






临时重定向,POST不会变成GET
400 Bad Request
请求报文语法错误或参数错误
401 Unauthorized
需要通过HTTP认证,或认证失败
403 Forbidden
请求资源被拒绝
404 Not Found
无法找到请求资源(服务器无理由拒绝)
500 Internal Server Error
服务器故障或Web应用故障
503 Service Unavailable
服务器超负载或停机维护
57、分别从前端、后端、数据库阐述web项目的性能优化
该题目网上有很多方法,我不想截图网上的长串文字,看的头疼,按我自己的理解说几点。
前端优化:
1、减少http请求、例如制作精灵图。
2、html和CSS放在页面上部,java放在页面下面,因为js加载比HTML和Css加载慢,所以要优先加载html和css,以防页面显示不全,性能差,也影响用户体验差。
后端优化:
1、缓存存储读写次数高,变化少的数据,比如网站首页的信息、商品的信息等。应用程序读取数据时,一般是先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存。
2、异步方式,如果有耗时操作,可以采用异步,比如celery。
3、代码优化,避免循环和判断次数太多,如果多个if else判断,优先判断最有可能先发生的情况。
数据库优化:
1、如有条件,数据可以存放于redis,读取速度快。
2、建立索引、外键等。
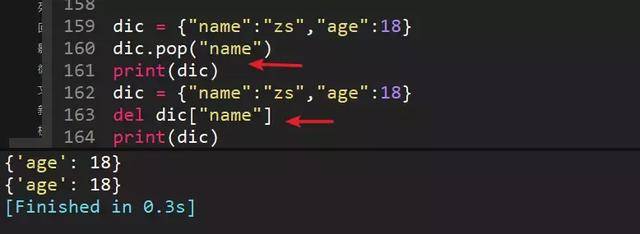
58、使用pop和del删除字典中的"name"字段,dic={"name":"zs","age":18}
59、列出常见MYSQL数据存储引擎
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。
MEMORY:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。
60、计算代码运行结果,zip函数历史文章已经说了,得出[("a",1),("b",2),("c",3), ("d",4), ("e",5)]
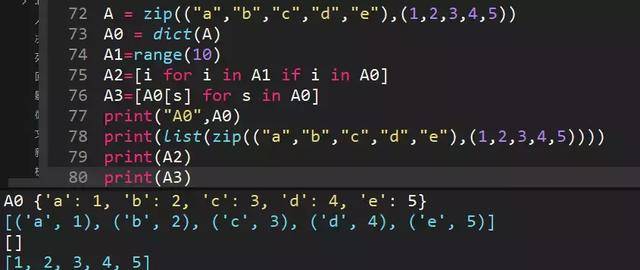
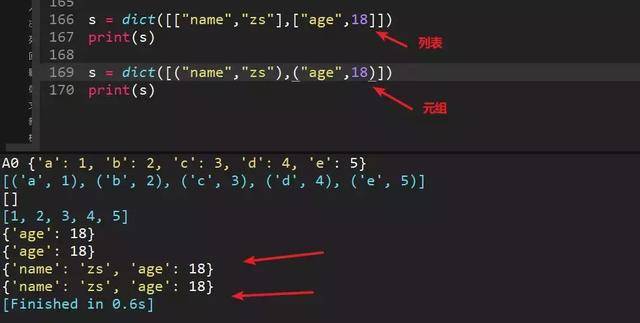
dict()创建字典新方法
61、简述同源策略
同源策略需要同时满足以下三点要求:
1)协议相同
2)域名相同
3)端口相同
http:www.test.com与https:www.test.com 不同源——协议不同
http:www.test.com与http:www.admin.com 不同源——域名不同
http:www.test.com与http:www.test.com:8081 不同源——端口不同
只要不满足其中任意一个要求,就不符合同源策略,就会出现“跨域”。
62、简述cookie和session的区别
1、session 在服务器端,cookie 在客户端(浏览器)。
