







一.什么是集体智慧
概念:集体智慧(Collective Intelligence,CI),简称集智,它是一种共享的或群体的智能。在网络时代来临之前,集体智慧就一直活跃在生物学、社会学、计算机科学、大众行为学等领域。随着Web 2.0的崛起和社会性软件的普及,集体智慧这在社交网络服务、众包、分享、评论和推荐等领域也得到了广泛应用 ,典型案例包括:百度百科、猪八戒网、任务中国、Threadless、InnoCentive、digg、iStockphoto、Mechanical Turk等。越来越多的传统公司和组织也开始使用各种集体智慧平台或工具,借助外部智慧以解决复杂问题 。
二.什么是机器学习
1.机器学习简介
- 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
- 它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
- 编程的技知识机器学习的一部分,数学和统计学是机器学习的关键部分。
2.机器学习的局限
- 机器学习的算法受限于算法模式,即它的学习能力以及自主分析能力受限于机器自身。
- 具体的一个表现就是基于少数数据进行的归纳很多都是不精确的(过度归纳)。
- 很多算法在理论上和实际上是有的区别的。
三.学习型算法的其他用处
- 生物工艺学
- 金融欺诈侦测
- 机器视觉
- 产品市场化
- 供应链优化
- 股票市场分析
- 国家安全
四.一些算法原理
协作过滤
概念:对一大群人进行搜索,把其中兴趣相同的人归纳到一块,算法会对这群归纳的人进行其它数据的挖掘,并把他们组合起来制作一个推荐表格。
收集数据
在数据少量时可以使用python的一些内置数据对象进行处理,但是当大量的数据处理时,需要使用数据库。
寻找相近的用户方法
- 欧几里得距离
- 皮尔逊相关度
欧几里得距离
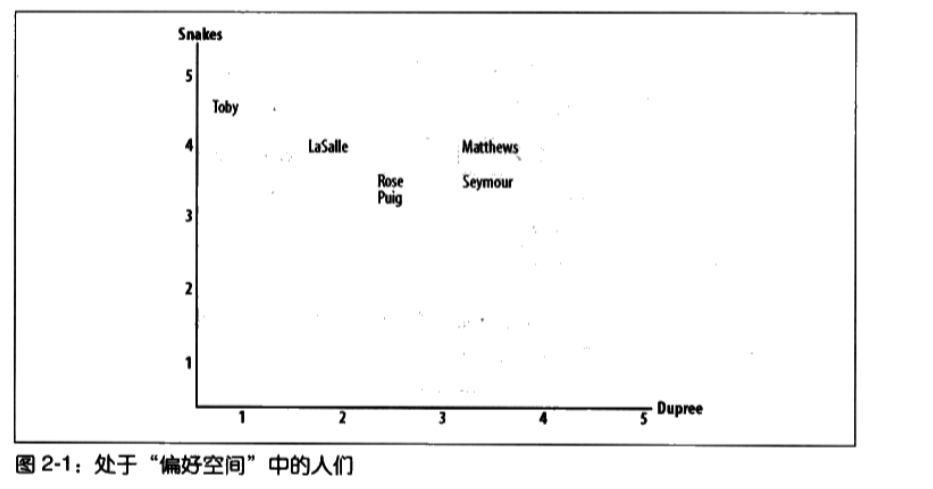
简介
- 计算相似度评价值最简单的一个方法是使用欧几里得距离。
- 定义:指多维空间两点间的距离,当为二维平面的时候我们可以很好的进行想象,两个点的距离计算就是,横坐标相减的平方加上纵坐标相减的平方然后开方,多维的话,以此类推
公式
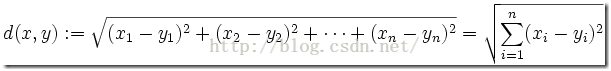
注意事项
- 因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。
- 欧几里得距离是数据上的直观体现,看似简单,但在处理一些受主观影响很大的评分数据时,效果则不太明显;比如,U1对Item1,Item2 分别给出了2分,4分的评价;U2 则给出了4分,8分的评分。通过分数可以大概看出,两位用户褒Item2 ,贬Item1,也许是性格问题,U1 打分更保守点,评分偏低,U2则更粗放一点,分值略高。在逻辑上,是可以给出两用户兴趣相似度很高的结论。如果此时用欧式距离来处理,得到的结果却不尽如人意。即评价者的评价相对于平均水平偏离很大的时候欧几里德距离不能很好的揭示出真实的相似度
代码示例:
'''编程思路
获得两者共同评分项
def sim_distance(数据文档,'person1','person2')
s={}
for item in UL[p1]:
if item in UL[p2]:
si[item] = 1
return si
欧几里得距离算法
如果没有获得相同项,返回0
if len(si) == 0:
return 0
sum_of_squares = sum([pow(UL[p1][item] -UL[p2][item] , 2) for item in si])
return 1/(1+math.sqrt(sum_of_squares))
'''
#!/user/bin/python
# -*- coding: cp936 -*-
from math import sqrt
BJ={'小明':{'唐人街探案':4.9,'湄公河行动':7.8,'红海行动':10},
'小红':{'唐人街探案':4.9,'湄公河行动':7.8,'红海行动':10},
'小将':{'唐人街探案':9.2,'湄公河行动':6.8,'红海行动':6,},
'jace':{'唐人街探案':6.0,'湄公河行动':4.7,'红海行动':8},
'jack':{'唐人街探案':4.9,'湄公河行动':7.8,'红海行动':6},
'davi':{'唐人街探案':9.2,'湄公河行动':6.8,'红海行动':5,},
}
#a=1/sqrt(1+pow(4.9-4.7,2)+pow(7.8-7.0,2))
def sim_distance(prefs,person1,person2):
person1Items = prefs[person1]
commonItemName = [itemName for itemName in person1Items if itemName in prefs[person2]]
if len(commonItemName) == 0:return 0
distance = sqrt(sum([pow(prefs[person1][item]-prefs[person2][item],2) for item in commonItemName]))
return 1/(1+distance)
#输出结果
>>> import ojld_distance
>>> reload(ojld_distance)
<module 'ojld_distance' from 'E:/software/python2\ojld_distance.pyc'>
>>> sim_distance(BJ,'小将','小红')
0.14373291978667996
#!/user/bin/python
# -*- coding: cp936 -*-
from math import sqrt
BJ={'小明':{'唐人街探案':4.9,'湄公河行动':7.8,'红海行动':10},
'小红':{'唐人街探案':4.9,'湄公河行动':7.8,'红海行动':10},
'小将':{'唐人街探案':9.2,'湄公河行动':6.8,'红海行动':6,},
'jace':{'唐人街探案':6.0,'湄公河行动':4.7,'红海行动':8},
'jack':{'唐人街探案':4.9,'湄公河行动':7.8,'红海行动':6},
'davi':{'唐人街探案':9.2,'湄公河行动':6.8,'红海行动':5,},
}
#a=1/sqrt(1+pow(4.9-4.7,2)+pow(7.8-7.0,2))
def distance(p,person1,person2):
s1={}
for item in p[person1]:
if item in p[person2]:
s1[item]=1
if len(s1)==0: return 0
sum_distance=sum([pow(p[person1][item]-p[person2][item],2) for item in p[person1] if item in p[person2]])
return 1/(1+sum_distance)
>>> import sum_distance1
>>> distance(BJ,'小明','小明')
1.0皮尔逊相关度
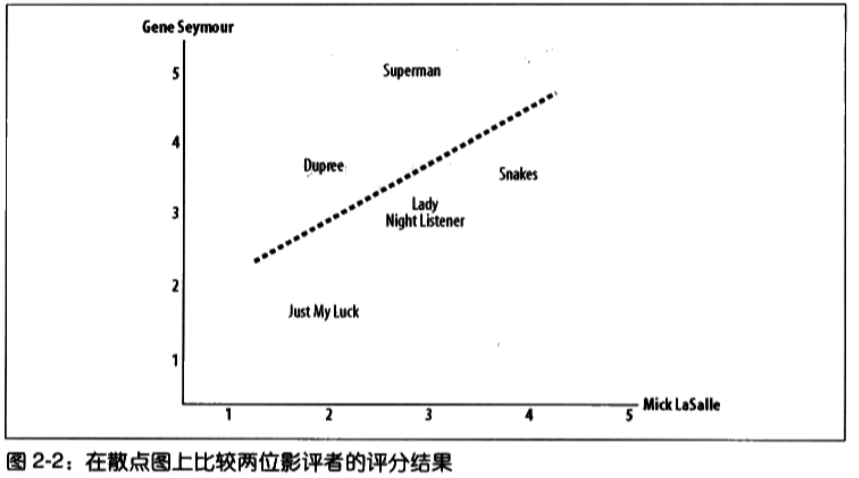
简介
- 用法:皮尔逊相关系数是判断两组数据与某一直线拟合程度的一种度量,在数据不是很规范时(例如某些用户夸大评价)会产出更好的结果。
- 最佳拟合直线:直线和所有的点的距离尽可能近。如果拟合度最佳,则拟合度为一条对角线。
-
相关公式

