







无人机上目标检测的特点:
1、图像特点
在多数情况下,无人机的拍摄视野很大,包含丰富的视觉内容,虽然它提供了更全面的场景信息。
缺点:
1)但是待检测的目标对象通常在图像中占比较小,且没有足够的检测细节;
2)目标的外观和结构质量都很差,容易与噪声混淆(大视场、小目标引起);
1、遥感图像飞机目标检测与分类算法研究
学术论文,主要内容为遥感图像飞机检测。
难点:由于遥感图像的成像时段以及环境条件不一,可见光遥感平台的分辨率、相机F数、飞行高度、视角等参量各有不同,待检测的飞机目标型号各异的原因,遥感图像飞机目标检测这一任务往往需要考虑复杂多变的背景信息和不稳定的目标特性。
文章贡献:
1)详细描述了数据集制作、数据集划分、指标评价这些基础知识,写文档时可参考;
2)锚点框 k 均值聚类结果可视化,一定程度上反映了聚类效果;
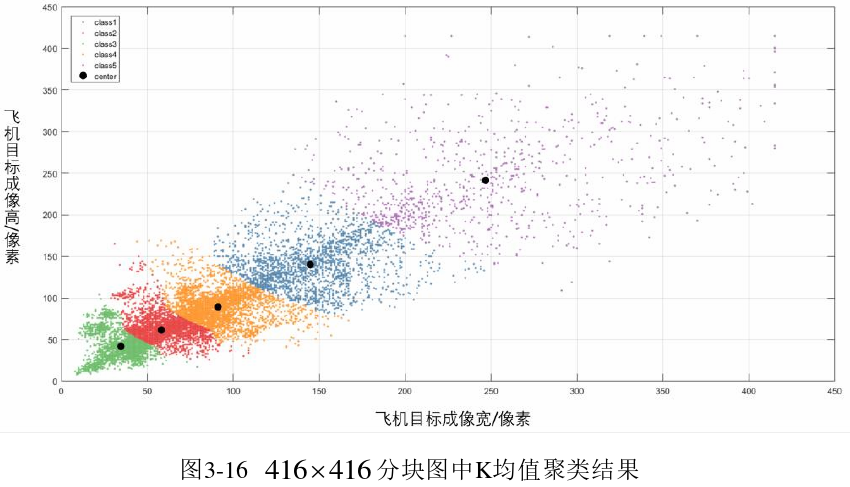
3)实验。
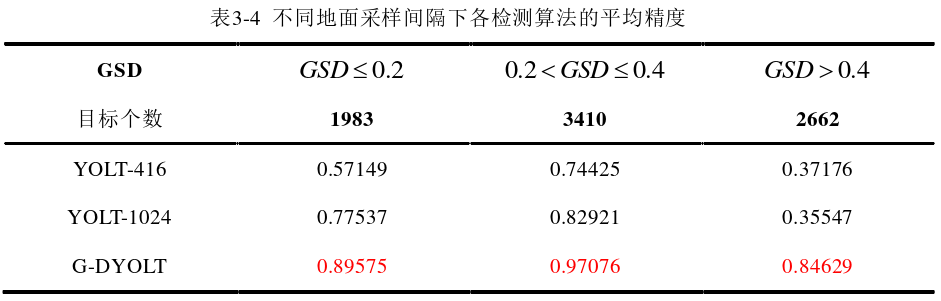
1、不同地面采样间隔下各检测算法的平均精度
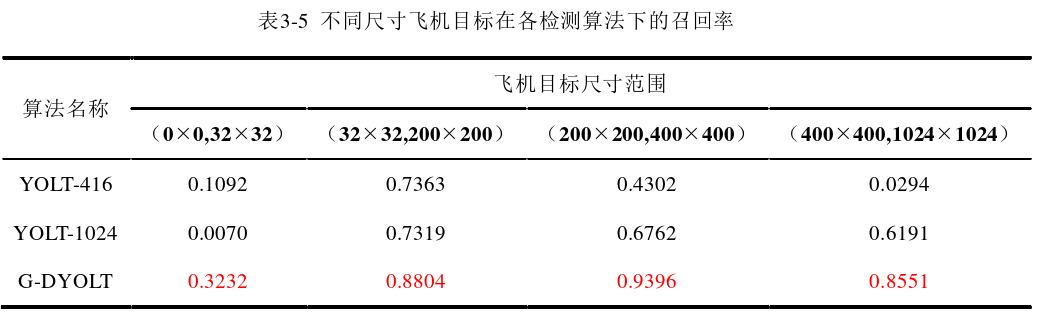
2、目标尺寸对检测性能影响分析
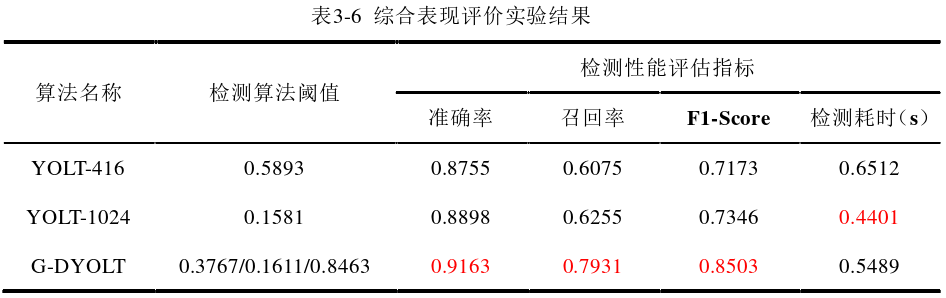
3、算法综合表现
2、YOLOv5与Deep-S...优化的无人机多目标跟踪算法_罗茜
基金项目,主要内容为检测模型更改+跟踪。
模型结构如下:
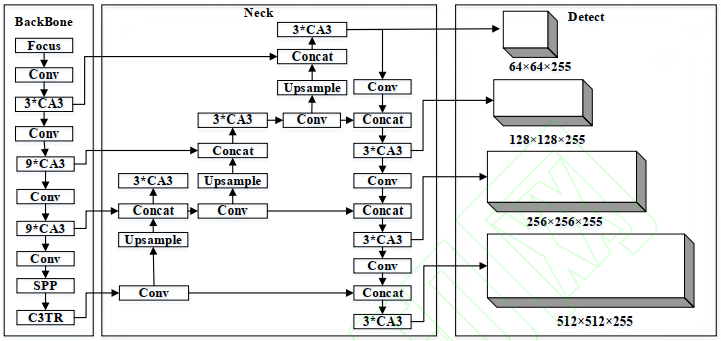
