






一,一维高斯分布
N(μ,δ2)
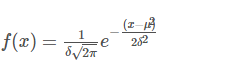
二,多维高斯分布
二维高斯分布,这时的随机变量组成了随机向量:v=[x,y]T。
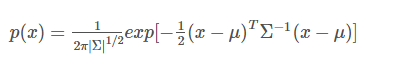
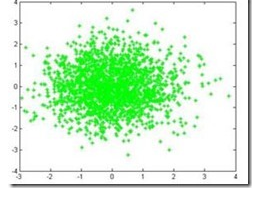 图2.1
图2.1 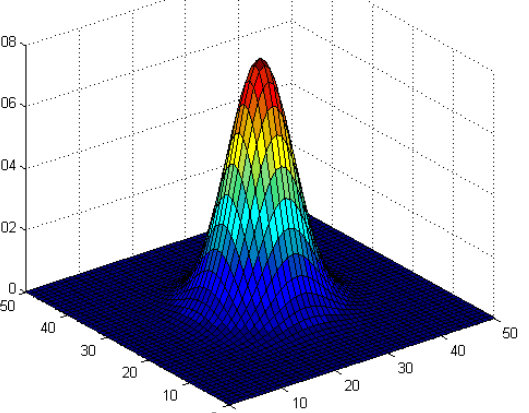 图2.2
图2.2
注意:这两种图的区别。2.1图是二维高斯分布的各采样点的分布,这些点是二维分布的高斯点,通过点的疏密才能看出分布概率的大小。2.2图是二维高斯分布点和点的概率分布图,通过高度就可以看出分布在各点的概率分布,但是这个图也是二维高斯分布的描述。所以说,符合SGM分布的二维点在平面上应该近似椭圆;相应地,三维点在空间中则近似于椭球状。这里说的点是采样点。
多维高斯分布:
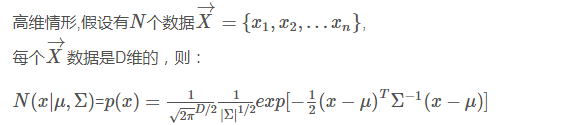
三,混合高斯分布(GMM)
引入原因: 高斯混合模型是单一高斯概率率密度函数的延伸。例如:有一批观察数据![]() ,数据个数为n,在d 维空间中的分布不是椭球状,那么就不适合以一个单一的高密度函数来描述这些数据点的概率密度函数。
,数据个数为n,在d 维空间中的分布不是椭球状,那么就不适合以一个单一的高密度函数来描述这些数据点的概率密度函数。
此时我们采用一个变通方案,假设每个点均由一个单高斯分布生成,而这一批数据共由M(明确)个单高斯模型生成,具体某个数据![]() 属于哪个单高斯模型未知,且每个单高斯模型在混合模型中占的比例
属于哪个单高斯模型未知,且每个单高斯模型在混合模型中占的比例![]() 未知,将所有来自不同分布的数据点混在一起,该分布称为高斯混合分布。
未知,将所有来自不同分布的数据点混在一起,该分布称为高斯混合分布。
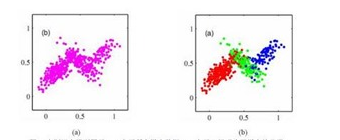
(a)图可以看出,数据点的分布不成一个椭圆形状,我们把这些分布看成是由多个椭圆构成。
我 的理解是:在统计学中,我们总是把大量数据的分布都看成是高斯分布,神经网络课上老师说,在数据处理中,我们把数据都看成是高斯(正态)分布,因为大部分随机变量(数据或者噪声)都是正态分布的,就算不是正态分布的,当量足够大时,我们也能把它转换成正态分布的(中心极限定理)。当我们的观察数据不成椭圆形分布时,我们不能简单地将数据点的概率分布转换成高斯分布,应该转换混合高斯分布。
统计学习的模型有两种,一种是概率模型,一种是非概率模型。
所谓概率模型,是指训练模型的形式是P(Y|X)P(Y|X)。输入是XX,输出是YY,训练后模型得到的输出不是一个具体的值,而是一系列的概率值(对应于分类问题来说,就是输入XX对应于各个不同YY(类)的概率),然后我们选取概率最大的那个类作为判决对象(软分类–soft assignment)。所谓非概率模型,是指训练模型是一个决策函数Y=f(X)Y=f(X),输入数据X是多少就可以投影得到唯一的YY,即判决结果(硬分类–hard assignment)。
所谓混合高斯模型(GMM)就是指对样本的概率密度分布进行估计,而估计采用的模型(训练模型)是几个高斯模型的加权和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
从中心极限定理的角度上看,把混合模型假设为高斯的是比较合理的,当然,也可以根据实际数据定义成任何分布的Mixture Model,不过定义为高斯的在计算上有一些方便之处,另外,理论上可以通过增加Model的个数,用GMM近似任何概率分布。
混合高斯模型的定义为:
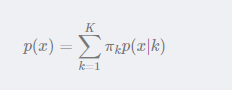
其中K为模型的个数;πk为第k个高斯的权重;p(x|k)则为第kk个高斯概率密度,其均值为μk,方差为δk。对此概率密度的估计就是要求出πk、μk和δk各个变量。当求出p(x)的表达式后,求和式的各项的结果就分别代表样本x属于各个类的概率。
参考:https://blog.csdn.net/lzrtutu/article/details/77783081
https://www.cnblogs.com/AndyJee/p/3732766.html















 6960
6960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