代码示例
#!/user/bin/python
# -*- coding: cp936 -*-
critics = {
'Lisa':{'Lady':2.5,'Snak':3.5,'Just':3.0,'Superman':3.5,'Dupree':2.5,'Night':3.0},
'Gene':{'Lady':3.0,'Snak':3.5,'Just':1.5,'Superman':5.0,'Dupree':3.5,'Night':3.0},
'Michael':{'Lady':2.5,'Snak':3.0,'Superman':3.5,'Night':4.0},
'Claudia':{'Snak':3.5,'Just':3.0,'Superman':4.0,'Dupree':2.5,'Night':4.5},
'Mick':{'Lady':3.0,'Snak':4.0,'Just':2.0,'Superman':3.0,'Dupree':2.0,'Night':3.0},
'Jack':{'Lady':3.0,'Snak':4.0,'Just':3.0,'Superman':5.0,'Dupree':3.5,'Night':3.0},
'Toby':{'Snak':4.5,'Superman':4.0,'Dupree':1.0}
}
from math import sqrt
def sim_pearson(prefs,p1,p2):
si = {}
for item in prefs[p1]:
if item in prefs[p2]: si[item] = 1
n = len(si)
if n == 0:return 1
sum1 = sum([prefs[p1][it] for it in si])
sum2 = sum([prefs[p2][it] for it in si])
sum1Sq = sum([pow(prefs[p1][it],2) for it in si])
sum2Sq = sum([pow(prefs[p2][it],2) for it in si])
pSum = sum([prefs[p1][it]*prefs[p2][it] for it in si])
num = pSum - (sum1*sum2/n)
den = sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq - pow(sum2,2)/n))
if den == 0: return 0
r = num/den
return r
print (sim_pearson(critics,'Lisa','Gene'))
#输出结果
0.396059017191















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