在骨干网络最后一层将原 始 的 BSP ( Bottleneck and CSP ) 替 换 为Transformer[21]结构,利用 Transformer 捕获全局信息和上下文信息并通过其自注意力机制挖掘潜在的图像特征。 Transformer 结构如图 2 中的 C3TR 模块所示,其包含两个子层: multi-head attention layer(多头注意力层)和 MLP(Multilayer Perception,多层感知机)全连接层;子层之间用残差结构连接,外加LayerNorm 和 Dropout 层防止网络过拟合。
![]()
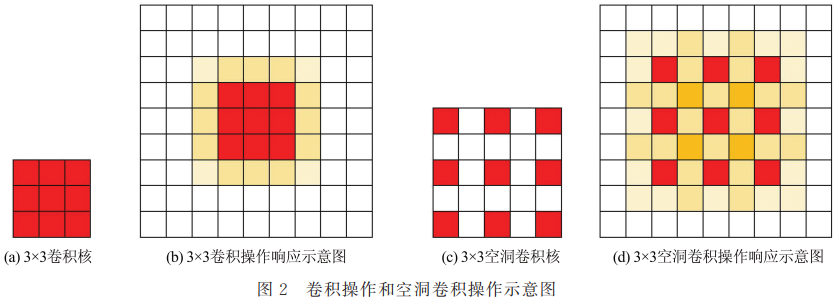
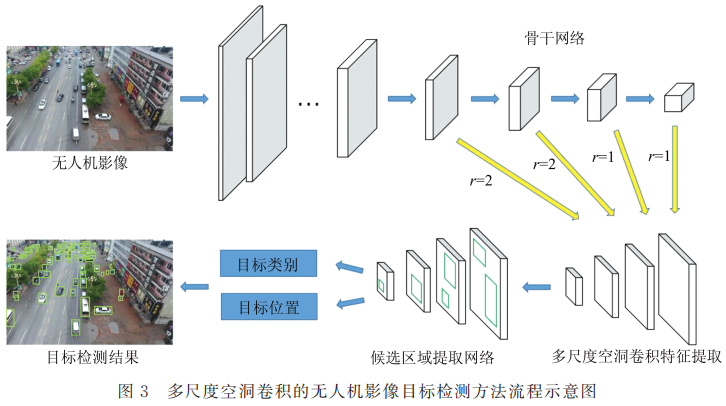
3、多尺度空洞卷积的无人机影像目标检测方法
本文提出了一种多尺度空洞卷积的无人机影像目标检测方法,在现有的目标检测方法的基础上,增加多尺度的空洞卷积模块,加大视野感知域,提高网络对数据分布情况和数据尺寸差异的学习能力,提升网络对无人机影像中多尺度、复杂背景、存在遮挡情况的目标的检测能力。
模型结构:
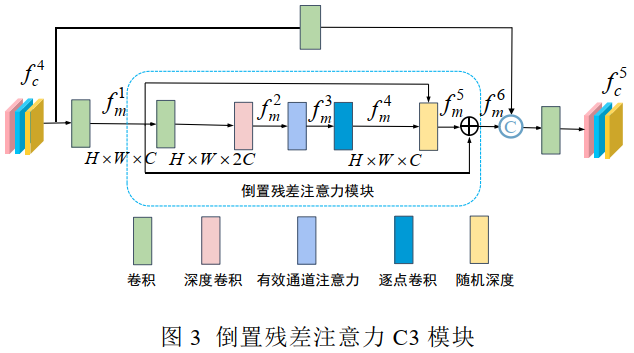
4、基于倒置残差注意力的无人机航拍图像小目标检测
期刊,主要内容:模型结构更改。
1)在主干网络部分嵌入倒置残差模块与倒置残差注意力模块,利用低维向高维的特征信息映射,从而获得丰富的小目标空间信息和深层语义信息,提升小目标的检测精度;
2)融合浅层空间信息和深层语义信息,并生成四个不同感受野的检测头,提升模型对小尺寸目标的识别能力;
模型结构预览:

