







1: Clustering NBA Players
In NBA media coverage(媒体报导), sports reporters usually focus on a handful of players and paint stories of how unique these players' stats are. With our data science hats on, we can't help but feel a slight sense of skepticism to how different the players are from one another. Let's see how we can use data science to explore that thread further.
Let's look at the dataset of player performance from the 2013-2014 season.
Here are some selected columns:
player-- name of the playerpos-- the position of the playerg-- number of games the player was inpts-- total points the player scoredfg.-- field goal percentageft.-- free throw percentage
Check out Database Basketball for an explanation of all the columns
Instructions
This step is a demo. Play around with code or advance to the next step.
import pandas as pd
import numpy as np
nba = pd.read_csv("nba_2013.csv")
nba.head(3)
2: Point Guards
Point guards play one of the most crucial roles on a team because their primary responsibility is to create scoring opportunities for the team. We are going to focus our lesson on a machine learning technique called clustering, which allows us to visualize the types of point guards as well as group similar point guards together. Using 2 features allows us to easily visualize the players and will also make it easier to grasp how clustering works. For point guards, it's widely accepted that the Assist to Turnover Ratio is a good indicator for performance in games as it quantifies the number of scoring opportunities that player created. Let's also use Points Per Game, since effective Point Guards not only set up scoring opportunities but also take a lot of the shots themselves.
Instructions
- Create a new Dataframe which contains just the point guards from the data set.
- Point guards are specified as
PGin theposcolumn. - Assign the filtered data frame to
point_guards.
- Point guards are specified as
# Enter code here.
point_guards=nba[nba["pos"]=="PG"]
3: Points Per Game
While our dataset doesn't come with Points Per Game values, we can easily calculate those using each player's total points (pts) and the number of games (g) they played. Let's take advantage of pandas' ability to multiply and divide columns to create the Points Per Gameppg column by dividing the pts and g columns.
Instructions
This step is a demo. Play around with code or advance to the next step.
point_guards['ppg'] = point_guards['pts'] / point_guards['g']
# Sanity check, make sure ppg = pts/g
point_guards[['pts', 'g', 'ppg']].head(5)
4: Assist Turnover Ratio
Now let's create a column, atr, for the Assist Turnover Ratio, which is calculated by dividing total assists (ast) by total turnovers (tov):
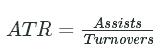
Instructions
- Drop the players who have 0 turnovers.
- Not only did these players only play a few games, making it hard to understand their true abilities, but we also cannot divide by 0 when we calculate
atr.
- Not only did these players only play a few games, making it hard to understand their true abilities, but we also cannot divide by 0 when we calculate
- Utilize the same division technique we used with Points Per Game to create the Assist Turnover Ratio (
ast) column forpoint_guards.
point_guards = point_guards[point_guards['tov'] != 0]
point_guards["atr"]=point_guards["ast"]/point_guards["tov"]
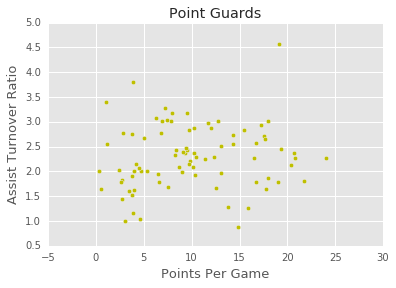
5: Visualizing The Point Guards
Use matplotlib to create a scatter plot with Points Per Game (ppg) on the X axis and Assist Turnover Ratio (atr) on the Y axis.
Instructions
This step is a demo. Play around with code or advance to the next step.
plt.scatter(point_guards['ppg'], point_guards['atr'], c='y')
plt.title("Point Guards")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
6: Clustering Players
There seem to be 5 general regions, or clusters, that the point guards fall into (with a few outliers of course!). We can use a technique called clustering to segment all of the point guards into groups of alike players. While regression and other supervised machine learningtechniques work well when we have a clear metric we want to optimize for and lots of pre-labelled data, we need to instead useunsupervised machine learning techniques to explore the structure within a data set that doesn't have a clear value to optimize.
