属的分类。
把森林中的所有树组合起来形成的策略,综合了所有特征以及多种组合情况的逻辑。用这个策略判断每一个新数据,准确率会大大提高。所以,xgboost在很多大赛中的表现都很好。















 6445
6445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