通过引入本文设计的 IRC3 模块和 IRAC3 模块,提取不同尺度的特征,提高模型对特征的可分辨性,使得特征提取模块能够更有指向性的提取小目标的特征。

5、基于改进 YOLOv4-tiny 的无人机航拍目标检测
期刊,主要内容:设计注意力模块加入yolov4-tny。
引入注意力机制,能够对感兴趣区域的特征数据进行动态权重系数加权,提高网络对重点区域的关注,解决由小目标、部分遮挡目标引起的识别困难问题。
CBAM 结构如图 2 所示,其中通道注意力模块采用并行的方式分别将最大池化和平均池化提取的通道信息经过卷积层压缩过滤并进行融合,最后使用 sigmoid 实现数据归一化从而提高感兴趣通道权重,降低非兴趣通道权重。空间注意力模块则是并行过滤空间信息并融合,再通过卷积提取重要空间信息。两个模块相辅相成,实现感兴趣区域通道和空间信息的提纯。

模型结构中的使用:

6、基于改进 YOLOv4 的自然人群口罩佩戴检测方法
期刊,主要内容:引入协调注意力机制,扩大感受野并提升算法的鲁棒性。
引入协调注意力机制,进而提升主干特征提取网络对于浅层次特征图像位置信息的利用进而更好地捕获小物体——口罩,同时能够丰富浅层次特征图像的语义信息和加强远距离依赖关系,更精准地定位和识别目标区域。
协调注意力机制创新性地将空间位 置 信 息 嵌 入 到 通 道 注 意 力 中,进 而 解决 SE中存在的只考虑内部通道信 息 而 忽 略 位 置 信 息 的 问 题,同 时 也 解决了 CBAM( convolutional block attention module)无法获取 远 距 离 依 赖 关 系 的 问 题,并 且 避 免 引入大的计算开销。