2、session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效,存储Session时,键与Cookie中的sessionid相同,值是开发人员设置的键值对信息,进行了编码,过期时间由开发人员设置。
3、cookie安全性比session差。
63、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源。
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃。
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
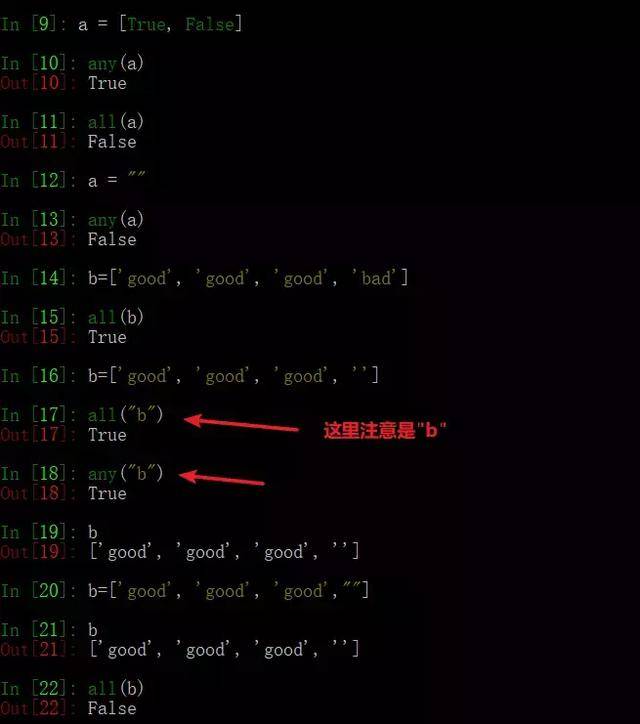
64、简述any()和all()方法
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
python中什么元素为假?
答案:(0,空字符串,空列表、空字典、空元组、None, False)
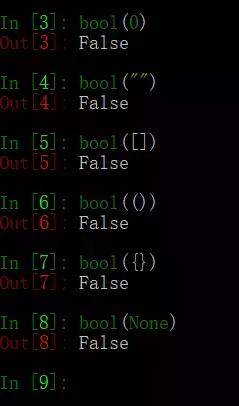
测试all()和any()方法
65、IOError、AttributeError、ImportError、Indentati、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
Indentati:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量
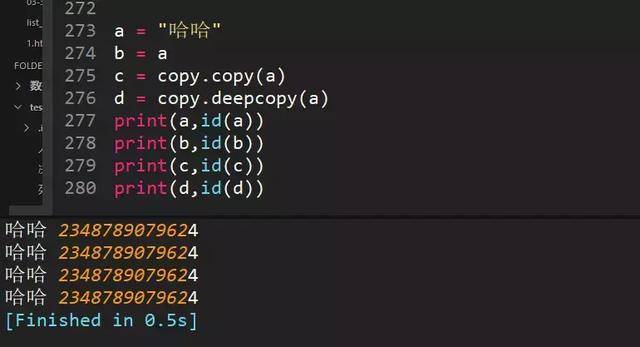
66、python中copy和deepcopy区别
1、复制不可变数据类型,不管copy还是deepcopy,都是同一个地址当浅复制的值是不可变对象(数值,字符串,元组)时和=“赋值”的情况一样,对象的id值与浅复制原来的值相同。
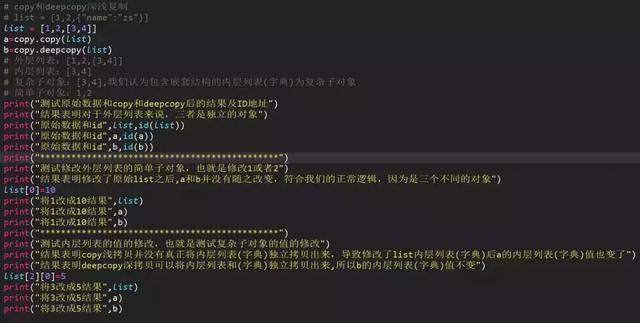
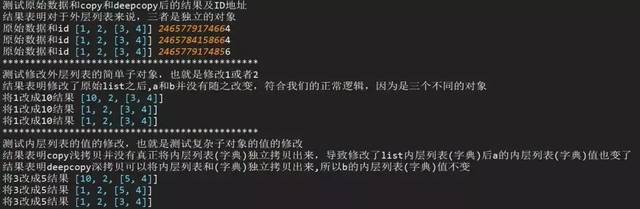
2、复制的值是可变对象(列表和字典)
浅拷贝copy有两种情况:
第一种情况:复制的 对象中无 复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有 复杂 子对象 (例如列表中的一个子元素是一个列表), 改变原来的值 中的复杂子对象的值 ,会影响浅复制的值。
深拷贝deepcopy:完全复制独立,包括内层列表和字典。
67、列出几种魔法方法并简要介绍用途
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
68、C:Users y-wu.junyaDesktop>python 1.py 22 33命令行启动程序并传参,print(sys.argv)会输出什么数据?
