







注意:关闭R之前务必保存工作空间,保证学习的连续性。这样以前数据的控制台命令执行的效果以及相关变量仍然保存在内存中。
1 访问数据框变量
建议:在read.table命令执行names查看要处理的变量
> names(Squid)
[1] "Sample" "Year" "Month" "Location" "Sex" "GSI"
>
1.1 str函数
str函数可以查看数据框中每个变量的属性:
> str(Squid)
'data.frame': 2644 obs. of 6 variables:
$ Sample : int 1 2 3 4 5 6 7 8 9 10 ...
$ Year : int 1 1 1 1 1 1 1 1 1 1 ...
$ Month : int 1 1 1 1 1 1 1 1 1 2 ...
$ Location: int 1 3 1 1 1 1 1 3 3 1 ...
$ Sex : int 2 2 2 2 2 2 2 2 2 2 ...
$ GSI : num 10.44 9.83 9.74 9.31 8.99 ...
>
Sample ,Yead,Month,Location,Sex这几个变量是整型
GSI这个变量是数值型
GSI这个变量是存在于数据框Squid中的,不能通过在R控制台中输入GSI查看
> GSI
错误: 找不到对象'GSI'
>
1.2 函数中的数据参数--访问数据框中的变量的最佳方式
> M1 <- lm(GSI ~ factor(Location)+factor(Year),data = Squid)
> M1
Call:
lm(formula = GSI ~ factor(Location) + factor(Year), data = Squid)
Coefficients:
(Intercept) factor(Location)2 factor(Location)3 factor(Location)4
1.3939 -2.2178 -0.1417 0.3138
factor(Year)2 factor(Year)3 factor(Year)4
1.3548 0.9564 1.2270
>
data = 并不是适用于任何函数,eg:
> mean(GSI,data = Squid)
错误于mean(GSI, data = Squid) : 找不到对象'GSI'
>
1.3 $ 符号 访问变量的另外一种方法
Squid$GSI
> Squid$GSI
[1] 10.4432 9.8331 9.7356 9.3107 8.9926 8.7707 8.2576 7.4045
[9] 7.2156 6.8372 6.3882 6.3672 6.2998 6.0726 5.8395 5.8070
[17] 5.7774 5.7757 5.6484 5.6141 5.6017 5.5510 5.3110 5.2970
[25] 5.2253 5.1667 5.1405 5.1292 5.0782 5.0612 5.0097 4.9745
或者
Squid[,6]
> Squid[,6]
[1] 10.4432 9.8331 9.7356 9.3107 8.9926 8.7707 8.2576 7.4045
[9] 7.2156 6.8372 6.3882 6.3672 6.2998 6.0726 5.8395 5.8070
[17] 5.7774 5.7757 5.6484 5.6141 5.6017 5.5510 5.3110 5.2970
[25] 5.2253 5.1667 5.1405 5.1292 5.0782 5.0612 5.0097 4.9745
此时可以通过mean求平均值
> mean(Squid$GSI)[1] 2.187034
>
1.4 attach 函数
attach函数将数据框添加到R的搜索路径中,此时就可以通过GSI命令直接查看GSI数据
> attach(Squid)
> GSI
[1] 10.4432 9.8331 9.7356 9.3107 8.9926 8.7707 8.2576 7.4045
[9] 7.2156 6.8372 6.3882 6.3672 6.2998 6.0726 5.8395 5.8070
[17] 5.7774 5.7757 5.6484 5.6141 5.6017 5.5510 5.3110 5.2970
[25] 5.2253 5.1667 5.1405 5.1292 5.0782 5.0612 5.0097 4.9745
> boxplot(GSI)
>
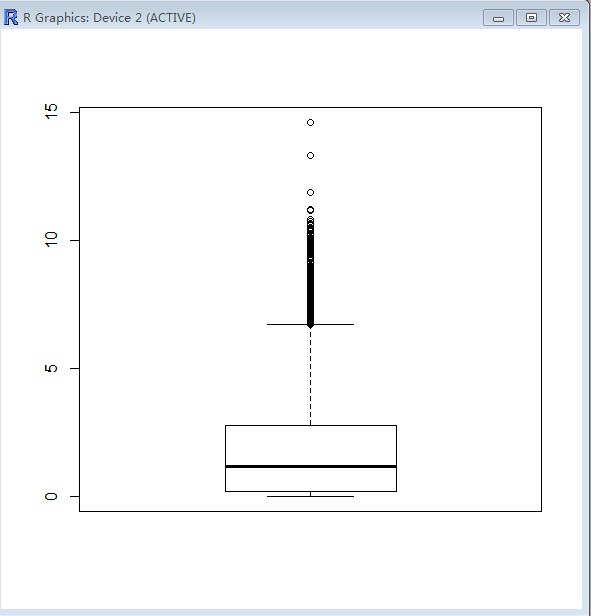
(额、、看不懂这个图)
使用attach函数显然应该小心保证变量名字的唯一性,如果与R自带函数名字或者变量一样肯定会出问题。
attach使用总结:
(1)为了避免复制变量,避免输入Squid$GSI两次以上
(2)使用attach命令应该保证变量的唯一性
(3)如果要处理多个数据集,而且一次只处理一个数据集,使用detach函数将数据集从R搜索路径中删除
2 访问数据集
首先执行detach(Squid)命令!!!
