







流的重要性
针对Node.js平台来说, I/O的操作必须是实时的. 针对Stream来说, 只要数据有效则即可进行传输, 而非等到数据全部到达.
空间性能
Node.js默认最多能缓存0x3FFFFFFF字节(稍微小于1GB). 考虑我们将一个文件压缩:
var fs = require('fs');
var zlib = require('zlib');
var file = process.argv[2];
fs.readFile(file, (err, buffer) => {
zlib.gzip(buffer, (err, buffer) => {
fs.writeFile(file + '.gz', buffer, (err) => {
console.log('File successfully compressed');
});
});
});如果我们压缩一个大于1GB的文件, 则会报错:
RangeError: File size is greater than possible Buffer: 0x3FFFFFFF bytes但是, 如果使用流做处理, 则不存在此问题:
var fs = require('fs');
var zlib = require('zlib');
var file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(file + '.gz'))
.on('finish', function() {
console.log('File successfully compressed');
});使用pipe一个重大的优势是: 可组合.
备注: 在Node.js版本7.1.0中, 我使用了1.74G的视频文件进行测试, 结果依旧压缩成功, 并不存在最大缓冲区的问题.
时间性能
考虑一个实际例子: 我们从客户端将文件压缩往服务端发送文件, 服务端解压后存储为同名文件.
服务端gzipReceive.js:
var http = require('http');
var fs = require('fs');
var zlib = require('zlib');
var server = http.createServer((req, res) => {
var filename = req.headers.filename;
console.log('File request received: ' + filename);
req.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => {
res.writeHead(201, {'Content-Type': 'text/plain'});
res.end('That\'s it\n');
console.log('File saved: ' + filename);
});
});
server.listen(3000, () => {
console.log('Listening');
});客户端gzipSend.js:
var fs = require('fs');
var zlib = require('zlib');
var http = require('http');
var path = require('path');
var file = process.argv[2];
var server = process.argv[3];
var options = {
hostname: server,
port: 3000,
path: '/',
method: 'PUT',
headers: {
filename: path.basename(file),
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip'
}
};
var req = http.request(options, (res) => {
console.log('Server response: ' + res.statusCode);
});
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(req)
.on('finish', () => {
console.log('File successfully sent');
});服务端运行:
leicj@leicj:~/test$ node gzipReceive.js
Listening
File request received: test.txt
File saved: test.txt客户端运行:
leicj@leicj:~/test$ node gzipSend.js ./file/test.txt localhost
File successfully sent
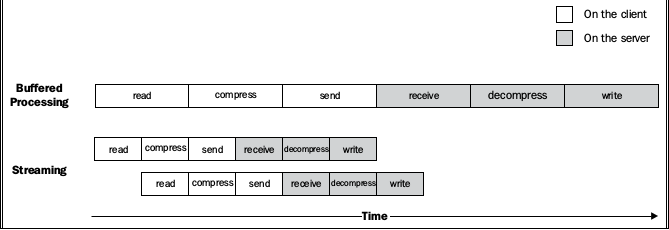
Server response: 201考虑如果使用Buffer来传递文件, 那么必须得等文件全部读取完毕才进行传输, 而stream则可做到边读取边传输, 如下图所示:
流入门
Readable streams
读取流有两种基本的模式: non-flowing和flowing.
non-flowing模式
non-flowing最基本的就是读取特定字节的数据: readable.read([size])
process.stdin.on('readable', () => {
var chunk;
console.log('New data available');
while ((chunk = process.stdin.read(200)) !== null) {
console.log('Chunk read: (' + chunk.length + ')"' + chunk.toString() + '"');
}
})
.on('end', () => {
process.stdout.write('End of stream\n');
});运行程序, 输出:
leicj@leicj:~/test$ cat test.js | node test.js
New data available
Chunk read: (200)"process.stdin.on('readable', () => {
var chunk;
console.log('New data available');
while ((chunk = process.stdin.read(200)) !== null) {
console.log('Chunk read: (' + chunk.length + ')"' + ch"
New data available
Chunk read: (95)"unk.toString() + '"');
}
})
.on('end', () => {
process.stdout.write('End of stream\n');
});"
End of streamflow模式
flow模式最基本在于监听data来获取数据:
process.stdin.on('data', (chunk) => {
console.log('New data available');
console.log('Chunk read: (' + chunk.length + ')"' + chunk.toString() + '"');
})
.on('end', () => {
process.stdout.write('End of stream\n');
});运行程序, 输出:
leicj@leicj:~/test$ cat test.js | node test.js
New data available
Chunk read: (222)"process.stdin.on('data', (chunk) => {
console.log('New data available');
console.log('Chunk read: (' + chunk.length + ')"' + chunk.toString() + '"');
})
.on('end', () => {
process.stdout.write('End of stream\n');
});"
End of stream实现一个Readable stream
var Readable = require('stream').Readable;
class MyReadable extends Readable {
constructor(options) {
super(options);
}
_read(size) {
this.push('hello');
this.push(null);
}
}
var myReadable = new MyReadable();
myReadable.pipe(process.stdout);
Writable streams
Writable streams中用于写入的函数格式为:
writable.write(chunk, [encoding], [callback]);而如果没有数据可写入, 则调用:
writable.end([chunk], [encoding], [callback]);实现一个Writable streams:
var Writable = require('stream').Writable;
class MyWritable extends Writable {
constructor(options) {
super(options);
}
_write(chunk, encoding, callback) {
process.stdout.write('output: ' + chunk.toString());
callback();
}
}
var myWritable = new MyWritable();
process.stdin.pipe(myWritable);
Duplex streams
var Duplex = require('stream').Duplex;
class MyDuplex extends Duplex {
constructor(options) {
super(options);
this.waiting = false;
}
_read(size) {
if (!this.waiting) {
this.push('Feed me data! >');
this.waiting = true;
}
}
_write(chunk, encoding, cb) {
this.waiting = false;
this.push(chunk);
cb();
}
}
var myDuplex = new MyDuplex();
process.stdin.pipe(myDuplex).pipe(process.stdout);Transform streams
var Transform = require('stream').Transform;
class MyTransform extends Transform {
constructor(options) {
super(options);
}
_transform(data, encoding, callback) {
this.push('output:' + data);
callback();
}
}
var myTransform = new MyTransform();
process.stdin.pipe(myTransform).pipe(process.stdout);
使用流进行异步控制
Sequential execution
在编写类似Writable/Duplex/Transform的情况下, _transform需要执行callback才能继续下去, 这样可以保证所处理的流是顺序的.
下例为顺序读取多个文件, 写入到目标文件中:
var fs = require('fs');
function concatFile(desc, files, cb) {
if (files.length === 0) return cb();
var input = fs.createReadStream(files[0]);
var output = fs.createWriteStream(desc, {flags: 'a'});
input.pipe(output);
output.on('finish', (err) => {
if (err) return console.error(err);
concatFile(desc, files.slice(1), cb);
});
}
var desc = process.argv[2];
var files = process.argv.slice(3);
concatFile(desc, files, () => {
console.log('File concatenated successfully');
});
Unordered parallel execution
考虑如下特殊的情况, 我们读取多个文件, 并且输出, 但我们并不考虑其顺序问题:
var fs = require('fs');
var files = process.argv.slice(2);
files.forEach((item) => {
fs.createReadStream(item).pipe(process.stdout);
});如果测试的文件过小, 则还是顺序输出. 当文件过大时候, 会发现多个文件混合输出到终端.
Unordered limited parallel execution
Piping模式
Combining streams
Forking streams
Merging streams
Multiplexing and demultiplexing















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