文件名和参数构成的列表

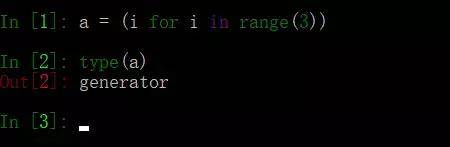
69、请将[i for i in range(3)]改成生成器
生成器是特殊的迭代器:
1、列表表达式的【】改为()即可变成生成器。
2、函数在返回值得时候出现yield就变成生成器,而不是函数了,
中括号换成小括号即可,有没有惊呆了
70、a = " hehheh ",去除收尾空格

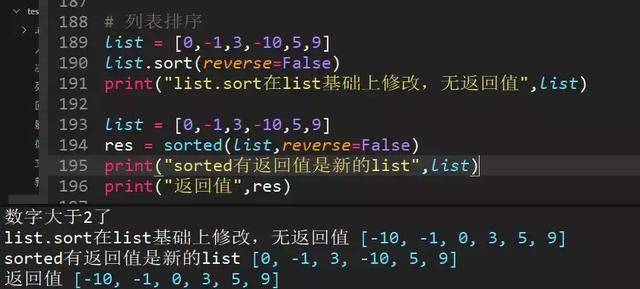
71、举例sort和sorted对列表排序,list=[0,-1,3,-10,5,9]
72、对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],使用lambda函数从小到大排序

73、使用lambda函数对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],输出结果为[0,2,4,8,8,9,-2,-4,-4,-5,-20],正数从小到大,负数从大到小】(传两个条件,x<0和abs(x))
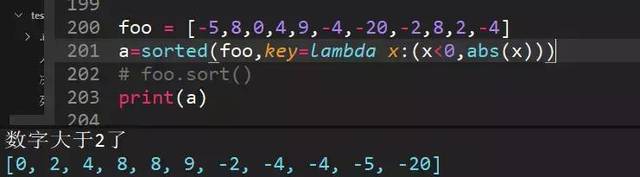
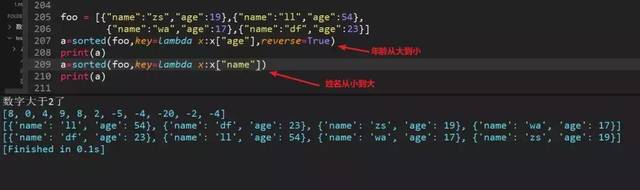
74、列表嵌套字典的排序,分别根据年龄和姓名排序
foo = [{"name":"zs","age":19},{"name":"ll","age":54},
{"name":"wa","age":17},{"name":"df","age":23}]
75、列表嵌套元组,分别按字母和数字排序
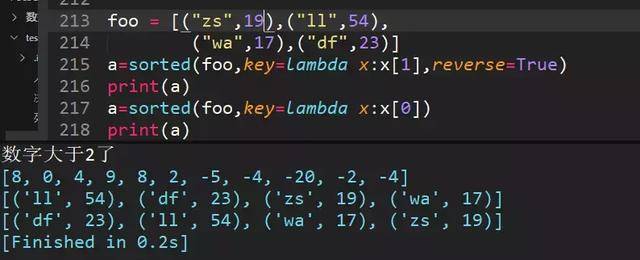
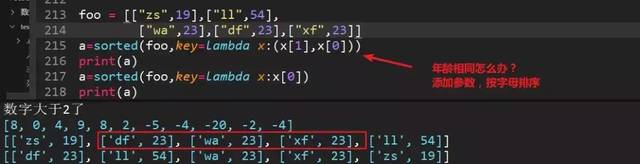
76、列表嵌套列表排序,年龄数字相同怎么办?
