







队列,就是一种先进先出的数据结构,让我们一起来探讨一下队列。
生活中的队列
工作和生活在“北上广”的我们,几乎我们天天会跟队列打交道,各种痛苦的“排队“都能引发大家排山倒海的”槽点“。

给大家回顾一下这些一些排队的经历。
大家还记得当年大冬天的通宵排队买春运的火车票吗?往往轮到自己的时候还经常没票,对“黄牛”都深恶痛绝。
大家有没有去过北京大医院里遭遇过挂号、交费、检查、看病等等一系列的排队吗?往往是经历”看病5分钟,排队5小时“的痛苦遭遇。遇见那些“插队的”、”走后门的“真想上前踹TMD一脚,但终究理智战胜冲动,只能在心里默默问候那些人祖宗十八代。
可能生活中离我们最近的“队列”估计还是每天上下班地铁站入口处那长长的队伍,尤其是夏天,人挨人,队伍还只能缓慢的移动,那种经历真是苦不堪言啊。我最深刻的记忆是曾经从昌平线的沙河地铁站进站,我走了足足有2分钟,竟然一直看不到队尾,当时的那种绝望的心情让我终身难忘。
大家纳闷了,我们这还是技术文章吗?是不是扯远了?其实说生活中的例子,只能是让大家对“队列”有一个最直观的感受而已。
从生活中的“队列”我们可以看出,“队列”其实真不是什么好东西,它只是因为业务处理能力短时间无法满足业务需求的一种不得已而为之的解决方案,体验真是非常糟糕,那为什么不增加业务处理能力呢?增加一些业务窗口,把地铁站建大一些,这样大家就可以不排队了? 你仔细思考一下,如果真的可行的话,他们早就这样做了。大家想想,我们要排队的时候往往都是业务需求的高峰期,“春运”、”早高峰“、”大医院“这些峰值都是业务需求的不均匀导致的,如果为了短时间的高峰,而投入过多的设施或者资源,那么在大多数时候这些资源的投入就存在巨大的浪费,任何一个组织都不可能承受这样巨大的资源浪费,所以为了消除业务需求的“峰值”,只能委屈大家在队伍中积压一段时间。
生活中的“排队“既然不可避免,我们还有办法提高用户体验吗?其实大家已经都感受到了,就是从线下转到线上来排队,将你的业务需求转化信息,让这些信息在队伍中积压着,当轮到你了再以短信或其它渠道告知你,然后你再到线下去处理业务,就大大改善了用户体验,让数据去排序,我们该干嘛还干嘛。
感谢CCTV、感谢党和政府,12306让我们再也用不着通宵排队了,大家开始用各种刷票软件抢票了,体验好了不少,但是火车票依旧难买。。。
地铁站的排队好像还没有办法提高用户体验,咱总不能头天晚上先在北京地铁的app上先取一个号,然后凭号入站吧?哈哈哈。。。
医院的排队其实还是很多解决方案的,只是北京大医院的问题好像不是排队,而是供不应求,这个方法好像也不灵。。。
还有北京的汽车摇号排队,由于严格按照先进先出排队则等待时间太长(我算了一下我自己需要等待50年的时间,绝望!!!),所以干脆改成随机选,这样体验好像好了一些,将每次摇号的绝望提高到渺茫的希望。。。。。
虽然这些问题可能暂时都不能完美的解决,但是别忘了:”生活不止眼前的排队,还有互联网公司的各种颠覆“,等待正在努力的各种互联网公司来逐一解决这些问题吧。
Java中队列
说生活中的队列的目的,只是想让大家有非常直观的感受,大家能够体会到,虽然术不同,但是道却相通。生活中的队列与Java中的队列还是有非常多的相似之处的。