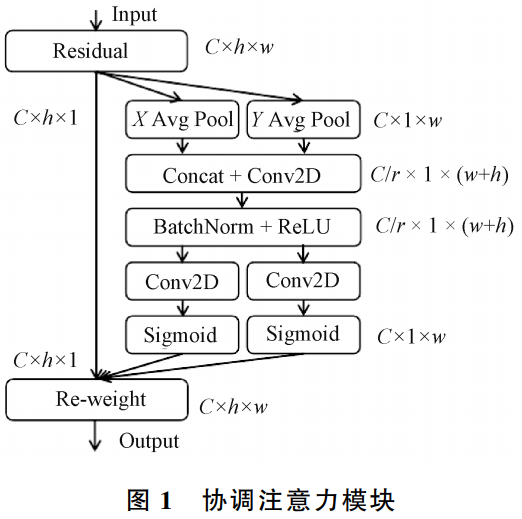
整体结构:
1、将空间金字塔池化层 SPP 前后的卷积层数均提升为 5 层,提高对小目标的检出;
2、L3 及 L4 输出至加强特征提取网络之前的卷积层数进行提升,由原先的 1 层卷积提升为 3 层卷积。
这样做可进一步提升整体网络的容量及深度,提取到更深层次的特征,进一步扩大感受野,同时提升语义表征能力以及算法的鲁棒性。

结果:
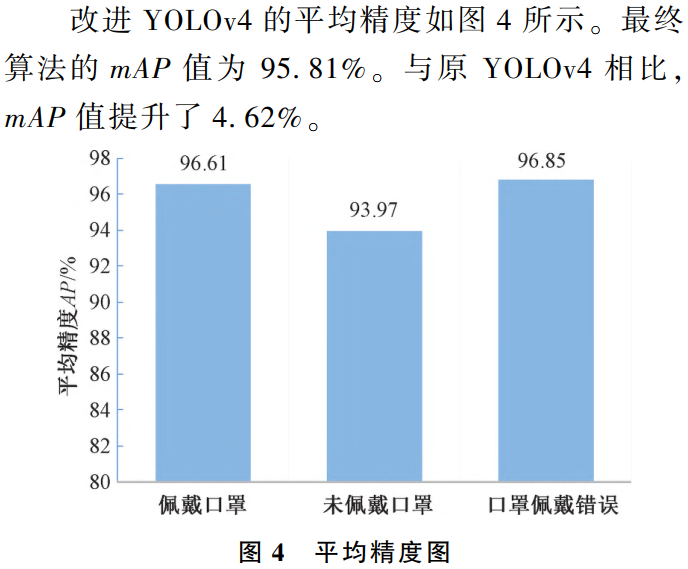
7、基于改进 YOLOv4 算法的室内场景目标检测
期刊,主要工作:模型结构改进。

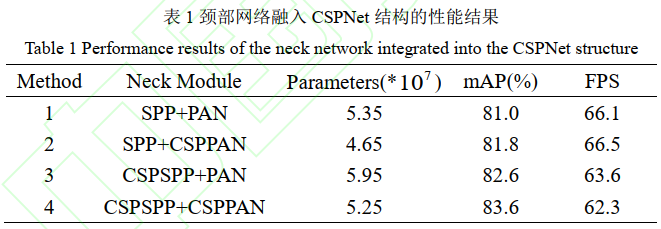
1)对于颈部网络,将 CSPNet 结构思想运用到 SPP 和 PANet 模块中,分别记为 CSPSPP和 CSPPAN;
2)对于颈部和主干网络,同时修改 CSPNet 结构中的残差模块,将残差模块中的3×3 标准卷积替换为深度可分离卷积(Depthwise separable convolution, DS),改进后,主干网络记为 DS-CSPDarknet53,颈部网络中的 CSPPAN 模块记为 DS-CSPPAN。

CSPNet 结构,形成的 CSPDraknet53网络既减少了网络参数,又提高了检测精度。将 CSPNet结构体系融入 SPP 模块和 PANet 中的连续卷积模块中,以此提高目标检测效果。