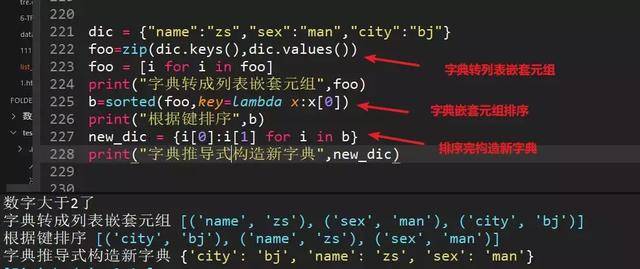
77、根据键对字典排序(方法一,zip函数)
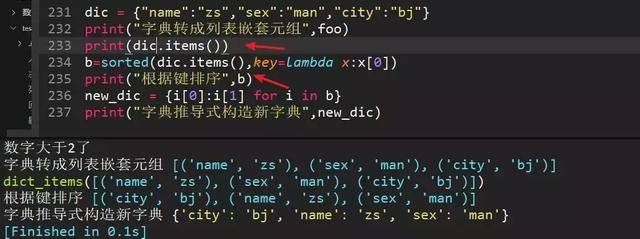
78、根据键对字典排序(方法二,不用zip)
有没有发现dic.items和zip(dic.keys(),dic.values())都是为了构造列表嵌套字典的结构,方便后面用sorted()构造排序规则。
79、列表推导式、字典推导式、生成器
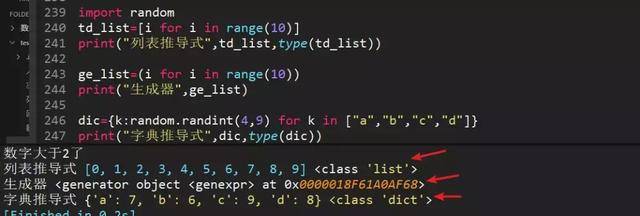
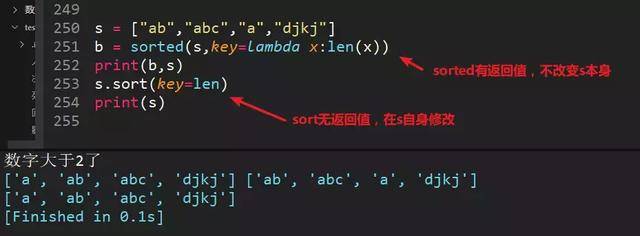
80、最后出一道检验题目,根据字符串长度排序,看排序是否灵活运用
81、举例说明SQL注入和解决办法
当以字符串格式化书写方式的时候,如果用户输入的有;+SQL语句,后面的SQL语句会执行,比如例子中的SQL注入会删除数据库demo。
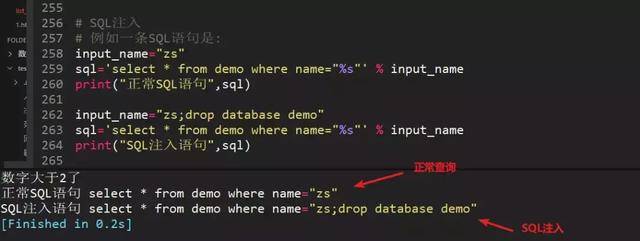
解决方式:通过传参数方式解决SQL注入

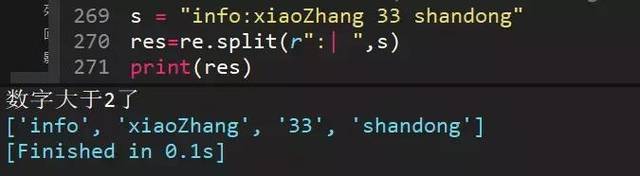
82、s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']
