







1、贝叶斯定理
在一个论域中,某个事件A发生的概率用P(A)表示。
事件的条件概率P(A|B)的定义为:在事件B已经发生的前提下事件A发生的概率。公式如下:

那么给一个样本X分类,即已知一组类 Y1 , Y2 , …, Yk 和一个未分类样本X, 判断X应该属于Y1, Y2, …, Yk 其中哪个类别。利用贝叶斯定理,则问题转换为:样本X属于这k个类中的哪一个类的几率最大。公式如下:
![]()
2、算法分析
假设每个数据样本用一个n维特征向量来描述n个属性的值,即:X={X1 , X2 , … ,Xn}。假定有m个类,分别用Y1 , Y2 , Y3 , … , Ym 表示。给定一个未分类的数据样本X,若朴素贝叶斯分类时未分类样本X落入分类Yi,则一定有P(Yi|X) >= P(Yj|X), 1 <= j <= m 。
根据朴素贝叶斯公式,由于未分类样本X出现的概率P(X)对于所有分类为定值,因此只需要计算P(Yi|X)的相对值大小,所以概率P(Yi|X)可转化为计算P(X|Yi)P(Yi)
如果样本X中的属性xj有相关性,计算P(X|Yi)将会非常复杂,因此,通常假设X的各属性xj是互相独立的,这样P(X|Yi)的计算可简化为求P(x1|Yi),P(x2|Yi),…,P(x3|Yi)之积;而每个P(xj|Yi)和P(Yi)都可以从训练数据中求得
因此对一个未分类的样本X ,可以先计算X属于每一个分类Yi的概率P(X|Yi)P(Yi),然后选择其中最大的Yi作为其分类.
根据上述分析,朴素贝叶斯算法分为两个阶段,如下:
第一阶段:样本训练阶段
计算每个分类Yi出现的频度 P(Yi),以及每个属性值xj出现在Yi中的频度 P(xj|Yi)
第二阶段:分类预测阶段
针对未分类样本X其每一个具体属性xj,根据从训练数据集计算出的P(xj|Yi)进行求积得到样本X对于Yi的条件概率P(X|Yi),再乘以P(Yi)即可得到X在各个Yi中出现的频度P(X|Yi)P(Yi),取最大频度的Yi即为X所属的分类。
如果经过分析,你还是不懂我在说什么,建议先去百度一下原理再来看代码实现。
3、首先是样本训练阶段,准备训练样本数据,统计每个样本Yi出现的频度及其每个属性xj在样本Yi中出现的频度。数据如下:
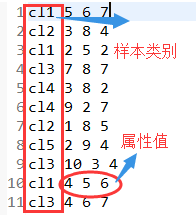
代码实现:
/**
* 贝叶斯训练集
* @author ZD
*/
public class BayesTrain {private static class BayesTrainMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
context.write(new Text(strs[0]), new IntWritable(1));
for (int i = 1; i < strs.length; i++) {
context.write(new Text(strs[0]+":"+i+":"+strs[i]), new IntWritable(1));
}
}
}private static class BayesTrainReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) {
try {
Configuration cfg = HadoopCfg.getConfigration();
Job job = Job.getInstance(cfg);
job.setJobName("BayesTrain");
job.setJarByClass(BayesTrain.class);
job.setMapperClass(BayesTrainMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(BayesTrainReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/input/bayes/train/"));
FileOutputFormat.setOutputPath(job, new Path("/Bayes/train/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果如下:
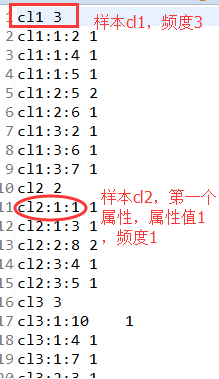
4、分类预测阶段。通过样本训练阶段后,我们知道了样本频度及其每个属性的频度,现在就可以预测样本X属于哪一个样本。实现原理:先将样本和属性存入两个不同的map,然后遍历样本及样本中的属性,通过计算每个属性的P(xj|Yi)的乘积,得出P(X|Yi),最后写出概率最大的样本即可。
预测样本数据如图:

代码实现如下:
/**
* 贝叶斯预测算法
* @author ZD
*/
public class BayesTest {
private static class BayesTestMapper extends Mapper<LongWritable, Text, Text, Text>{
private Map<String, Integer> fy = new HashMap<>(); //分类频度表
private Map<String, Integer> fxy = new HashMap<>(); //属性频度表
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileSystem fs = FileSystem.get(context.getConfiguration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(new Path("/Bayes/train/part-r-00000"))));
String line = "";
while((line = br.readLine())!=null){
String[] strs = line.split("\t"); //处理的训练集数据,以\t分割
if(line.contains(":")){
fxy.put(strs[0], Integer.parseInt(strs[1]));
}else{
fy.put(strs[0], Integer.parseInt(strs[1]));
}
}
br.close();
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String[] strs = value.toString().split(" "); //处理的预测文件数据,以空格分割
int max=-1;
String finalType="";
for(String type:fy.keySet()){
int tempMax=1;
int fyCount = fy.get(type);
//strs.length代表属性个数
int fxyCount = 1;
for(int i=1; i<strs.length; i++){
//获取属性值
fxyCount = (fxy.get(type+":"+i+":"+strs[i])==null)?1:fxy.get(type+":"+i+":"+strs[i])+1;
tempMax = tempMax*fxyCount; //因为样本中各属性相互独立,所以P(X|Yi)可简化为P(x1|Yi),P(x2|Yi),…,P(xj|Yi)之积
}
if(tempMax>max){
max = tempMax;
finalType = type;
}
}
context.write(value, new Text(finalType));
}
}
private static class BayesTestReducer extends Reducer<Text, Text, Text, Text> {@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(key, value);
}
}
}
public static void main(String[] args) {
try {
Configuration cfg = HadoopCfg.getConfigration();
Job job = Job.getInstance(cfg);
job.setJobName("BayesTest");
job.setJarByClass(BayesTest.class);
job.setMapperClass(BayesTestMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(BayesTestReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/input/bayes/test/"));
FileOutputFormat.setOutputPath(job, new Path("/Bayes/test/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果如下:

写在最后:若有错误,望指出纠正。















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