SPP 模块改进后的结构图,在融合多尺度特征前,将网络分成两个部分,一部分特征经过捷径连接,直接与 SPP 融合后的特征合并,这一操作减少了 40%的计算量。图 5为 PANet 中连续卷积模块改进后的结构图,原始 YOLOv4 算法中,深层特征与浅层特征张量拼接后会经历 5 个连续卷积层,考虑梯度消失和梯度爆炸的问题,将连续卷积层改为两个连续的残差块,再通过捷径连接将这两个残差块包围起来,构成 CSPNet 结构。
对比实验:
1)颈部网络 CSPNet 结构化
2)深度可分离卷积
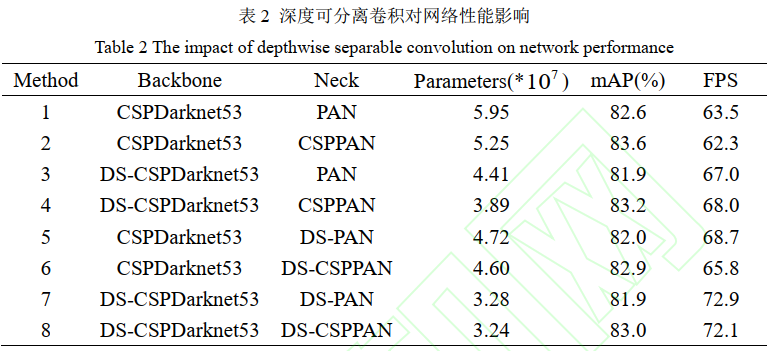
这种轻量化的设计使检测速度(FPS)提升了近 10 个点,代价仅为 mAP 值降低了 0.6%。
8、基于改进 YOLOv5s 的无人机图像实时目标检测
期刊,主要工作:模型特征融合。
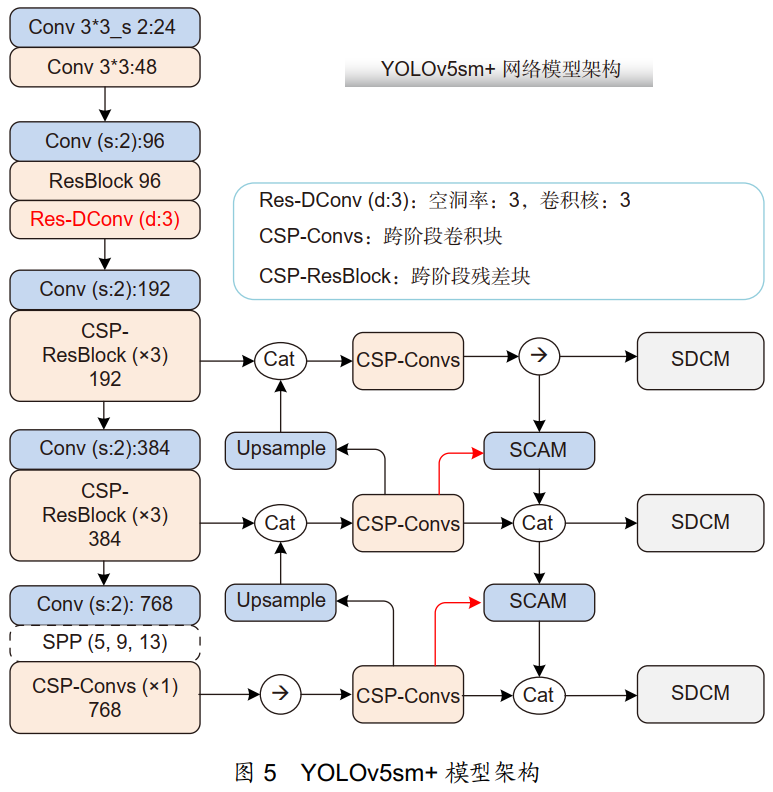
本文充分利用 YOLOv5s 的优势解决了其深度宽度不均衡、分类精度不足等问题,有效提高了无人机场景下小模型实时检测的精度,主要创新点包括以下几点:
1) 为解决无人机图像目标尺度差异大、小目标检测率低的问题,分析了深度模型中模型深度和宽度对于无人机图像检测的性能增益,提出了可显著提高感受野的混合残差空洞卷积模块,并结合无人机图像特点对 YOLOv5s 模型进行改进,设计了 YOLOv5sm模型;
2) 为进一步优化改进模型的实时性与识别率,设计了一种基于目标局部部件特征信息的注意力机制,提出了一种跨阶段注意力特征融合模块 SCAM;
3) 考虑到目标检测任务中位置回归与分类任务之间的矛盾,通过对 YOLO 检测头进行改进,单独对分类分支进行特征后处理,实现位置回归与分类任务的隔离解耦。