|表示或,根据冒号或者空格切分
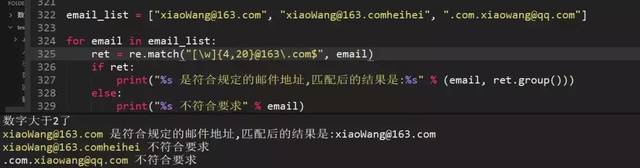
83、正则匹配以163.com结尾的邮箱
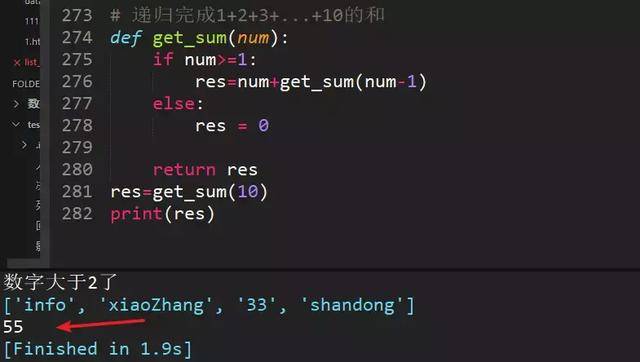
84、递归求和
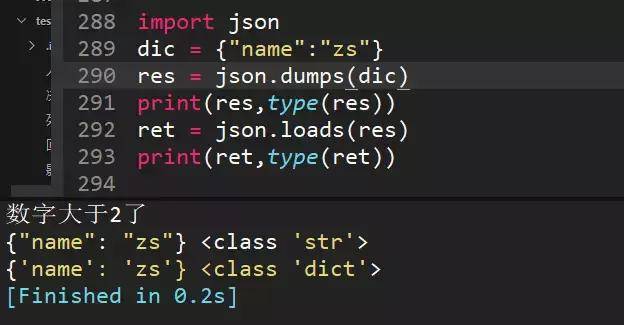
85、python字典和json字符串相互转化方法
json.dumps()字典转json字符串,json.loads()json转字典
86、MyISAM 与 InnoDB 区别
1、InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM就不可以了;
2、MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及安全性较高的应用;
3、InnoDB 支持外键,MyISAM 不支持;
4、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM表中可以和其他字段一起建立联合索引;
5、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重建表。
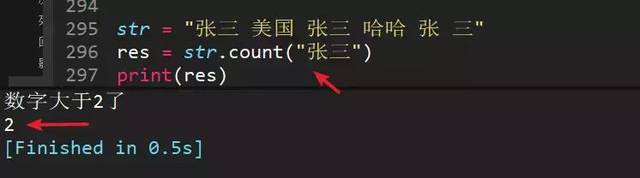
87、统计字符串中某字符出现次数