There are multiple ways of clustering data but here we will focus on centroid based clustering for this lesson. Centroid based clustering works well when the clusters resemble circles with centers (or centroids). The centroid represent the arithmetic mean of all of the data points in that cluster.
K-Means Clustering is a popular centroid-based clustering algorithm that we will use. The K in K-Means refers to the number of clusters we want to segment our data into. The key part with K-Means (and most unsupervised machine learning techniques) is that we have to specify what k is. There are advantages and disadvantages to this, but one advantage is that we can pick the k that makes the most sense for our use case. We'll set k to 5 since we want K-Means to segment our data into 5 clusters.
7: The Algorithm
Setup K-Means is an iterative algorithm that switches between recalculating the centroid of each cluster and the players that belong to that cluster. To start, select 5 players at random and assign their coordinates as the initial centroids of the just created clusters.
Step 1 (Assign Points to Clusters) For each player, calculate the Euclidean distance between that player's coordinates, or values for atr &ppg, and each of the centroids' coordinates. Assign the player to the cluster whose centroid is the closest to, or has the lowest Euclidean distance to, the player's values.
Step 2 (Update New Centroids of the Clusters) For each cluster, compute the new centroid by calculating the arithmetic mean of all of the points (players) in that cluster. We calculate the arithmetic mean by taking the average of all of the X values (atr) and the average of all of the Y values (ppg) of the points in that cluster.
Iterate Repeat steps 1 & 2 until the clusters are no longer moving and have converged.
Instructions
This step is a demo. Play around with code or advance to the next step.
num_clusters = 5
# Use numpy's random function to generate a list, length: num_clusters, of indices
random_initial_points = np.random.choice(point_guards.index, size=num_clusters)
# Use the random indices to create the centroids
centroids = point_guards.loc[random_initial_points]
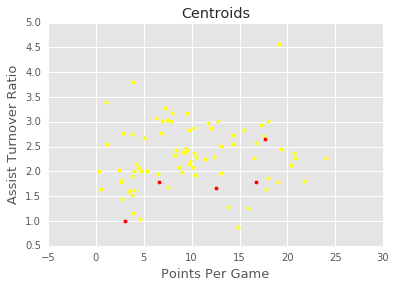
8: Visualize Centroids
Let's plot the centroids, in addition to the point_guards, so we can see where the randomly chosen centroids started out.
Instructions
This step is a demo. Play around with code or advance to the next step.
plt.scatter(point_guards['ppg'], point_guards['atr'], c='yellow')
plt.scatter(centroids['ppg'], centroids['atr'], c='red')
plt.title("Centroids")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
9: Setup (Continued)
While the centroids data frame object worked well for the initial centroids, where the centroids were just a subset of players, as we iterate the centroids' values will be coordinates that may not match another player's coordinates. Moving forward, let's use a dictionary object instead to represent the centroids.
We will need a unique identifier, like cluster_id, to refer to each cluster's centroid and a list representation of the centroid's coordinates (or values for ppg and atr). Let's create a dictionary then with the following mapping:
- key:
cluster_idof that centroid's cluster - value: centroid's coordinates expressed as a list (
ppgvalue first,atrvalue second )
To generate the cluster_ids, let's iterate through each centroid and assign an integer from 0 to k-1. For example, the first centroid will have a cluster_id of 0, while the second one will have a cluster_id of 1. We'll write a function, centroids_to_dict, that takes in thecentroids data frame object, creates a cluster_id and converts the ppg and atr values for that centroid into a list of coordinates, and adds both the cluster_id and coordinates_list into the dictionary that's returned.
