







 本文详细介绍了Pandas DataFrame的基础知识,包括如何创建DataFrame、理解DataFrame的轴概念,以及数据选择、修改、重索引、算术运算等核心操作。通过字典、列表和文件读取等方式创建DataFrame,并展示了使用loc和iloc进行数据索引和修改,以及处理缺失数据的方法。
本文详细介绍了Pandas DataFrame的基础知识,包括如何创建DataFrame、理解DataFrame的轴概念,以及数据选择、修改、重索引、算术运算等核心操作。通过字典、列表和文件读取等方式创建DataFrame,并展示了使用loc和iloc进行数据索引和修改,以及处理缺失数据的方法。
熊猫数据框架可以从列表、字典和字典列表等中创建。通过从现有存储中加载数据集来创建PandasDataFrame,存储可以是SQL数据库、CSV文件和Excel文件。

Dataframe是一种二维数据结构,即数据以表格方式排列成行和列。在按行和列排列的dataframe数据集中,我们可以将任意数量的数据集存储在一个dataframe中。
我们可以对这些数据集执行许多操作,如算术操作、列/行选择、列/行加法等。
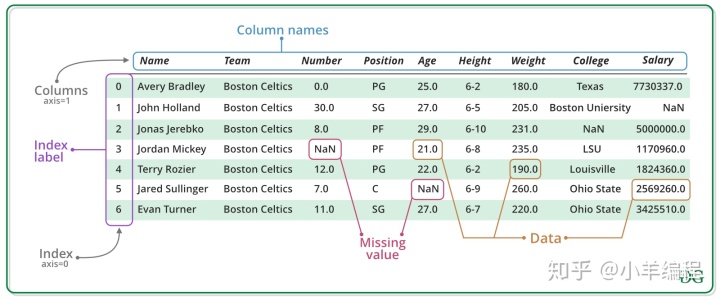
熊猫数据框架可以通过多种方式创建。让我们逐一讨论创建DataFrame的不同方法。
1、DataFrame的创建
DataFrame是一种表格型数据结构,它含有一组有序的列,每列可以是不同的值。
创建一个空的dataframe:
可以创建的基本DataFrame是一个空的Dataframe。一个空的Dataframe是通过调用dataframe构造函数来创建的。
# import pandas as pd
import pandas as pd
# Calling DataFrame constructor
df = pd.DataFrame()
print(df)产出:
Empty DataFrame
Columns: []
Index: []
DataFrame的创建有多种方式,不过最重要的还是根据dict进行创建,以及读取csv或者txt文件来创建。
根据字典创建
data = {
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
frame = pd.DataFrame(data)
frame
#输出
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002DataFrame的行索引是index,列索引是columns,我们可以在创建DataFrame时指定索引的值:
frame2 = pd.DataFrame(data,index=['one','two','three','four','five'],columns=['year','state','pop','debt'])
frame2
#输出
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN使用嵌套字典也可以创建DataFrame,此时外层字典的键作为列,内层键则作为索引:
pop = {'Nevada':{2001:2.4,2002:2.9},'Ohio':{2000:1.5,2001:1.7,2002:3.6}}
frame3 = pd.DataFrame(pop)
frame3
#输出
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6我们可以用index,columns,values来访问DataFrame的行索引,列索引以及数据值,数据值返回的是一个二维的ndarray
frame2.values读取文件
读取文件生成DataFrame最常用的是read_csv,read_table方法。
该方法中几个重要的参数如下所示:
参数描述header默认第一行为columns,如果指定header=None,则表明没有索引行,第一行就是数据index_col默认作为索引的为第一列,可以设为index_col为-1,表明没有索引列nrows表明读取的行数sep或delimiter分隔符,read_csv默认是逗号&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1256
1256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









