







最近我们要对站点的指定 url 测试其页面请求完整性,并分析每个请求参数是否正常。如果不使用自动化测试工具,你也可以人肉点击、查看每个页面是否有请求遗漏和每个请求参数是否正常。当然也有如 Fiddler 之类的抓包工具,但这个工具貌似没开源代码,也没有提供接口供第三方调用和扩展。找来找去发现 Selenium 可以满足当前的业务需求。
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7、8、9)、Mozilla Firefox、Mozilla Suite等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建衰退测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具。
1、Selenium 抓取请求的原理
其实 Selenium 抓取请求的原理、架构和 fiddler 之类的工具是类似的:
(关于 Fiddler 请参考:http://my.oschina.net/leejun2005/blog/151103)
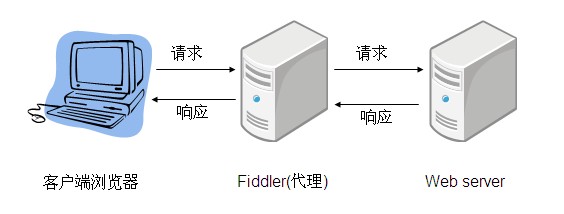
只是这里 Selenium 代理取代了 Fiddler 代理,而自动化测试脚本则通过 Selenium 去操纵浏览器或者其里面的页面元素去模拟人的行为,进而完成预设的测试任务。
2、Selenium 自动化测试实例:获取指定 url 的所有请求并简单统计分析
废话就不说了,直接上代码了。需要提示下的是,如果你想测试下面的代码,请按如下步骤来:
(1)Install Python
(2)Install Java
(3)Install Selenium bindings for Python
(4)Run Selenium server: 'java -jar selenium-server.jar'
(5)Run web_profiler.py
# -*- coding: utf-8 -*-
#!/usr/bin/env python
#
# Selenium Web/HTTP Profiler
# Copyright (c) 2009-2011 Corey Goldberg (corey@goldb.org)
# License: GNU GPLv3
# run:
# python web_profiler.py http://baidu.com/
import json
import socket
import sys
import time
import urlparse
import xml.etree.ElementTree as etree
from datetime import datetime
from selenium import selenium
def main():
if len(sys.argv) < 2:
print 'usage:'
print ' %s <url> [browser_launcher]' % __file__
print 'examples:'
print ' $ python %s www.google.com' % __file__
print ' $ python %s http://www.google.com/ *firefox\n' % __file__
sys.exit(1)
else:
url = sys.argv[1]
if not url.startswith('http'):
url = 'http://' + url
parsed_url = urlparse.urlparse(url)
site = parsed_url.scheme + '://' + parsed_url.netloc
path = parsed_url.path
if path == '':
path = '/'
browser = '*firefox'
if len(sys.argv) == 3:
browser = sys.argv[2]
run(site, path, browser)
def run(site, path, browser):
sel = selenium('127.0.0.1', 4444, browser, site)
try:
sel.start('captureNetworkTraffic=true')
except socket.error:
print 'ERROR - can not start the selenium-rc driver. is your selenium server running?'
sys.exit(1)
sel.open(path)
sel.wait_for_page_to_load(90000)
end_loading = datetime.now()
raw_xml = sel.captureNetworkTraffic('xml')
sel.stop()
traffic_xml = raw_xml.replace('&', '&').replace('=""GET""', '="GET"').replace('=""POST""', '="POST"') # workaround selenium bugs
nc = NetworkCapture(traffic_xml)
#json_results = nc.get_json()
num_requests = nc.get_num_requests()
total_size = nc.get_content_size()
status_map = nc.get_http_status_codes()
file_extension_map = nc.get_file_extension_stats()
http_details = nc.get_http_details()
start_first_request, end_first_request, end_last_request = nc.get_network_times()
end_load_elapsed = get_elapsed_secs(start_first_request, end_loading)
end_last_request_elapsed = get_elapsed_secs(start_first_request, end_last_request)
end_first_request_elapsed = get_elapsed_secs(start_first_request, end_first_request)
print '--------------------------------'
print 'results for %s' % site
print '\ncontent size: %s kb' % total_size
print '\nhttp requests: %s' % num_requests
for k,v in sorted(status_map.items()):
print 'status %s: %s' % (k, v)
print '\nprofiler timing:'
print '%.3f secs (page load)' % end_load_elapsed
print '%.3f secs (network: end last request)' % end_last_request_elapsed
print '%.3f secs (network: end first request)' % end_first_request_elapsed
print '\nfile extensions: (count, size)'
for k,v in sorted(file_extension_map.items()):
print '%s: %i, %.3f kb' % (k, v[0], v[1])
print '\nhttp timing detail: (status, method, doc, size, time)'
for details in http_details:
print '%i, %s, %s, %i, %i ms' % (details[0], details[1], details[2], details[3], details[4])
def get_elapsed_secs(dt_start, dt_end):
return float('%.3f' % ((dt_end - dt_start).seconds +
((dt_end - dt_start).microseconds / 1000000.0)))
class NetworkCapture(object):
def __init__(self, xml_blob):