88、字符串转化大小写
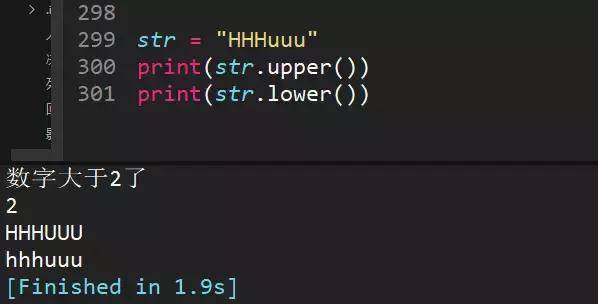
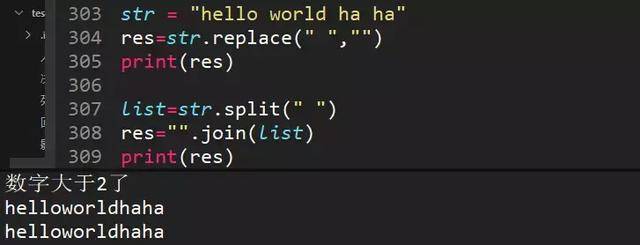
89、用两种方法去空格
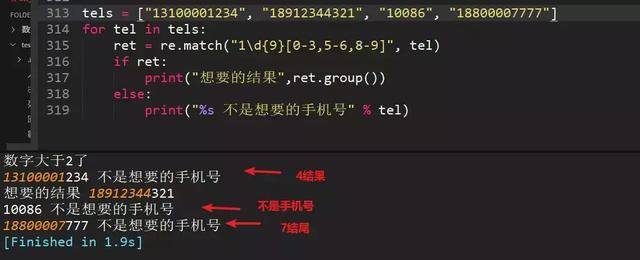
90、正则匹配不是以4和7结尾的手机号
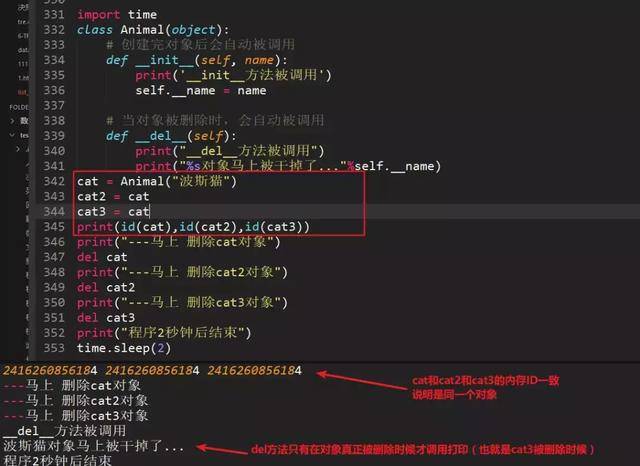
91、简述python引用计数机制
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
引用计数算法
当有1个变量保存了对象的引用时,此对象的引用计数就会加1;
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除。
92、int("1.4"),int(1.4)输出结果?
int("1.4")报错,int(1.4)输出1
93、列举3条以上PEP8编码规范
1、顶级定义之间空两行,比如函数或者类定义。
2、方法定义、类定义与第一个方法之间,都应该空一行。
3、三引号进行注释。
4、使用Pycharm、Eclipse一般使用4个空格来缩进代码。
94、正则表达式匹配第一个URL
findall结果无需加group(),search需要加group()提取