查看Squid中Sex的值
> Squid$Sex
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2
[36] 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 1 2 1 1 1 1 2 1 1 1 1 1 1
显示位移值
> unique(Squid$Sex)
[1] 2 1
>
其中1表示雄性2表示雌性
> Sel <- Squid$Sex == 1
> SquidM <- Squid[Sel,]
> SquidM
Sample Year Month Location Sex GSI
24 24 1 5 1 1 5.2970
48 48 1 5 3 1 4.2968
58 58 1 6 1 1 3.5008
60 60 1 6 1 1 3.2487
61 61 1 6 1 1 3.2304
SquidM <- Squid[Sel,]这条命令表示选择Squid中Sel等于TRUE的行,并将数据存储到SquidM中。因为是选择行,所以需要使用方阔号。
第三章未完待续...
go on
获得雌性数据
> SquidF <- Squid[Squid$Sex == 2,]
> SquidF
Sample Year Month Location Sex GSI
1 1 1 1 1 2 10.4432
2 2 1 1 3 2 9.8331
3 3 1 1 1 2 9.7356
4 4 1 1 1 2 9.3107
5 5 1 1 1 2 8.9926
下面几条命令不解释:
unique(Squid$Location)
Squid123 <- Squid[Squid$Location == 1 | Squid$Location ==2 | Squid$Location == 3,]
Squid123 <- Squid[Squid$Location != 4,]
Squid123 <- Squid[Squid$Location < 4 ,]
Squid123 <- Squid[Squid$Location <=3 ,]
Squid123 <- Squid[Squid$Location >=1 &Squid$Location <=3 ,]
都是获得Location值为1,2,3的行
> unique(Squid$Location)
[1] 1 3 4 2
> Squid123 <- Squid[Squid$Location == 1 | Squid$Location ==2 | Squid$Location == 3,]
> Squid123
Sample Year Month Location Sex GSI
1 1 1 1 1 2 10.4432
2 2 1 1 3 2 9.8331
3 3 1 1 1 2 9.7356
4 4 1 1 1 2 9.3107
5 5 1 1 1 2 8.9926
6 6 1 1 1 2 8.7707
获得Location值为1的雄性数据行
> SquidM.1 <- Squid[Squid$Sex == 1 & Squid$Location == 1,]
> SquidM.1
Sample Year Month Location Sex GSI
24 24 1 5 1 1 5.2970
58 58 1 6 1 1 3.5008
60 60 1 6 1 1 3.2487
> SquidM.12 <- Squid[Squid$Sex == 1 &( Squid$Location == 1 | Squid$Location == 2),]
> SquidM.12
Sample Year Month Location Sex GSI
24 24 1 5 1 1 5.2970
58 58 1 6 1 1 3.5008
60 60 1 6 1 1 3.2487
> SquidM1
Sample Year Month Location Sex GSI
24 24 1 5 1 1 5.2970
58 58 1 6 1 1 3.5008
..........
..........
NA NA NA NA NA NA NA
NA.1 NA NA NA NA NA NA
NA.2 NA NA NA NA NA NA
NA.3 NA NA NA NA NA NA
NA.4 NA NA NA NA NA NA
..........
