







GBDT特征交叉
学习目标
- 知道如何使用GBDT进行特征交叉
1. GBDT特征衍生简介
在风控领域发展过程中,使用最多的方法是逻辑回归,逻辑回归使用了sigmoid变换将函数值映射到[0,1]区间,映射后的函数值就是对一个人违约概率的预估值。逻辑回归同样属于广义线性模型,容易并行化,可以轻松处理上亿条数据,但是学习能力十分有限,需要大量的特征工程来增加模型的学习能力。
将连续特征离散化,并对离散化的特征进行one-hot编码,最后对特征进行多阶的 特征组合 ,也是特征衍生的常用手段。人工特征组合存在几个难题:
- 不知道连续变量切分点如何选取
- 不知道离散化为多少份最为合理
- 不知道选择哪些特征交叉会对模型有帮助,而交叉多少阶也没有明确的答案
一般都是按照经验,不断尝试一些组合,然后根据时间外样本集评估、选择适当的参数。
使用GBDT编码可以解决大部分的问题:
- 确定切分点不再是凭主观经验,而是根据均方差减小,客观地选取切分点和份数
- 每棵决策树从根节点到叶节点的路径,会经过不同的特征,此路径就是特征组合,而且包含二阶、三阶甚至更多。
离散的箱数主要由树的深度决定。树的深度仍然是一个超参数,需要通过测试集进行调整。我们可以将GBDT的输出作为评分卡模型中的部分独立特征。
2. GBDT+LR
可以使用LightGBM模型对原始训练数据进行训练,得到一个分类器。LightGBM模型的效果越好,对后续模型融合的帮助越大。
与常规模型融合方法不一样的是,LightGBM模型训练结束后,输出的并不是预测的概率值,而是把每个样本所落在的叶节点位置记为1,这样,就构造出了每个样本新的特征,特征的维度取决于LightGBM模型树的个数。
因为决策树的互斥性,每个样本只会落在树上的一个节点,所以在一个具有n个弱分类器、共m个叶节点的LightGBM模型中,每一条训练数据都会被转换为1×m维稀疏向量,且有n个元素为1,其余m-n个元素全为0
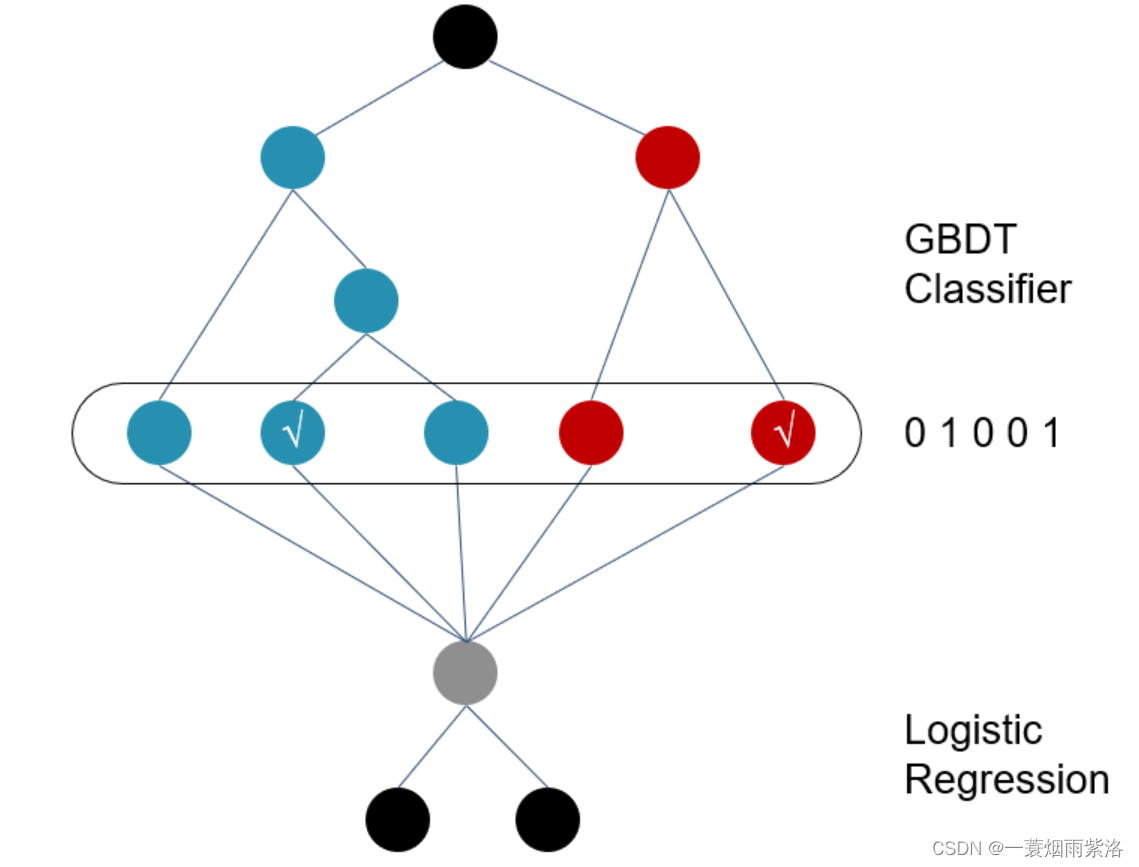
上图中红色和蓝色为通过GBDT模型学习得到的两棵树。假设x为一条输入样本,遍历两棵树后,x样本分别落到两棵树的叶节点上,每个叶节点对应衍生出的交叉特征中的一个维度。由于树的每条路径,是通过最小化均方差等方法最终分割出来的有区分性的路径,根据该路径得到的交叉特征,可以起到不错的效果。 新的特征构造完成后,接下来就要与原始特征一起送入逻辑回归中进行最终的训练
- 由于弱分类器个数、叶节点个数的影响,可能会导致新的特征维度过大
- 在实际建模的过程中,可能会使用PSI和树模型的特征重要性对交叉特征进行筛选。
3. 案例
import lightgbm as lgb
import random
import pandas as pd
import numpy as np
from 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4463
4463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









