






执行文件拷贝操作

拷贝后的“input”文件夹的内容如下所示:

和我们的hadoop安装目录下的“conf”文件的内容是一样的。
现在,在我们刚刚构建的伪分布式模式下运行wordcount程序:
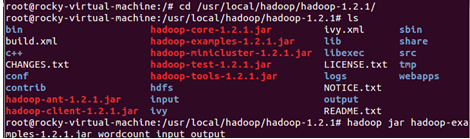
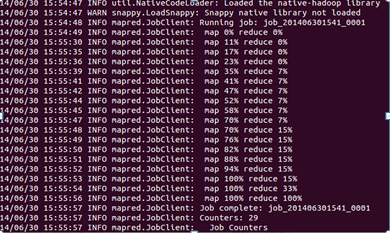
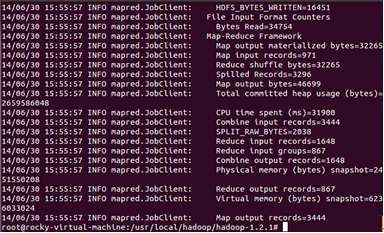
运行完成后我们查看一下输出的结果:

部分统计结果如下:

此时我们到达Hadoop的web控制台会发现我们提交并成功的运行了任务:
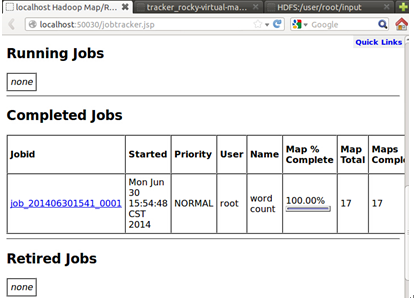
最后在Hadoop执行完任务后,可以关闭Hadoop后台服务:

至此,Hadoop伪分布式环境的搭建和测试你完全成功!
至此,我们彻底完成了实验。

执行文件拷贝操作
拷贝后的“input”文件夹的内容如下所示:
和我们的hadoop安装目录下的“conf”文件的内容是一样的。
现在,在我们刚刚构建的伪分布式模式下运行wordcount程序:
运行完成后我们查看一下输出的结果:
部分统计结果如下:
此时我们到达Hadoop的web控制台会发现我们提交并成功的运行了任务:
最后在Hadoop执行完任务后,可以关闭Hadoop后台服务:
至此,Hadoop伪分布式环境的搭建和测试你完全成功!
至此,我们彻底完成了实验。
转载于:https://my.oschina.net/u/1791057/blog/307093
 635
1306
114
759
635
1306
114
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