Instructions
This step is a demo. Play around with code or advance to the next step.
def centroids_to_dict(centroids):
dictionary = dict()
# iterating counter we use to generate a cluster_id
counter = 0
# iterate a pandas data frame row-wise using .iterrows()
for index, row in centroids.iterrows():
coordinates = [row['ppg'], row['atr']]
dictionary[counter] = coordinates
counter += 1
return dictionary
centroids_dict = centroids_to_dict(centroids)
10: Step 1 (Euclidean Distance)
Before we can assign players to clusters, we need a way to compare the ppg and atr values of the players with each cluster's centroids. Euclidean distance is the most common technique used in data science for measuring distance between vectors and works extremely well in 2 and 3 dimensions. While in higher dimensions, Euclidean distance can be misleading, in 2 dimensions Euclidean distance is essentially the Pythagorean theorem.
The formula is
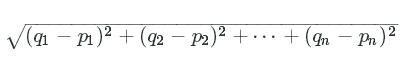
q and p are the 2 vectors we are comparing. If q is [5, 2] and p is [3, 1], the distance comes out to:
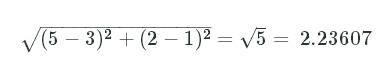
Let's create the function calculate_distance, which takes in 2 lists (the player's values for ppg and atr and the centroid's values forppg and atr).
Instructions
This step is a demo. Play around with code or advance to the next step.
import math
def calculate_distance(centroid, player_values):
root_distance = 0
for x in range(0, len(centroid)):
difference = centroid[x] - player_values[x]
squared_difference = difference**2
root_distance += squared_difference
euclid_distance = math.sqrt(root_distance)
return euclid_distance
q = [5, 2]
p = [3,1]
print(calculate_distance(q, p))
11: Step 1 (Continued)
Now we need a way to assign data points to clusters based on Euclidean distance. Instead of creating a new variable or data structure to house the clusters, let's keep things simple and just add a column to the point_guards data frame that contains the cluster_id of the cluster it belongs to.
Instructions
-
Create a function that can be applied to every row in the data set (using the
applyfunction inpandas).- For each player, we want to calculate the distances to each cluster's centroid using
euclidean_distance. - Once we know the distances, we can determine which centroid is the closest (has the lowest distance) and return that centroid's
cluster_id.
- For each player, we want to calculate the distances to each cluster's centroid using
-
Create a new column,
cluster, that contains the row-wise results ofassign_to_cluster.
# point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
def assign_to_cluster(row):
lowest_distance = -1
closest_cluster = -1
for cluster_id, centroid in centroids_dict.items():
df_row = [row['ppg'], row['atr']]
euclidean_distance = calculate_distance(centroid, df_row)
if lowest_distance == -1:
lowest_distance = euclidean_distance
closest_cluster = cluster_id
elif euclidean_distance < lowest_distance:
lowest_distance = euclidean_distance
closest_cluster = cluster_id
return closest_cluster
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
12: Visualizing Clusters
Let's write a function, visualize_clusters, that we can use to visualize the clusters easily.
Instructions
This step is a demo. Play around with code or advance to the next step.
# Visualizing clusters
def visualize_clusters(df, num_clusters):
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
for n in range(num_clusters):
clustered_df = df[df['cluster'] == n]
plt.scatter(clustered_df['ppg'], clustered_df['atr'], c=colors[n-1])
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
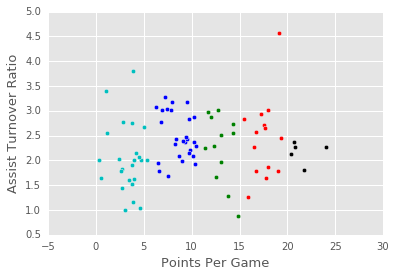
visualize_clusters(point_guards, 5)
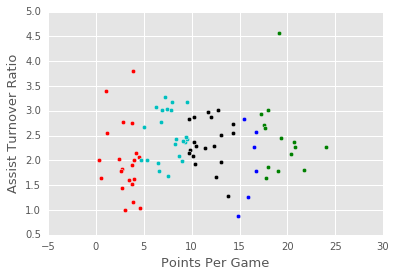
13: Step 2
How colorful! Now let's code Step 2, where we recalculate the centroids for each cluster.