YOLOv5sm 骨干网络:
无人机图像小目标众多,分辨率高,一味增加深度将严重降低算法实时性。而 YOLOv5s 模型低级特征映射少、感受野小,导致各大目标的召回率、精度偏低,故需针对无人机图像对网络进行调整。
1)Res-DConv模块
为了解决低层特征感受野较小的问题,本文提出了混合残差空洞卷积模块 (Res-DConv),通过有效提高感受野来增强背景信息对回归、分类的指导,并避免降低局部细节信息损失,提高回归的精度。
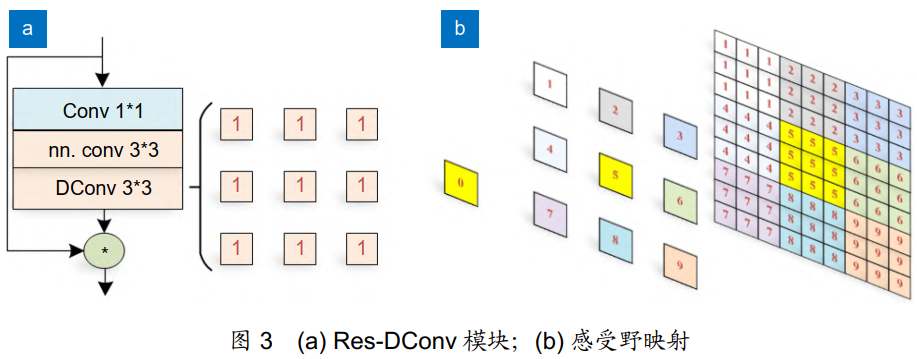
2)Res-DConv模块(Neck层,分类提高)
主要思想是基于低分辨率特征图的空间注意力对高分辨率特征图进行加权筛选,用以增强目标的部件特征,提高特征利用率,增强检测器的分类性能。本文称之为跨阶段注意力模块 (stage crossed attention module, SCAM)。
SCAM 模块可取代下采样模块:首先低分辨率特征经过最大池化和均值池化,连接后经过混合空洞卷积后得到注意力掩码图像 Mask;然后对高分辨率特征按照尺度转通道进行处理 (下转换) 结合 Mask掩码对高分辨率特征进行加权,后经过通道注意力[24]调整通道得到待融合特征;最后将高阶特征与处理后的低阶特征按维度级联融合得到融合特征。
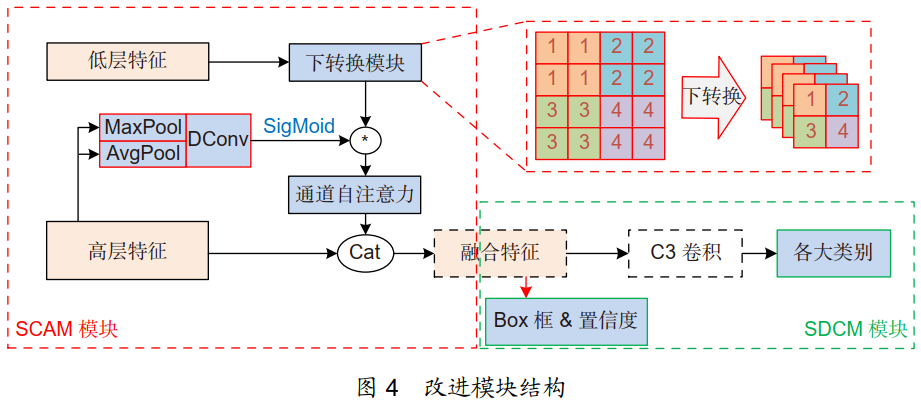
3)整体模型结构















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











