







当有大量的候选变量中选择最终的预测变量,有以下两种流行方法
- 逐步回归法(stepwise method)
a、向前逐步回归(forward stepwise regression):每次添加一个预测变量到模型中,知道添加不会使模型有所改进为止
b、向后逐步回归(back setpwise regression):从模型中所有的预测变量开始,每次逐步删除一个变量直到会减低模型质量为止
c、向前向后逐步回归(stepwise stepwise regression,通常称作逐步回归):结合了向前向后逐步回归和向后逐步回归的方法,变量每次进入一个,但是每一步中,变量都会被重新评价,对模型没有贡献的变量将会被删除,预测变量可能会被添加、删除好几次,直到获得最优模型为止
- stepAIC()
MASS包中的stepAIC()可以实现逐步回归(向前、向后、向前向后),根据AIC值判断,越小模型越优
> library(MASS)
> states <- as.data.frame(state.x77[,c("Murder", "Population",
+ "Illiteracy", "Income", "Frost")])
> fit <- lm(Murder ~ Population + Illiteracy + Income + Frost,
+ data=states)
> stepAIC(fit,direction = "backward") #direction = "backward"向后回归
Start: AIC=97.75 #这里的AIC值代表仅接在后面的模型的AIC值
Murder ~ Population + Illiteracy + Income + Frost
Df Sum of Sq RSS AIC
- Frost 1 0.021 289.19 95.753
- Income 1 0.057 289.22 95.759
<none> 289.17 97.749
- Population 1 39.238 328.41 102.111
- Illiteracy 1 144.264 433.43 115.986
Step: AIC=95.75
Murder ~ Population + Illiteracy + Income
Df Sum of Sq RSS AIC
- Income 1 0.057 289.25 93.763
<none> 289.19 95.753
- Population 1 43.658 332.85 100.783
- Illiteracy 1 236.196 525.38 123.605
Step: AIC=93.76
Murder ~ Population + Illiteracy
Df Sum of Sq RSS AIC
<none> 289.25 93.763
- Population 1 48.517 337.76 99.516
- Illiteracy 1 299.646 588.89 127.311
Call:
lm(formula = Murder ~ Population + Illiteracy, data = states)
Coefficients:
(Intercept) Population Illiteracy
1.6515497 0.0002242 4.0807366
#过程是逐步的删除变量,直到最小的AIC值
- 逐步回归的局限性
可以找到 一个好的模型,但是不能保证模型是最佳模型,因为不是每一个可能的模型都被评价了,为此需要使用全子集回归
- 全子集回归
全子集回归就是指所有可能的模型都会被检验。分析员可以选择展示有可能的结果,也可以展示不同 n 个不同子集大小(一个、两个或多个预测变量)的最佳模型。例如,若nbest = 2,先展示两个最佳的单预测变量模型,然后展示两个最佳的双预测变量模型,以此类推,直到包含所有的预测变量
全子集回归可用 leaps包中regsubets()函数 来实现。通过 R 平方,调整的 R平方或 Mallows Cp统计量等准则来选择“最佳”模型。
通过调整 R^2或者调整R^2来获选择最佳模型
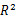 介绍
介绍
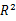 含义与预测变量与解释响应变量的程度,调整
含义与预测变量与解释响应变量的程度,调整 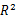 与之类似,但考虑了模型的参数数目,
与之类似,但考虑了模型的参数数目, 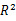 总会随着变量数目的增加而增加,当与样本量相比 ,预测变量数目很大时,容易导致过拟合 ,
总会随着变量数目的增加而增加,当与样本量相比 ,预测变量数目很大时,容易导致过拟合 , 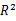 很可能会丢失数据的偶然变异信息,而调整
很可能会丢失数据的偶然变异信息,而调整  则提供了更为真实的
则提供了更为真实的  平方估计 。
平方估计 。
另外,Mallows Cp 统计量也用来作为逐步回归的判停规则,广泛研究表明,对于一个好的模型,它的 Cp 统计量非常接近于模型的参数数目(包括截距项)
#如下图
> library(leaps)
> states <- as.data.frame(state.x77[,c("Murder", "Population",
+ "Illiteracy", "Income", "Frost")])
> leaps <-regsubsets(Murder ~ Population + Illiteracy + Income +
+ Frost, data=states, nbest=4) #nbest =4
> plot(leaps, scale="adjr2")
第一行中(图底部开始),可以看到含intercept(截距项)和Income的模型调整R平方为0.33,含intercept和POpulation的模型调整R平方为0.1。调至第12行,你会看到intercetpt、Popilation、Illiteracy和Income的模型调整R平方值为0.54,而仅含intercept、Population和Illiteracy的模型调整R平方为0.55。此处你会发现含预测变量越少模型调整R平方越大(对与非调整的R平方,这是不可能的)。图形表明,双预测变量模型(Population和Illiterracy)是最佳模型。
- Mallows Cp统计量
Mallows Cp统计量也用来作为逐步回归的判停规则,对于一个好的模型,它的Cp统计量非常接近于模型的参数数目(包括截距项)
使用leaps包中的plot()绘制函数,或者用car包中的subsets()函数绘制
#Mallows Cp统计量,如下图
library(car)
subsets(leaps,statistic = "cp",
main ="Cp Plot for All Subsets Regressionn")
abline(1,1,lty=2,col="red")
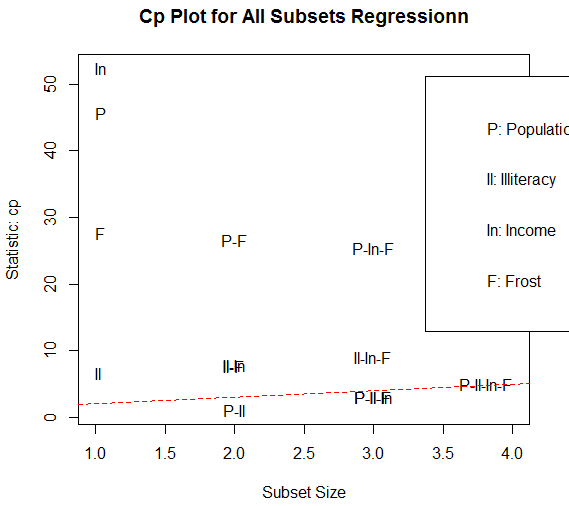
越好的模型离截项和斜率为1的直线越近,图形表明,你可以选择这几个模型,其余的模型可以不考虑,含Population和Illiteracy的双变量模型,含Population、Illiterary和Frost的三变量模型(它们在图形上重叠了,不易分别),含 Population、Illiteracy、Income和Frost的四变量模型
大部分情况中,全子集回归要优于逐步回归,因为考虑了跟过的模型,但当有大量预测变量时,全子集回归会很慢。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