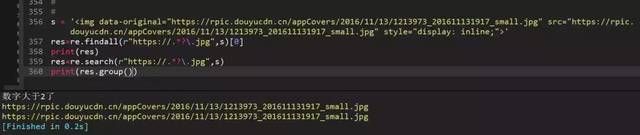
95、正则匹配中文

96、简述乐观锁和悲观锁
悲观锁, 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制,乐观锁适用于多读的应用类型,这样可以提高吞吐量
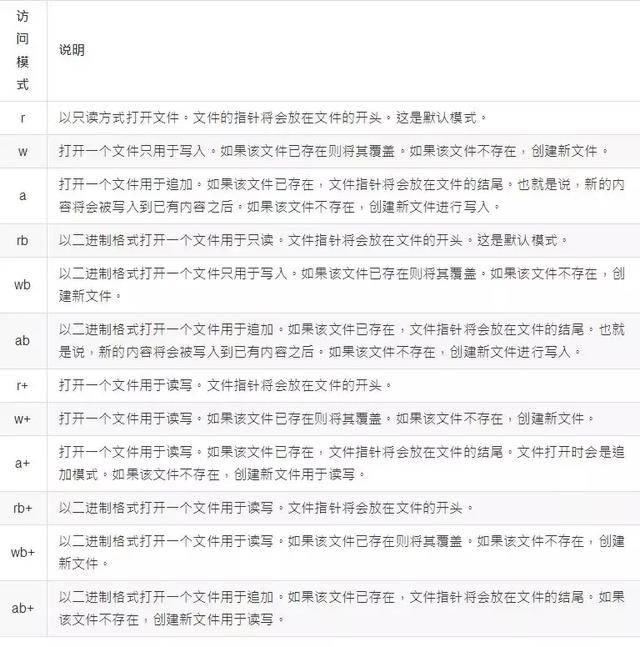
97、r、r+、rb、rb+文件打开模式区别
模式较多,比较下背背记记即可
98、Linux命令重定向 > 和 >>
Linux允许将命令执行结果重定向到一个文件,将本应显示在终端上的内容 输出/追加 到指定文件中。
> 表示输出,会覆盖文件原有的内容
>> 表示追加,会将内容追加到已有文件的末尾
用法示例:
将 echo 输出的信息保存到 1.txt 里echo Hello Python > 1.txt
将 tree 输出的信息追加到 1.txt 文件的末尾tree >> 1.txt
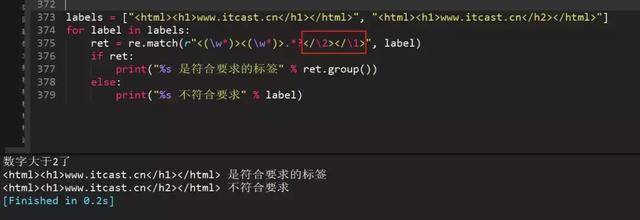
99、正则表达式匹配出
www.itcast.cn
前面的<>和后面的<>是对应的,可以用此方法
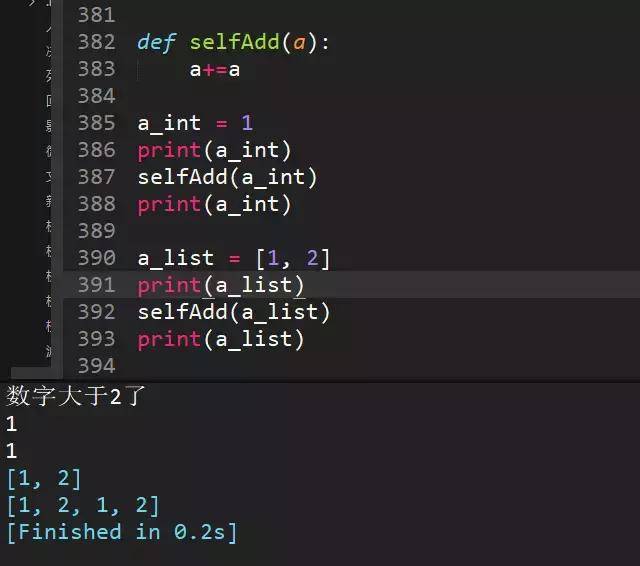
100、python传参数是传值还是传址?
