







什么是稠密特征?
本赛题中利用 word2vec 变换得到的特征维度设定为 n*64,因此得到的稠密特征也是一个 n*64 的矩阵。稠密的特性体现在,64 个维度上每一个维度都存在有意义的值,需要进行计算。如下图:


稠密特征的特点是保留了尽可能多的信息,但是相应的也增加了很多的计算量,大大提高了计算的时间复杂度。
如何得到稠密特征?
本赛题中使用 word2vec 和 deepwalk 两种模型来获得稠密特征。
word2vec 旨在利用一个简单的神经网络模型,对特征按照神经元个数进行矩阵分解,得到的中间矩阵就是我们想要的稠密特征。
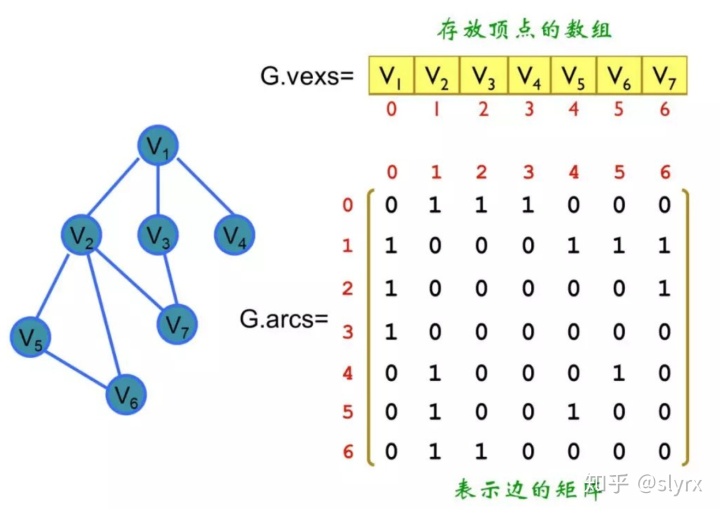
deepwalk 是一个图模型,旨在表达节点之间的点和边的关系。可以得到如下图的矩阵:
代码
word2vec
model = Word2Vec(sentence, size=L, window=10, min_count=1, workers=10,iter=10)deepwalk
# 构建图
dic={}
for item in log[[f1,f2]].values:
try:
str(int(item[1]))
str(int(item[0]))
except:
continue
try:
dic['item_'+str(int(item[1]))].add('user_'+str(int(item[0])))
except:
dic['item_'+str(int(item[1]))]=set(['user_'+str(int(item[0]))])
try:
dic['user_'+str(int(item[0]))].add('item_'+str(int(item[1])))
except:
dic['user_'+str(int(item[0]))]=set(['item_'+str(int(item[1]))])
# 构建路径
path_length=10
sentences=[]
length=[]
for key in dic:
sentence=[key]
while len(sentence)!=path_length:
key=dic[sentence[-1]][random.randint(0,dic_cont[sentence[-1]]-1)]
if len(sentence)>=2 and key == sentence[-2]:
break
else:
sentence.append(key)
sentences.append(sentence)
length.append(len(sentence))
if len(sentences)%100000==0:
print(len(sentences))
# 使用 word2vec 训练Deepwalk模型
random.shuffle(sentences)
model = Word2Vec(sentences, size=L, window=4,min_count=1,sg=1, workers=10,iter=20)
# 对模型进行输出
out_df=pd.DataFrame(w2v)
赛题里是如何使用稠密特征的?
本赛题是直接将稠密特征放入 MLP 中计算的
if hparams.dense_features is not None:
feed_dic[self.dense_features]=train_dense_features[idx*hparams.batch_size:
min((idx+1)*hparams.batch_size,len(train))]
...
loss,_,norm=sess.run([self.score,self.update,self.grad_norm],feed_dict=feed_dic)本赛题中涉及到到稠密特征?
- uid_w2v_embedding_aid_64_1
- uid_w2v_embedding_aid_64_2
- ...
- uid_w2v_embedding_aid_64_64
- uid_aid_aid_deepwalk_embedding_64_1
- uid_aid_aid_deepwalk_embedding_64_2
- ...
- uid_aid_aid_deepwalk_embedding_64_64
- periods_on_1
- periods_on_2
- ...
- periods_on_48















 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









