






日常的写在前面
难得的周末,有大段的时间可以用来学习,体验就和工作日的晚上完全不一样了。
好好的沉下心学习下~
即刻很喜欢了!
好好学习的分割线
打打打鸡血!!!!!!
面向对象高级编程
前天的定制类的__call__通过小佳扬的一语惊醒梦中人,就是把对象函数化了。
感觉有点囫囵吞枣,看完教程后要还好好地归纳下。
枚举类
定义常量时候使用,例如定义月份。
JAN = 1
FEB = 2
MAR = 3
...
NOV = 11
DEC = 12
但是此时的类型是int。
通过Python提供的Enum类来实现为枚举类型定义一个class类型。
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
这样就获得了Month类型的枚举类,可以使用Month.Jan来引用一个常量,或者枚举成员。
for name, member in Month.__members__.items():
print(name, '=>', member, ',', member.value)

value属性是自动赋给成员的值,默认从1开始计数。
如果需要更精确地控制枚举类型,可以从Enum派生出自定义类。
from enum import Enum, unique
@unique
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
@unique装饰器可以帮助我们检查保证没有重复值。
使用元类
type()
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的。
type()函数可以查看类型或者变量的类型,class的类型就是type。
而且type()函数既可以返回一个对象的类型,又可以创建出新的类型。
#用type()函数创造出hello类
def fn(self, name='world'): # 先定义函数
print('Hello, %s.' % name)
Hello = type('Hello', (object,), dict(hello=fn))
用type()创建类,需要依次传入三个参数:
class的名称;
继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上
这样和直接定义class的写法没有差异,但是这样的话就可以在代码运行的过程中,动态创建类,这和静态语言有很大不同。
metaclass
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用metaclass。
先定义metaclass,就可以创建类,最后创建实例。
据说很难理解的魔术代码,还是认真的努力理解下吧!
看下大牛的代码!
这个metaclass可以给我们自定义的MyList增加一个add方法:
定义ListMetaclass,按照默认习惯,metaclass的类名总是以Metaclass结尾,以便清楚地表示这是一个metaclass。
# metaclass是类的模板,所以必须从`type`类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
有了ListMetaclass,我们在定义类的时候还要指示使用ListMetaclass来定制类,传入关键字参数metaclass:
class MyList(list, metaclass=ListMetaclass):
pass
这样MyList创建的时候,需要通过ListMetaclass.__new__()来创建。
__new__()方法接收到的参数依次是:
当前准备创建的类的对象;
类的名字;
类集成的父类集合;
类的方法集合。
而MyList()可以调用add方法,但普通list()就没有。
list即类的对象。
这个复杂的有点变态的定义方式,在一些场景下,例如ORM的编写中,会很有用。
ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
这块有点复杂,虽然看懂了,但是还要好好琢磨下
错误、调试和测试
错误处理
高级语言都内置了一套try...except...finally...的错误处理机制,Python小可爱也有。
try
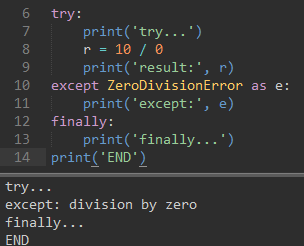
当有错误时候,会打断代码的进行,跳转到except处,一旦有finally的话就一定会执行,无论有没有发生错误。
可以有多个except获取不同的错误,但是注意父类和子类的问题,如果一旦包括了父类错误,子类所在的except就不会被执行。
except后也可以加else语句,当没有错误发生的时候,会执行else语句。
Python所有的错误都是从BaseException类派生的,常见的错误类型和继承关系有这些:
https://docs.python.org/3/lib...
也就是说,不需要在每个可能出错的地方去捕获错误,只要在合适的层次去捕获错误就可以了。这样一来,就大大减少了写try...except...finally的麻烦。
调用栈
如果错误没有被捕获,它就会一直往上抛,最后被Python解释器捕获,打印一个错误信息,然后程序退出。
所以找错误栈的时候,一定要找到准确的最里面那层。
错误记录
等Python解释器打印错误栈的信息,程序也结束了。
既然可以捕获,就在捕获的同时打印错误信息并分析原因,让程序继续下去。
Python内置的logging可以很容易的记录错误信息。
# err_logging.py
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()
print('END')
这样打印完错误信息后还会打印END,即运行了后续的代码。
将logging通过配置记录到日志文件中方便后续的排查。
抛出错误
捕获的错误其实是错误class的一个实例,错误也是需要定以后才能抛出然后被捕获到的。
如果要抛出错误,首先根据需要,可以定义一个错误的class,选择好继承关系,然后,用raise语句抛出一个错误的实例.
# err_raise.py
class FooError(ValueError):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s)
return 10 / n
foo('0')
另一种抛出错误的例子如下。
# err_reraise.py
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise #错误又被抛出
bar()
这种方式也很常见,在抛出问题后继续抛回上一级,由顶曾调用者进行处理。
raise语句如果不带参数,就会把当前错误原样抛出。
此外,在except中raise一个Error,还可以把一种类型的错误转化成另一种类型。
调试
用print()打印有问题的变量
麻烦在还得删掉或注释掉相应语句
断言
凡是可以用print打印的地方,都可以用asset断言来代替。
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'#判断此处n!=0是否为True,如果非则抛出AssertionError
return 10 / n
def main():
foo('0')
可以在启动Python解释器的时候关闭assert
$python -0
logging
同样是替换print,logging不会抛出错误,而且可以输出到文件。
import logging
logging.basicConfig(level=logging.INFO)
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
这就是logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
pdb
启动Python的调试器pdb,让程序以单步方式运行。
pdb.set_trace()
这个方法也是用pdb,但是不需要单步执行,我们只需要import pdb,然后,在可能出错的地方放一个pdb.set_trace(),就可以设置一个断点















 6546
6546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