原因分析:
之前得到的SquidM表示雄性数据,显然SquidM的行数与Squid$Location == 1 布尔向量的长度不一致。因此导出出现上面的现象。
2.1 数据排序
> Ord1 <- order(Squid$Month)
> Squid[Ord1,]
Sample Year Month Location Sex GSI
1 1 1 1 1 2 10.4432
2 2 1 1 3 2 9.8331
3 3 1 1 1 2 9.7356
4 4 1 1 1 2 9.3107
根据月份排序
也可以只对一个变量进行排序
> Squid$GSI[Ord1]
[1] 10.4432 9.8331 9.7356 9.3107 8.9926 8.7707 8.2576 7.4045
[9] 7.2156 6.3882 6.0726 5.7757 1.2610 1.1997 0.8373 0.6716
[17] 0.5758 0.5518 0.4921 0.4808 0.3828 0.3289 0.2758 0.2506
[25] 0.2092 0.1792 0.1661 0.1618 0.1543 0.1541 0.1490 0.1379
> setwd("E:/R/R-beginer-guide/data/RBook")
> Sql1 <- read.table(file = "squid1.txt",header = TRUE)
> Sql2 <- read.table(file = "squid2.txt",header = TRUE)
> SquidMerged <- merge(Sql1,Sql2,by = "Sample")
> SquidMerged
Sample GSI YEAR MONTH Location Sex
1 1 10.4432 1 1 1 2
2 2 9.8331 1 1 3 2
3 3 9.7356 1 1 1 2
4 5 8.9926 1 1 1 2
5 6 8.7707 1 1 1 2
6 7 8.2576 1 1 1 2
merge 命令采用两个数据框Sql1 ,Sql2作为参数并使用变量Sample作为形同的标识符合并两个数据。merger函数还有一个选项是all,缺省状态值是FALSE:即如果Sql1或Sql2中的值有缺失,则将被忽略。如果all的值设置为TRUE,可能会产生NA值
Sql11 <- read.table(file = "squid1.txt",header = TRUE)
Sql21 <- read.table(file = "squid2.txt",header = TRUE)
SquidMerged1 <- merge(Sql11,Sql21,by = "Sample")
SquidMerged1
额、、这里好像没有出现NA,看来是数据没有丢失
4 输出数据
通过write.table将数据输出为ascii文件
write.table(SquidM,file = "MaleSquid_wujiahua.txt",sep = " ",quote = FALSE,append = FALSE,na = "NA")
查看工作目录,生成了一个MaleSquid_wujiahua.txt文件,
打开:
Sample Year Month Location Sex GSI
24 24 1 5 1 1 5.297
48 48 1 5 3 1 4.2968
58 58 1 6 1 1 3.5008
60 60 1 6 1 1 3.2487
61 61 1 6 1 1 3.2304
说明:
write.table第一个参数表示要输出的数据,第二参数是数据保存的文件名,sep = " " 宝成数据通过空格隔开,qoute=FALSE消除字符串的引号标识,na="NA"表示缺失值通过NA替换。append=TRUE表示把数据添加到文件的尾部
5 重新编码分类变量
> str(Squid)
'data.frame': 2644 obs. of 6 variables:
$ Sample : int 1 2 3 4 5 6 7 8 9 10 ...
$ Year : int 1 1 1 1 1 1 1 1 1 1 ...
$ Month : int 1 1 1 1 1 1 1 1 1 2 ...
$ Location: int 1 3 1 1 1 1 1 3 3 1 ...
$ Sex : int 2 2 2 2 2 2 2 2 2 2 ...
$ GSI : num 10.44 9.83 9.74 9.31 8.99 ...
在数据框中一般根据分类变量生成新的变量
> Squid$fLocation <- factor(Squid$Location)
> Squid$fSex <- factor(Squid$Sex)
> Squid$fLocation
[1] 1 3 1 1 1 1 1 3 3 1 1 1 1 1 1 1 3 1 3 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 3 1 1 1 1 3 1 1 3 1 1 1 1 1 1 1 3 1 1 1 1 1 3 1 1 1 1 1 1 1 1
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2
[36] 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 1 2 1 1 1 1 2 1 1 1 1 1 1
[71] 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 2 1 1 1
[2591] 1 1 1 1 1 1 1 1 1 2 1 1 2 1 1 2 1 1 1 2 1 2 1 1 2 1 1 2 1 2 2 1 1 1 1
[2626] 1 1 1 1 1 2 1 1 1 2 1 2 1 2 1 2 1 1 1
Levels: 1 2
fLocation和fSex只是名义变量,f表示他们是因子
levels:1,2可以对其修改
> Squid$fSex <- factor(Squid$Sex,levels = c(1,2),labels = c("M","F"))
> Squid$fSex
[1] F F F F F F F F F F F F F F F F F F F F F F F M F F F F F F F F F F F
[36] F F F F F F F F F F F F M F F F F F F F F F M F M M M M F M M M M M M
[2591] M M M M M M M M M F M M F M M F M M M F M F M M F M M F M F F M M M M
[2626] M M M M M F M M M F M F M F M F M M M
Levels: M F
>
使用重新分类的因子变量
boxplot(GSI ~ fSex,data = Squid)

> M1 <- lm(GSI ~ fSex+fLocation,data = Squid)
> M1
