







 常见群落相似性或距离测度的计算
常见群落相似性或距离测度的计算

前篇已经初步讲述了关于群落多样性分析中的Beta多样性基本概念,并提到常见的Beta多样性分析方法一般建立在群落相似性/或距离测度的基础上,以及初步介绍了有关群落相似性/或距离测度的基础。
相似性或距离的衡量标准有很多种,Legendre和Legendre(1998)列出大约30种方法,并对生态相似性作了更详细的介绍,有兴趣可自行参阅Legendre和Legendre(1998)“Numerical Ecology”第七章“Ecological resemblance”的内容。
接下来的篇幅,白鱼小编选择了其中几种常见的相似性或距离测度为大家作简介。前半部分介绍公式,后半部分展示在R语言中的计算方法。
常见的相似性或距离简介
定性(二元)对称相似性指数
这种类型的相似性指数不适用于群落数据分析,忽略。
定量对称相似性指数
同样地,这种类型的相似性指数也不适用于群落数据分析,忽略。
定性(二元)非对称相似性指数
Jaccard相似性/相异度
Jaccard相似性指数(Jaccard similarity index)将两个样方共享的物种数量(a)除以两个样方中出现的所有物种的总和(a + b + c,其中b和c是仅在第一个和第二个样方中出现的物种数量)。计算公式如下:

转换为Jaccard相异度(Jaccard dissimilarity):
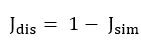
注:如前篇中所提到的,相似性指数(S)和距离测度(D)常见3种转化公式:
D = 1-S,或D = (1-S)1/2,或D = (1-S2)1/2;
其中“D=1-S”更为常见;对于“D = (1-S)1/2,或D = (1-S2)1/2”类型,这种转化的目的使某些距离指数具有欧式几何特征,欧式属性的距离在某些分析中将会非常有用。这个将来我会在一些更具体的方法中提到。
本篇中所展示的相互转换,默认以“D = 1-S”为例,下同。
Sørensen相似性/相异度
与Jaccard指数相比,Sørensen相似性指数(Sørensen similarity index)认为两个样方之间共享的物种数量更重要,因此它计算两次。计算公式如下:

转换为Sørensen相异度(Sørensen dissimilarity):

Simpson相似性/相异度
在两个样方的物种丰富度指数差异很大的情况下(即一个样方比另一个样方具有更多的物种),Simpson相似性指数(Simpson similarity index)更为适用。在这种情形下,如果使用Jaccard或Sørensen相似性指数,它们的值通常非常低,因为会出现分母过大的情况(具有很多的非共享物种,特别是高物种丰富度的样方所贡献)导致指数的总值过低。Simpson相似性指数通过从分数b和c中仅取较小的数据来消除这个问题。计算公式如下:
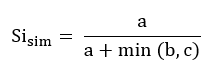
转换为Simpson相异度(Simpson dissimilarity):
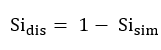
注意:这里的Simpson相似性指数(或Simpson相异度),不同于Alpha多样性指数中的Simpson指数。
定量非对称相似性指数
例如相似百分率(Percentage similarity),由“1 - 相异百分率”获得(即直接通过“S = 1-D”等转化),相异百分率又称Bray-curtis距离,详见下文“Bray-curtis距离”。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