Instructions
- Finish the function,
recalculate_centroids, that:- takes in
point_guards, - uses each
cluster_id(from0tonum_clusters - 1) to pull out all of the players in each cluster, - calculates the new arithmetic mean,
- and adds the
cluster_idand the new arithmetic mean tonew_centroids_dict, the final dictionary to be returned.
- takes in
def recalculate_centroids(df):
new_centroids_dict = dict()
# 0..1...2...3...4
for cluster_id in range(0, num_clusters):
# Finish the logic
return new_centroids_dict
centroids_dict = recalculate_centroids(point_guards)
def recalculate_centroids(df):
new_centroids_dict = dict()
for cluster_id in range(0, num_clusters):
values_in_cluster = df[df['cluster'] == cluster_id]
# Calculate new centroid using mean of values in the cluster
new_centroid = [np.average(values_in_cluster['ppg']), np.average(values_in_cluster['atr'])]
new_centroids_dict[cluster_id] = new_centroid
return new_centroids_dict
centroids_dict = recalculate_centroids(point_guards)
14: Repeat Step 1
Now that we recalculated the centroids, let's re-run Step 1 (assign_to_cluster) and see how the clusters shifted.
Instructions
This step is a demo. Play around with code or advance to the next step.
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
visualize_clusters(point_guards, num_clusters)
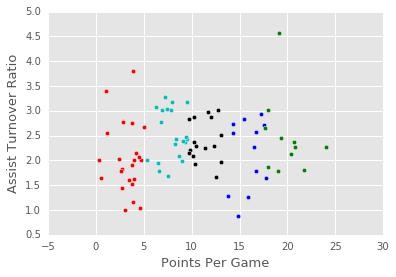
15: Repeat Step 2 And Step 1
Now we need to recalculate the centroids, and shift the clusters again.
Instructions
This step is a demo. Play around with code or advance to the next step.
centroids_dict = recalculate_centroids(point_guards)
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
visualize_clusters(point_guards, num_clusters)
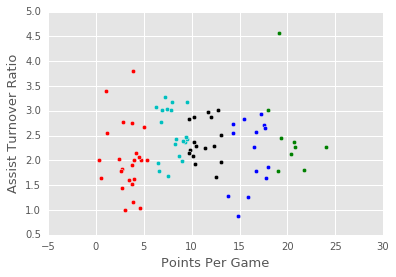
16: Challenges Of K-Means
As you repeat Steps 1 and 2 and run visualize_clusters, you'll notice that a few of the points are changing clusters between every iteration (especially in areas where 2 clusters almost overlap), but otherwise, the clusters visually look like they don't move a lot after every iteration. This means 2 things:
- K-Means doesn't cause massive changes in the makeup of clusters between iterations, meaning that it will always converge and become stable
- Because K-Means is conservative between iterations, where we pick the initial centroids and how we assign the players to clusters initially matters a lot
To counteract these problems, the sklearn implementation of K-Means does some intelligent things like re-running the entire clustering process lots of times with random initial centroids so the final results are a little less biased on one passthrough's initial centroids.
Instructions
This step is a demo. Play around with code or advance to the next step.
17: Conclusion
In this lesson, we explored how to segment NBA players into groups with similar traits. Our exploration helped us get a sense of the 5 types of point guards as based on each player's Assist Turnover Ratio and Points Per Game. In future lessons, we will explore how to cluster using many more features, as well as alternative ways of clustering data without using centroids.
We also got to experience the beauty of sklearn and the simplicity of using sophisticated models to get what we need accomplished quickly. In just a few lines, we ran and visualized the results of a robust K-means clustering implementation. When using K-means in the real world, use the sklearn implementation.















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