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型(数值型、字符串、元组),因变量不能修改,所以运算不会影响到变量自身;而对于可变类型(列表字典)来说,函数体运算可能会更改传入的参数变量。
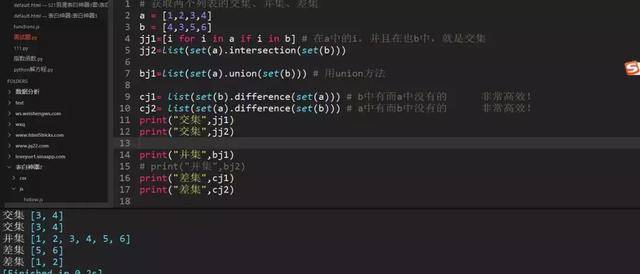
101、求两个列表的交集、差集、并集
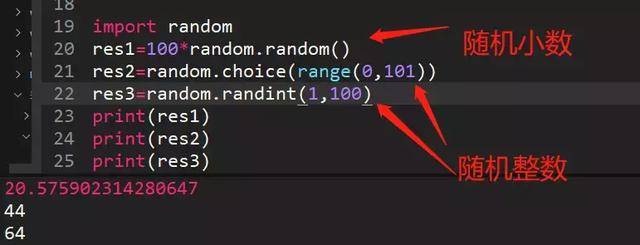
102、生成0-100的随机数
random.random()生成0-1之间的随机小数,所以乘以100
103、lambda匿名函数好处
精简代码,lambda省去了定义函数,map省去了写for循环过程

104、常见的网络传输协议
UDP、TCP、FTP、HTTP、SMTP等等
105、单引号、双引号、三引号用法
1、单引号和双引号没有什么区别,不过单引号不用按shift,打字稍微快一点。表示字符串的时候,单引号里面可以用双引号,而不用转义字符,反之亦然。
'She said:"Yes." ' or "She said: 'Yes.' "
2、但是如果直接用单引号扩住单引号,则需要转义,像这样:
' She said:'Yes.' '
3、三引号可以直接书写多行,通常用于大段,大篇幅的字符串
"""
hello
world
"""
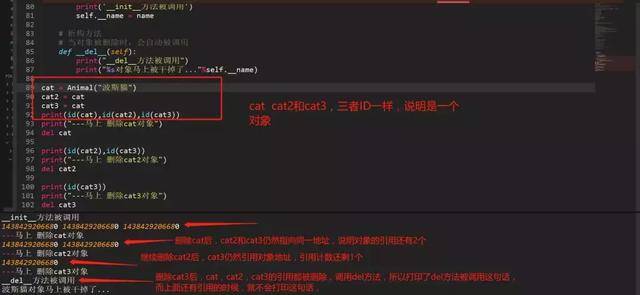
106、python垃圾回收机制
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
引用计数算法
当有1个变量保存了对象的引用时,此对象的引用计数就会加1;
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除。
107、HTTP请求中get和post区别
1、GET请求是通过URL直接请求数据,数据信息可以在URL中直接看到,比如浏览器访问;而POST请求是放在请求头中的,我们是无法直接看到的。
2、GET提交有数据大小的限制,一般是不超过1024个字节,而这种说法也不完全准确,HTTP协议并没有设定URL字节长度的上限,而是浏览器做了些处理,所以长度依据浏览器的不同有所不同;POST请求在HTTP协议中也没有做说明,一般来说是没有设置限制的,但是实际上浏览器也有默认值。总体来说,少量的数据使用GET,大量的数据使用POST。
3、GET请求因为数据参数是暴露在URL中的,所以安全性比较低,比如密码是不能暴露的,就不能使用GET请求;POST请求中,请求参数信息是放在请求头的,所以安全性较高,可以使用。在实际中,涉及到登录操作的时候,尽量使用HTTPS请求,安全性更好。
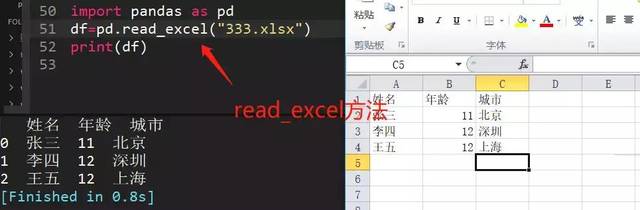
108、python中读取Excel文件的方法
应用数据分析库pandas
109、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立。
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制。
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源。
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃。
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间。
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势。
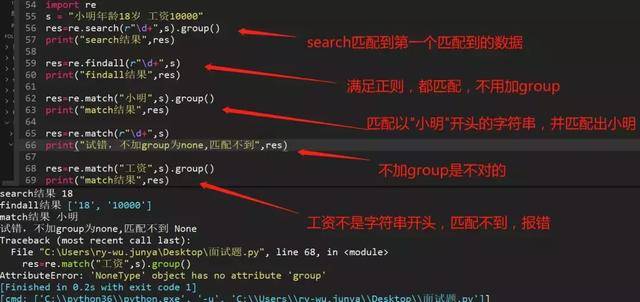
110、python正则中search和match
来源网络,侵权删除














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