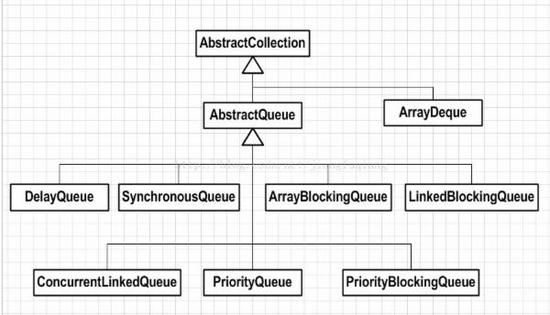
最典型的队列结构如上图,从队尾如队,从队头出队,在队列中积压着待处理的队列。
Jdk自带队列
jdk中自带了非常多的队列,它们都是接口Queue的各种实现类,下面是总结出队列的特性。’
- 线程安全。
天然的多线程环境,一般来说至少消费者和生产者往往不是同一个线程,因此全部为线程安全的队列。
- 数据结构。
可以用数组和链表两种结构来存储元素,名称包含Array的往往是数组结构实现的,名称包含Linked的往往是链表结构实现的。由于队列无需按下标取数据,因此链表能够避免这种取数据效率低的 问题,但是数组结构长度是固定的,因此一般都是有界限的队列,扩容会导致性能下降,因此 Linked的实现更优,一般用这种实现类。 元素积压是否有界。
- 界限。
如果队列积压数据过多,则非常不安全,有可能会导致jvm内存溢出,因此需要限制队列积压数量,若支持限制则表示有界,否则无界。
- 阻塞。
当队列中无数据,消费者取数据为空,若可阻塞,则消费者的线程会阻塞,等待数据的生产。若有界队列的队列慢了,则阻塞生产者可线程,等待数据的消费。带有Blocking的实现类是阻塞队列。
- 持久化。
队列中积压的数据是否能够持久化,在jvm进程因为意外退出后重启队列数据可恢复。目前jdk自带的都不支持该特性,意味着队列中的数据在jvm进程退出后将会丢失。
- 优先级。
有些时候业务是分优先级的,比如我们去银行办业务,银行都有vip专用窗口,基本上都不用排队,这就是生活中的优先级队列。PriorityQueue是优先级队列,在入队的时候根据数据的排序入队。实际上它是一种自定义的顺序,一般的队列是以入队时间为顺序,而优先级队列则是自定义顺序。
- 双向队列
这是一种特殊的队列,队列的头和尾都可以入对和出对,这种队列的好处就是在处理能力较强的时候,可以从两头处理,这样竞争程度会降低一些。Deque接口的实现实现类就是双向队列。
- 延迟消费
有这么一种场景,当我们的消费者还没有准备好消费数据,它需要等待一段时间才消费数据,这种场景就需要延迟消费特性。比如我们用队列实现定时任务TimeQueue等等。DelayQueue就是jdk中定义的一个延迟队列。
- 直接传递
当消费者空闲在等待任务的时候,入队的数据可以直接传递给消费者,就避免了出队和入队的消耗,提高了cpu的吞吐量。这就好比我们去排队的时候突然发现一个窗口空了,聪明的人都会直接跑到那个窗口去处理业务,而不再排队。TransferQueue就是直接传输特性的队列接口。
- 其它
其实我们可以根据自己的需要自行扩展实现符合自己需求的队列,不过更推荐的是直接使用apache-commons或者google扩展的一些队列。
总结
我们最后总结一下jdk自带的队列到底适合哪些具体的使用场景,方便大家选择合适的解决方案。
- 缓冲jvm进程内部线程间的高峰。
- 解耦生产者和消费者。
- 队列消息无需持久化场景。
- 非分布式场景。
在jdk并发中的线程池使用了阻塞队列,用队列来缓冲来不及处理的请求,但是这些请求在进程退出后是会丢失的,在这种场景中是允许的。
消息中间件
我们在构建分布式系统的时候都会大量的使用分布式消息中间件,目前开源的一些消息中间件产品有ActiveMQ、RabbitMQ、ZeroMQ、RocketMQ和Kafka等。这些产品各有特点,它与jdk自带的队列都属于队列的解决方案,消息中间件的主要区别是它用于分布式场景,能够支持生产者、消费者的多进程集群扩展,因此它能够应用更加复杂的使用场景,比如使用在多个系统间的消峰和解耦等。
消息中间的特性有这些,不同的消息中间件产品可能在特性上特有侧重,因此适用于不同的业务场景。
- 持久化。
多数消息中间件都是支持持久化的,因为分布式系统的单点不可靠性决定了如果不持久化将会导致消息丢失,而多数业务是不可接受的。ZeroMQ不支持持久化。
- 发布订阅
消息中间的基本功能,生产者发布消息,消费者可以订阅消息,一般支持P2P和topic两种模式。
- 消息优先级
由于分布式消息中间件往往支持海量消息积压量,因此它不能支持消息全局排序,否则会严重影响性能。可以通过业务设置多个队列来实现消息优先级。
- 消息顺序
消息顺序是指消息的消费要按照入队的顺序,强制顺序就会制约消息消费的并发处理能力,并且当某个消息消费失败,则严格的顺序性会阻塞后面的消息消费,则对系统的处理能力有严重影响,这两者是矛盾的因素,因此多数对于消息顺序要求不严格的场景,不需要严格的消息顺序特性。但是对于比如使用canal等组件同步mysql的binlog等场景,则需要比较严格的一致性,这种情况应该可以通过将队列尽可能拆分得更小,在更小的队列保持严格的有序性,比如某张表的binlog就是一个队列,找到那些真正有依赖关系的消息,井它们分布在同一个队列中。
- 消息过滤
在复杂的分布式场景中,消息发布后,会有很多业务系统对同一个主题感兴趣,但是不同的消费者关注点有差异,因此消费者有可能只关注部分消息,因此它需要过滤消息。该特性就是解决该问题。一般分为消息服务器过滤和消息客户端过滤,两者的区别是服务端过滤能够避免多余的IO。
- 低延迟
在有些场景下,业务对于数据处理的时效性有一定要求,希望消费者尽快能接收到发送者的消息及时消费。这就要求中间件支持低延迟数据消费,发送者发送的消息能够在非常短的延时内推送给消费者,一般通过push或者长轮询pull方式实现。
- 回溯消息
新接入的消费者需要指定消费的起始位置(或者是时间),当消费者消费的时候出了故障,需要重复指定位置将这段时间内的消息重复消费一次,这就是回溯消息的特性。
- 消息堆积量
堆积在消息队列中的消息数据量,分布式系统一般都支持海量的消息量堆积,所以一般消息都是可以存储在磁盘上的,否则受限于内存的容量则无法存储足够的消息。
- 分布式事务
- 定时消息
和jdk中的队列一样,分布式系统中某些消费者没有达到消费的时机,需要等待一段时间,等待消费时机的到来之后才进行消费,因此定时消息就是可以设置延时消费的时间。RocketMQ支持粗粒度的延时消息。
- 消息重试
这也是在分布式系统中非常重要的一个特性,消息消费可能由于某种偶然的网络因素导致消费失败,为了减少人工的干预,则需要支持消息重试机制,一般都支持等待一段时候之后重试,重试了N次之后就归档(认为该消息确实无法消费,无需重试)。















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









