






参考链接:https://www.jianshu.com/p/680e8d720516
1. 下载Aspera Connect:在命令行输入如下命令
wget http://download.asperasoft.com/download/sw/connect/3.7.4/aspera-connect-3.7.4.147727-linux-64.tar.gz
2. 解压:
tar zxvf aspera-connect-3.7.4.147727-linux-64.tar.gz
3. 安装:
bash aspera-connect-3.7.4.147727-linux-64.sh
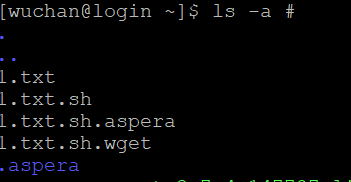
4. 查看是否有.aspera文件夹,去根目录,输入:ls -a #,若看到.aspera文件夹,代表安装成功
5. 永久添加环境变量:
打开~/.bashrc文件,y用vi ~/.bashrc
输入i,切换成编辑命令
export PATH=~/.aspera/connect/bin:$PATH'
Esc,回到命令行
:wq,保存退出
~/.bashrc, 让配置生效
6. 查看帮助文档,验证是否可以调用:
ascp --help
PS:我输入这个命令出现

所以我进行如下操作

之后输入:.aspera/connect/bin/ascp --help 命令就能正常使用aspera工具。
根据 SRA 数据产生的特点,将 SRA 数据分为四类:
Studies-- 研究课题
Experiments-- 实验设计
Samples-- 样品信息
Runs-- 测序结果集
这四种分类有一个层次关系。首先是 Studies->Experiments->Samples->Runs。这也是一个研究
项目正常的逻辑关系。大家要了解这个层级关系, SRA 数据库用不同的前缀加以区分:
ERP 或 SRP 表示 Studies;
SRS 表示 Samples;
SRX 表示 Experiments;
SRR 表示 Runs。
下载工具准备好了,但是我使用的是我师兄的aspera工具,所以我的下载链接从他那边得到。下载步骤如下(由于服务器原因以下步骤的代码仅限于我本电脑使用,你们使用会出错的):
1. 从NCBI上面获得SRA序列号,在sra数据库输入关键词下载,序列号放在SraAccList.txt文件中下载下来
2. 根据脚本语言把SraAccList.txt里面的序列号转成aspera下载的地址链接,注意序列号要格式统一,每行一个序列号且没有空格转换命令:perl /share/home/cuiyong/perl_soft/sra2ftp.change.pl 文件名
3. 然后根据SraAccList.txt.sh.aspera里面的命令去下载,在linux控制台打开这个文件用less SraAccList.txt.sh.aspera,复制黏贴里面的命令到控制台可以直接下载(下载前去查看SRA文件是否存在,有可能序列号在但是没有文件夹,查看序列号文件夹网址ftp://ftp.ncbi.nlm.nih.gov/sra/sra-instant/reads/ByRun/sra/SRR)。















 1052
1052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