self.xml_blob = xml_blob
self.dom = etree.ElementTree(etree.fromstring(xml_blob))
def get_json(self):
results = []
for child in self.dom.getiterator():
if child.tag == 'entry':
url = child.attrib.get('url')
start_time = child.attrib.get('start')
time_in_millis = child.attrib.get('timeInMillis')
results.append((url, start_time, time_in_millis))
return json.dumps(results)
def get_content_size(self): # total kb passed through the proxy
byte_sizes = []
for child in self.dom.getiterator():
if child.tag == 'entry':
byte_sizes.append(child.attrib.get('bytes'))
total_size = sum([int(bytes) for bytes in byte_sizes]) / 1000.0
return total_size
def get_num_requests(self):
num_requests = 0
for child in self.dom.getiterator():
if child.tag == 'entry':
num_requests += 1
return num_requests
def get_http_status_codes(self):
status_map = {}
for child in self.dom.getiterator():
if child.tag == 'entry':
try:
status_map[child.attrib.get('statusCode')] += 1
except KeyError:
status_map[child.attrib.get('statusCode')] = 1
return status_map
def get_http_details(self):
http_details = []
for child in self.dom.getiterator():
if child.tag == 'entry':
url = child.attrib.get('url') + '?'
# url = child.attrib.get('url')
print "---->> " + url
url_stem = url.split('?')[0]
doc = '/' + url_stem.split('/')[-1]
status = int(child.attrib.get('statusCode'))
method = child.attrib.get('method').replace("'", '')
size = int(child.attrib.get('bytes'))
time = int(child.attrib.get('timeInMillis'))
http_details.append((status, method, doc, size, time))
http_details.sort(cmp=lambda x,y: cmp(x[3], y[3])) # sort by size
return http_details
def get_file_extension_stats(self):
file_extension_map = {} # k=extension v=(count,size)
for child in self.dom.getiterator():
if child.tag == 'entry':
size = float(child.attrib.get('bytes')) / 1000.0
url = child.attrib.get('url') + '?'
url_stem = url.split('?')[0]
doc = url_stem.split('/')[-1]
if '.' in doc:
file_extension = doc.split('.')[-1]
else:
file_extension = 'unknown'
try:
file_extension_map[file_extension][0] += 1
file_extension_map[file_extension][1] += size
except KeyError:
file_extension_map[file_extension] = [1, size]
return file_extension_map
def get_network_times(self):
timings = []
start_times = []
end_times = []
for child in self.dom.getiterator():
if child.tag == 'entry':
timings.append(child.attrib.get('timeInMillis'))
start_times.append(child.attrib.get('start'))
end_times.append(child.attrib.get('end'))
start_times.sort()
end_times.sort()
start_first_request = self.convert_time(start_times[0])
end_first_request = self.convert_time(end_times[0])
end_last_request = self.convert_time(end_times[-1])
return (start_first_request, end_first_request, end_last_request)
def convert_time(self, date_string):
if '-' in date_string: split_char = '-'
else: split_char = '+'
# dt = datetime.strptime(''.join(date_string.split(split_char)[:-1]), '%Y%m%dT%H:%M:%S.%f')
dt = datetime.strptime(''.join(date_string.split(split_char)[:-1]), '%Y%m')
return dt
if __name__ == '__main__':
main()最后的结果输出了所有的请求,并 对这次的请求进行简单的分析, 包括异步加载的 ajax、图片啥的,和你在浏览器 F12→network 看到的效果类似。

3、Refer:
[1] http://docs.seleniumhq.org/
[2] Selenium私房菜系列--总章
http://www.cnblogs.com/hyddd/archive/2009/05/30/1492536.html
[3] 解析js的库和浏览器内核 http://segmentfault.com/q/1010000000533061
QtWebKit,已知有 Python 和 C++ 支持
PhantomJS,已知有 JavaScript、CoffeeScript 和 Python 支持,也是 Webkit 内核
SlimerJS,已知有 JavaScript 支持,Gecko 内核,和火狐是一样的,也可以运行于火狐之上
CasperJS,已知有 JavaScript 支持。上边两个的进一步封装
[4] Selenium Test 自动化测试 入门级学习笔记
http://www.cnblogs.com/Javame/p/3848258.html
[5] selenium 中文文档
https://github.com/fool2fish/selenium-doc
[6] 技术贴:使用UserScript自动通过百度网盘/360云盘提取码
http://blog.fishlee.net/2016/03/09/using-contentscripts-to-pass-access-code/















 6152
6152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