Call:
lm(formula = GSI ~ fSex + fLocation, data = Squid)
Coefficients:
(Intercept) fSexF fLocation2 fLocation3 fLocation4
1.3593 2.0248 -1.8552 -0.1425 0.5876
> summary(M1)
Call:
lm(formula = GSI ~ fSex + fLocation, data = Squid)
Residuals:
Min 1Q Median 3Q Max
-3.4137 -1.3195 -0.1593 1.2039 11.2159
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.35926 0.07068 19.230 <2e-16 ***
fSexF 2.02481 0.09427 21.479 <2e-16 ***
fLocation2 -1.85525 0.20027 -9.264 <2e-16 ***
fLocation3 -0.14248 0.12657 -1.126 0.2604
fLocation4 0.58756 0.34934 1.682 0.0927 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.415 on 2639 degrees of freedom
Multiple R-squared: 0.1759, Adjusted R-squared: 0.1746
F-statistic: 140.8 on 4 and 2639 DF, p-value: < 2.2e-16
>
> M2 <- lm(GSI ~ factor(Sex)+factor(Location),data = Squid)
> summary(M2)
Call:
lm(formula = GSI ~ factor(Sex) + factor(Location), data = Squid)
Residuals:
Min 1Q Median 3Q Max
-3.4137 -1.3195 -0.1593 1.2039 11.2159
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.35926 0.07068 19.230 <2e-16 ***
factor(Sex)2 2.02481 0.09427 21.479 <2e-16 ***
factor(Location)2 -1.85525 0.20027 -9.264 <2e-16 ***
factor(Location)3 -0.14248 0.12657 -1.126 0.2604
factor(Location)4 0.58756 0.34934 1.682 0.0927 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.415 on 2639 degrees of freedom
Multiple R-squared: 0.1759, Adjusted R-squared: 0.1746
F-statistic: 140.8 on 4 and 2639 DF, p-value: < 2.2e-16
>
> Squid$fLocation
[1] 1 3 1 1 1 1 1 3 3 1 1 1 1 1 1 1 3 1 3 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 3 1 1 1 1 3 1 1 3 1 1 1 1 1 1 1 3 1 1 1 1 1 3 1 1 1 1 1 1 1 1
........
[2626] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Levels: 1 2 3 4
> Squid$fLocation <- factor(Squid$Location,levels= c(2,3,1,4))
> Squid$fLocation
[1] 1 3 1 1 1 1 1 3 3 1 1 1 1 1 1 1 3 1 3 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 3 1 1 1 1 3 1 1 3 1 1 1 1 1 1 1 3 1 1 1 1 1 3 1 1 1 1 1 1 1 1
[71] 1 1 1 1 1 3 1 1 3 1 1 3 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 3 1 3 3 3 1 3 1
...
] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Levels: 2 3 1 4boxplot(GSI ~ fLocation,data = Squid)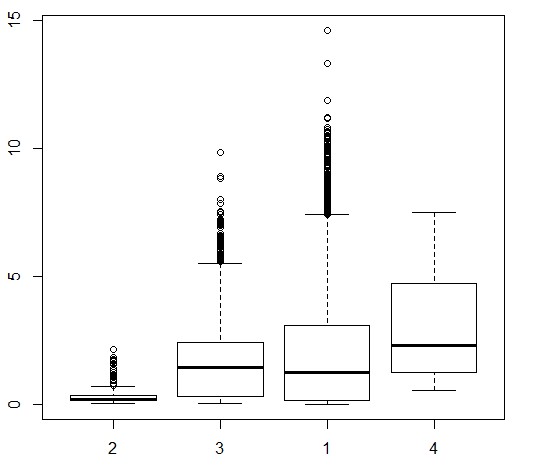
注意:
SquidM <- Squid[Squid$Sex == 1,]
SquidM <- Squid[Squid$fSex == "1"]但是1有双引号是必须的,因为fSex是因子
定义新的变量之后也可以通过str命令查看
> Squid$fSex <- factor(Squid$Sex,labels = c("M","F"))
> Squid$fLocation <- factor(Squid$Location)
> str(Squid)
'data.frame': 2644 obs. of 8 variables:
$ Sample : int 1 2 3 4 5 6 7 8 9 10 ...
$ Year : int 1 1 1 1 1 1 1 1 1 1 ...
$ Month : int 1 1 1 1 1 1 1 1 1 2 ...
$ Location : int 1 3 1 1 1 1 1 3 3 1 ...
$ Sex : int 2 2 2 2 2 2 2 2 2 2 ...
$ GSI : num 10.44 9.83 9.74 9.31 8.99 ...
$ fLocation: Factor w/ 4 levels "1","2","3","4": 1 3 1 1 1 1 1 3 3 1 ...
$ fSex : Factor w/ 2 levels "M","F": 2 2 2 2 2 2 2 2 2 2 ...
>第三章总结:
write.table 把一个变量写入到ascii文件中 write.table(Squid,file="test.txt")
order 确定数据的排序 order(x)
merge 合并两个数据框 merege(a,b,by="ID")
str 显示一个对象的内部结构 str(Squid)
factor 定义变量作为因子 factor(x)















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









