






Softmax Regression Tutorial地址:http://ufldl.stanford.edu/tutorial/supervised/SoftmaxRegression/
从本节開始,难度開始加大了。我将更具体地解释一下这个Tutorial。
1 Softmax Regression 介绍
其实。我们仅仅要把Logistic Regression练习中的样本换成手的样本。那么就能用训练出来的结果来识别手了,因此Logistic Regression是非常实用且强大的算法。
2 Cost Function
然后假设k=2就是仅仅有0或1,能够推出Logistic Regression的Cost Function是上面公式的特殊形式。
在Softmax Regression 中,有
P(y(i)=k|x(i);θ)=exp(θ(k)⊤x(i))∑Kj=1exp(θ(j)⊤x(i))
然后给出theta偏导的公式:
这里 ∇θ(k)J(θ) 本身是向量, 因此它的第j个元素是 ∂J(θ)∂θlk , J(θ) 关于 θ(k)的第j个元素的偏导。
3 Softmax Regression參数化的属性
4 Weight Decay 权值衰减

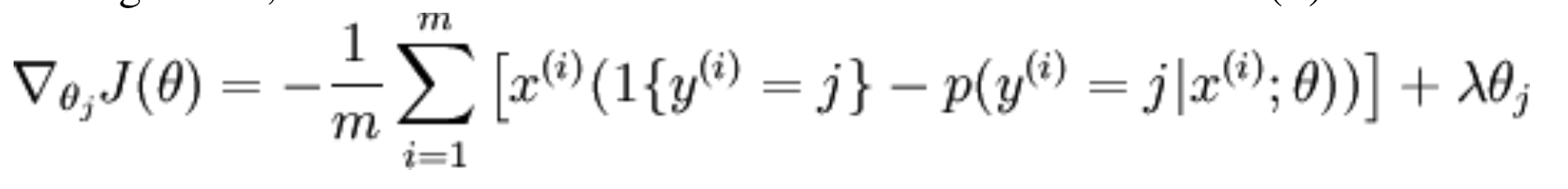
5 Softmax Regression vs. k Binary Classifiers
。。
这些类是相关的,就不能用Softmax Regression来攻克了。
6 exercise解答
方法和前面的练习都是一样的。最困难的问题在于怎样用Vectorization来将Cost Function和Gradient表达出来。
以下是我的解答,仅仅列出softmax_regression_vec.m
function [f,g] = softmax_regression_vec(theta, X,y)
%
% Arguments:
% theta - A vector containing the parameter values to optimize.
% In minFunc, theta is reshaped to a long vector. So we need to
% resize it to an n-by-(num_classes-1) matrix.
% Recall that we assume theta(:,num_classes) = 0.
%
% X - The examples stored in a matrix.
% X(i,j) is the i'th coordinate of the j'th example.
% y - The label for each example. y(j) is the j'th example's label.
%
m=size(X,2);
n=size(X,1);
% theta is a vector; need to reshape to n x num_classes.
theta=reshape(theta, n, []);
num_classes=size(theta,2)+1;
theta = [theta,zeros(n,1)];
% initialize objective value and gradient.
f = 0;
g = zeros(size(theta));
%
% TODO: Compute the softmax objective function and gradient using vectorized code.
% Store the objective function value in 'f', and the gradient in 'g'.
% Before returning g, make sure you form it back into a vector with g=g(:);
%
%%% YOUR CODE HERE %%%
yCompare = full(sparse(y, 1:m, 1)); %??y == k ???
%yCompare = yCompare(1:num_classes-1,:); % ?
?y = 10???
M = exp(theta'*X); p = bsxfun(@rdivide, M, sum(M)); f = - yCompare(:)' * log(p(:)); g = - X*(yCompare - p)'; g = g(:,1:num_classes - 1); g=g(:); % make gradient a vector for minFunc
怎样解释是个比較麻烦的问题,我推出的方法还是通过矩阵的size。
首先cost function有两个连加号,这意味着假设每个计算得出一个值,cost function能够得到一个kxm的矩阵,而yCompare就是kxm,因此后面的概率项也应该如此。theta‘*X是非常easy想到的,得到kxm,而对于概率项的分母,我们得这样理解:kxm每个列就是某一个样本相应于每个类的数据,我们因此对于分母项的求法非常easy。就是用sum把每一列的数据加起来。
其它的推导是一样的道理。
执行结果为:
Average error :0.000005 (Gradient Checking 结果显示梯度计算没有问题)
Training accuracy: 94.4%
Test accuracy: 92.2%
这里有一些实用的MATLAB函数须要关注一下:
full 和 sparse。举比例如以下:
>> y = [1 2 3]
y =
1 2 3
>> sparse(y,1:3,1)
ans =
(1,1) 1
(2,2) 1
(3,3) 1
>> full(sparse(y,1:3,1))
ans =
1 0 0
0 1 0
0 0 1而bsxfun能够用来做矩阵的各种运算,非常快!
非常多函数假设不清楚一种就是直接在MATLAB help,一种那就是直接百度了。
【本文为原创文章,转载请注明出处:blog.csdn.net/songrotek 欢迎交流QQ:363523441】
















 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









